SpringBoot+Kafka+ELK集成日志采集可视化框架
目录
1.前言
2.实践代码(以下操作都在WIN7系统)
2.1环境背景
2.2环境搭建
2.2.1启动zookeeper(因为kafka依赖zookeeper)
2.2.2启动kafka
2.2.3启动elasticsearch
2.2.4启动logstash
2.2.5启动kibana
2.2.6启动springboot项目
3.总结
1.前言
很久没有写技术博客了,最近自己搭建了一套SpringCloud框架(github地址:https://github.com/githubyy602/SpringCloudDemo),并研究了一下ELK企业级日志框架,下面和大家分享一下搭建和实践过程中的一些坑点和心得。
2.实践代码(以下操作都在WIN7系统)
2.1环境背景
①SpringBoot使用的是1.5.10版本,相关版本先粘一下
UTF-8
UTF-8
1.8
Dalston SR1
1.4.7.RELEASE
1.5.10.RELEASE
1.0.4
2.0.7
8.0.18
②使用到的kafka和ELK软件版本(注意elk最好使用同一版本,因为有版本差异问题):
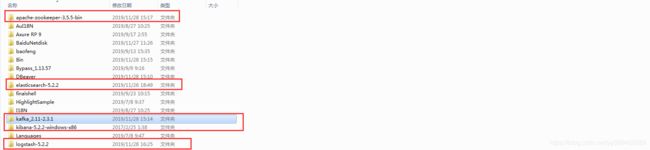
③pom依赖
org.springframework.cloud
spring-cloud-starter-netflix-eureka-client
${spring.cloud.netflix.version}
org.springframework.boot
spring-boot-starter-web
${spring.boot.version}
org.springframework.cloud
spring-cloud-starter-feign
${spring.cloud.netflix.version}
org.springframework.cloud
spring-cloud-starter-netflix-hystrix
${spring.cloud.netflix.version}
com.ctrip.framework.apollo
apollo-client
1.1.0
com.ctrip.framework.apollo
apollo-core
1.1.0
com.github.danielwegener
logback-kafka-appender
0.2.0-RC1
ch.qos.logback
logback-classic
1.2.3
runtime
ch.qos.logback
logback-core
1.2.3
org.springframework.kafka
spring-kafka
net.logstash.logback
logstash-logback-encoder
4.11
2.2环境搭建
2.2.1启动zookeeper(因为kafka依赖zookeeper)
进入zookeeper安装目录conf目录,将zoo_sample.cfg文件拷贝在当前目录,改名为zoo.cfg(里面的配置可以自行调整,我此次没有调整,使用默认设置)。再进入bin目录下,点击zkServer.cmd启动。
2.2.2启动kafka
进入kafka安装目录,在config目录下,有一个server.properties。此处是关于kafka-server启动的使用到的配置(也可以自行调整),我主要调整了日志路径位置和添加了Topic删除设置:
log.dirs=E:/springcloud-log/kafka-log
#设置可以删除topic,否则只是逻辑删除,不是真正意义删除
delete.topic.enable=true然后通过通过cmd命令:kafka-server-start.bat ..\..\conf\server.properties 启动kafka服务,默认端口9092
启动后还需要创建主题topic,使用命令kafka-topics.bat --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --topic testlog(testlog是topic名称,后面会logstash和logback.xml文件会用到)。
※此处重点讲下删除topic,因为删除kafka可能会提示为标记删除,并没有真正删除,并且我就是因为删除topic不完全,导致后续kafka启动有问题。在没有彻底删除topic之后,大家可以到zookeeper配置文件指定的日志存放目录下删除zookeeper日志,以及删除掉kafka指定日志目录的全部文件,再重启zookeeper和kafka即可。但需要重新创建topic。
另外贴一下删除和查看命令:
删除Topic:
kafka-topics.bat --delete --zookeeper 127.0.0.1 -topic test-channel
查看Topic:
kafka-topics.bat --list --zookeeper localhost:2181
2.2.3启动elasticsearch
直接进入bin目录下,点击elasticsearch.bat启动即可。在config目录下通过elasticsearch.yml可以设置相关配置(我本次使用默认内容)。
2.2.4启动logstash
在启动logstash之前,需要先在根目录下(或其他目录)创建一个配置文件,我的名为core.conf,配置文件的内容如下:
input {
kafka {
#此处是kafka的ip和端口(千万不要写成zookeeper的ip端口,否则无法收集到日志)
bootstrap_servers => "localhost:9092"
#此处是我前面提到的topic名称
topics => ["testlog"]
auto_offset_reset => "latest"
}
}
output {
elasticsearch {
#es的Ip和端口
hosts => ["localhost:9200"]
}
}然后通过在bin\windows目录下,通过命令logstash.bat -f ..\core.conf --config.reload.automatic启动logstash即可。(--config.reload.automatic可以是配置文件在修改后立即重新加载生效)。上面的配置文件是使用kafka作为入口,收集日志到logstash内,然后再写入到es中,logstash相当一个中间运输管道。其实也可以使用logstash自带的TCP模式接受输入的日志文件,在这里也给大家粘一下相关配置:
