深度学习论文笔记之(一)HED边缘检测
Abstract
- 创新点: 用cnn做edge detection (HED),端到端
- 解决两个问题:
1)holistic(整体的) image training and prediction;
2)multi-scale and multi-level feature learning; - 特点 :
- 端到端:image-to-image
- 基于FCN和VGG 改进
- 通过多个side output输出不同scale的边缘,然后通过一个训练的权重融合函数得到最终的边缘输出。可以solve edge 和物体boundaries的ambiguity
- 工程主页:https://github.com/s9xie/hed
1 Introduction
典型的边缘检测工作:
I: early pioneering methods Sobel detector、Canny detector
II: information theory Statistical Edges [22], Pb [28], and gPb [1];
III:learning-based methods that remain reliant on features of human design, such as BEL [5], Multi-scale [30], Sketch Tokens [24], and Structured Edges [6]
IV:cnn N4-Fields [10], Deep- Contour [34], DeepEdge [2], and CSCNN [19].
We tackles two critical issues: (1) holistic image training and prediction, inspired by fully convolutional neural networks [26], for image-to-image classification (the system takes an image as input, and directly produces the edge map image as output); and (2) nested multi-scale feature learning, inspired by deeply-supervised nets [23], that performs deep layer supervision to “guide” early classification results.
2 Holistically-Nested Edge Detection
A recent wave of work using CNN for patch-based edge prediction [10, 34, 2, 19]基于三个方面:
(1)自动feature learning
(2)multi-scale response fusion
(3)possible engagement of different levels of visual perception
本文加了 deep supervision,基于全卷积网络(与输入尺寸无关)!
和 patch-based CNN edge detection methods相比,我们的方法一是速度快,二是性能好,主要体现在:
(1)FCN-like image-to-image training allows us to simultaneously train on a significantly larger amount of samples
(2)deep supervision in our model guides the learning of more transparent features
(3)interpolating the side outputs in the end-to-end learning encourages coherent contributions from each layer
2.1 Existing multiscale and multilevel NN
hierarchical learning
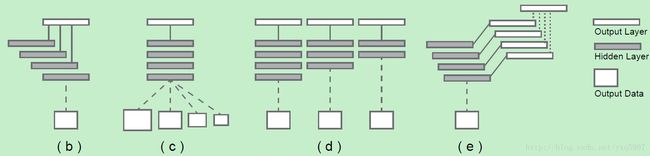
由于multi-scale在不同情况下表示的含义可能不同,将其分为四类:
multi-stream learning[3,29],
The multiple (parallel) network streams have different parameter numbers and receptive field sizes, corresponding to multiple scales,输入是同时输进去,经过不同路的network之后,再连接到一个global out layer得到输出。skip-net learning [26, 14, 2, 33, 10] ,
特点:只有一路network,从不同层提取信息连接到输出
1,2的共同特点是只有一个输出loss函数,并只能得到一个预测结果。a single model running on multiple inputs , 就是不同尺寸的图片输入,One notable example is the tied-weight pyramid networks [8].。
training of independent networks. 训练多个不同的网络(深度不同且loss也不同)
,得到多个不同的输出,缺点显然是资源消耗太大。下面介绍 Holistically-nested networks:由于已有的方法存在很大的冗余,本结构和deeply-supervised net[23] 很像,其中[23] shows that hidden layer supervision can improve both optimization and generalization for image classification tasks.
2.2 公式
训练阶段:
由于在ground-truth中,90%以上的像素点为非edge,因此极度不对称(biased)。针对这种biased sampling,文献[19] 引入cost-sensitive loss function,并增加额外的additional trade-off parameters。而HED中采用一种更简单的方法来保证正负样本的loss balance,即引入一个像素级的class-balancing weight β
则损失函数为class-balanced cross-entropy loss function:

为了利用side-output的预测结果,我们增加一层weighted-fusion layer
fusion layer 的损失函数为:
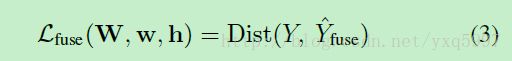
最终的目标函数为:
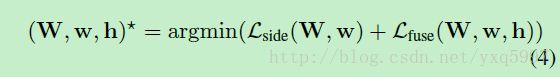
测试阶段:
给定图片X,我们从side-output layer和weighted-fusion layer同时获得边缘预测结果
最终的输出就是将这些结果进行一个聚合。
3 网络架构
3.1 Trimmed network for edge detection
基于VGG,做了以下改动:
1)将side output layer 与每个stage(理解为每一组卷积池化)的最后一层卷积层相连,也就是conv1 2, conv2 2, conv3 3, conv4 3, conv5 3.这些卷积层的感知野尺寸与对应的side-output layer完全相同。
2)去掉了VGG的最后一个stage,也就是最后一个池化和后面所有的全连接层。
这是因为全连接层太好耗资源(即使转换成conv也很费资源)
下面的表格是HED的网络配置
与FCN-网络对比:
直接替换FCN-8S中的loss为交叉熵的性能不好 ,FCN-2s network that adds additional links fromthe pool1 and pool2 layers.
什么是deep supervision呢?在这里指的是来自side-output 的结果
The “fusion-output without deep supervision” result is learned w.r.t Eqn. 3. The “fusion-output with deep supervision” result is learned w.r.t. to Eqn. 4
关于The role of deep supervision:
deep supervision terms (specifically, ℓside(W,w(m)):
每一层都看做是一个独立的network的输出(在不同的尺度上)
实验表明,仅仅用weighted-fusion supervision训练,在高层的side output上很多关键的边缘信息都丢失了。
4 实验
4.1 实现
基于Caffe,FCN[26]和DSN[23]的基础上,用VGG进行初始化。
调参:依据[6]在的评价策略
mini-batch size (10),
learning rate (1e-6),
loss-weight αm for each side-output layer (1),
momentum (0.9),
initialization of the nested filters (0),
initialization of the fusion layer weights (1/5),
weight decay (0.0002),
number of training iterations (10,000; divide learning rate by 10 after 5,000).
由于在每个side-output layer,我们将每个输出都resize到原始尺寸和ground truth对比,在高层输出,由于经过了较大的stride,此时只剩下一些大的边缘,而精细的边缘已经检测不出来了,而此时的ground truth仍然包含了很多精细的边缘(甚至有的是噪声),这导致了一个收敛困难的问题(在高层梯度爆炸)。因此作者只选取那些被至少三人标注为边缘的像素作为positive label
* Data augmentation*
rotate the images to 16 different angles and crop the largest rectangle in the rotated image; we also flip the image at each angle, leading to an augmented training set that is a factor of 32 larger than the unaugmented set. During testing we operate on an input image at its original size.
* In-network bilinear interpolation*
反卷积插值[26]的方式并没有明显的改善。
4.2 Dataset
Berkeley Segmentation Dataset and Benchmark (BSDS 500) [1]
相关博客:
http://blog.csdn.net/u012905422/article/details/52782615
http://www.jianshu.com/p/2b9fefbc6754
参考文献:
[3] P. Buyssens, A. Elmoataz, and O. L´ezoray. Multiscale convolutional neural networks for vision–based classification of cells. In ACCV. 2013
[6] P. Doll´ar and C. L. Zitnick. Fast edge detection using structured forests. PAMI, 2015.
[23] C.-Y. Lee, S. Xie, P. Gallagher, Z. Zhang, and Z. Tu. Deeplysupervised nets. In AISTATS, 2015.
[26] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015.