input {
tcp {
host => "127.0.0.1"
port => 9100
mode => "server"
tags => ["tags"]
codec => json_lines
}
}
output {
stdout { codec => rubydebug }
#输出到es
elasticsearch { hosts => "127.0.0.1:9200"
}但是为什么使用kafka接收日志呢,是为了减少logstash对于日志进入时的压力。kafka的特性使用过的人应该都清楚,拥有这10W级别每秒的单机吞吐量,所以很适合作为数据来源缓冲区。
2.2.5启动kibana
直接进入kibana的下载安装目录,进入bin目录点击启动kibana.bat即可。在config目录中,有一个配置文件,里面有如下两行配置:
#kibana启动后的端口号
server.port: 5601
#连接的es的端口和ip
elasticsearch.url: "http://localhost:9200"2.2.6启动springboot项目
在启动自己的springboot项目即可,我这边是springcloud框架搭建的项目,下面贴一下logback-spring.xml文件的配置:
kafka-log-test
%d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%n
${logDir}/${logName}.log
${logDir}/history/test_log.%d{yyyy-MM-dd}.rar
30
%d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%n
%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n
testlog
bootstrap.servers=localhost:9092
acks=0
linger.ms=1000
max.block.ms=0
client.id=0
在项目中,可以自行添加打印的日志,我的打印代码如下:
@RestController
public class UserController {
private Logger logger = LoggerFactory.getLogger(this.getClass());
//apollo上的配置
@Value("${apollo.config.name}")
private String apolloConfigName;
@Resource
private IUserService userService;
@RequestMapping(value = "/user/getUsers")
public String getUsers(){
return userService.getUserInfos();
}
@RequestMapping(value = "/user/getUserName")
public String getUserName(){
return "Test for zuul, i'm is user1";
}
@RequestMapping(value = "/user/getUserNameFromConfig")
public String getUserNameFromConfig(){
logger.warn("==============测试日志,很长很长很长很长很长很长很长很长很长很长很长很长很长很长很长很长======");
return "Hello , my name is " + apolloConfigName;
}
}启动项目之后,请求一下自己的接口,然后进入的kibana可视化界面:
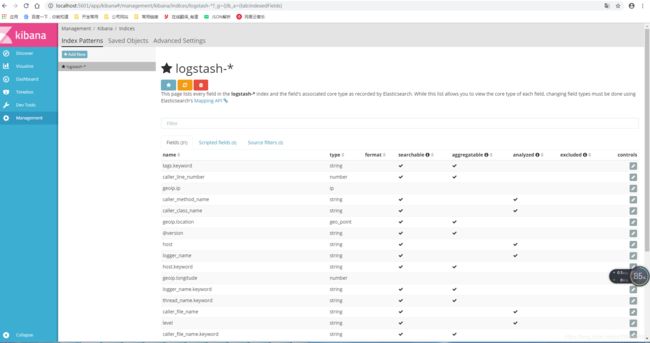
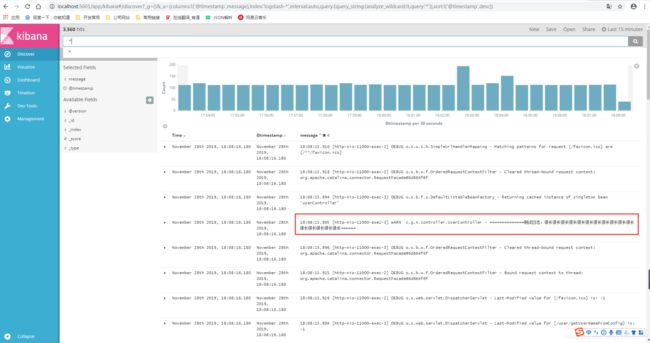
刚开始进来的时候,可能会提示你需要添加索引,但是logstash-*是默认的索引,所以在management的Index Patterns标签页中直接点击Create即可。点击Discover即可看到刚才调用接口所打印的日志,我的日志如下:
3.总结
我本次搭建这套框架差不多用了一天半的时间,中间遇到许多坑点。比如:
1.pom文件中的依赖冲突,如spring-boot-starter-actuator依赖所包含的logback-core因低版本,其中有一个Encoder类没有 encode方法报错,后来我是暂时去除该依赖,自己引入了相关依赖解决的。其实应该可以通过maven的exclusions去除相关冲突依赖即可。
2.logstash的配置文件内容,因熟悉其内容字段含义和内容格式,导致过程中多次获取不到日志。后来百度查到logstash2和5版本的配置有很大的差异,大家需要注意。
3.还有就是整个框架搭建完成后,全部启动会发现kibana中并没有日志显示。后来一步步慢慢分析,先使用logstash自带的tcp方式与logback整合,收集日志,发现是可以引入到es中并在kibana中显示。于是推断是logback和kafka整合出了问题。所以只能从kafka入手,先看了我存放日志文件的目录:
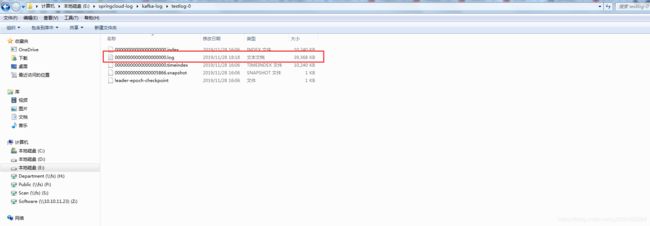
发现这个文件中大小一直是0kb,由此可见项目的日志根本没有收集到kafka中。检查了logback中的topic配置无误,然后又检查了kafka的topic列表,最终通过删除所有原先的topic和相关日志,重新创建解决了这个kafka收集项目日志的问题。但最终发现,日志还是没有通过logstash进入到es中,接着继续排查,发现是logstash的配置文件问题。(这一块真的把我坑惨了,框架整体搭建完,在这一步耗了一般的时间)
4.我此次只是将框架搭建成功并启动,但还有很多地方不够完善。如kafka集群,zookeeper集群配置等,还有es中创建索引等等,后续将会继续完善更新。
最后希望能帮到各位也在钻研学习的小伙伴,同事希望大佬不吝赐教。。。
并分享几个过程中学习和参考的帖子链接:
https://www.clxz.top/2019/03/30/1124/
https://www.cnblogs.com/niechen/p/10149962.html