python内存管理机制
python事先分配好的缓冲区
python解释器会事先分配一些缓冲区,这些缓冲区保存一些固定值,例如[-5,256],在一次程序执行过程中,这些值的地址是固定的,是静态缓冲区。
但是每次重新运行程序,解释器会重新分配内存,所以每次运行程序的地址会不同。
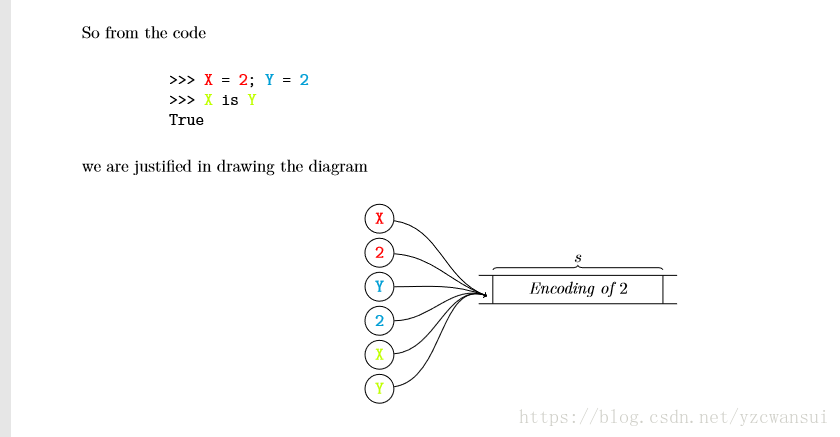
可以看出所有的引用都指向一片内存
再给出一个例子:

这里的1,0地址是不变的,变的是X,Y的引用对象,如下图:

string类型,它也有自己的缓冲区,固定的是256个ASCII码字符。
###python重复利用的缓冲区
在python中,除了事先分配好的缓冲区,还会有一些重复利用的动态缓冲区,配合垃圾回收机制,自动将没用的对象清除出缓冲区,以便新的变量可以有内存可用。

从上图可以看出在X大于256之后,保存数字的缓冲区地址在动态变换,但是也有例外的情况:

对于这种情况,应该是编译器对语句进行了优化,因为X=258,然后又判断X是不是258,所以编译器直接进行了跳步,将两句并一句,在编译阶段直接给出了答案。
###容器类的内存分配
Python的容器类对象(表,词典,集合,等)保存的是各个元素的引用,而不是元素本身。
给出一个简单的例子:

根据上图可以看出X,Y的地址并不是X[0],Y[0]的地址,而X[0],Y[0]的地址才是0和1所保存的地址。
对X,Y进行简单的交换,可以得到:
![]()
对比上一张图,可以发现Y其实就是X的引用,而X寻找了一片新的内存空间,并没有用Y的地址。其关系如下:

在python中,容器类型即使完全一样也可能存储在不同的地址当中,如图所示:

在图中,打印了5次id,打印出来三个不同的id值。
![]()
并且用is判断引用是否相同,给出了False的结果。
再看下边的例子:

这个例子中通过getrefcount函数看到,X,Y,Z各被引用了两次,也就意味着X,Y,Z对应着不同的地址。尽管X,Y,Z的值都是[0,1],但是每一个都有不同的地址,互不干扰。而单独调用sys.getrefcount([0, 1])发现仅有一次调用记录,也就是getrefcount函数调用的。这说明单独调用[0, 1]会再生成一片空间单独存放该对象,不会去引用X,Y或Z。
python的动态内存管理机制导致动态申请的内存可能刚申请下来,就被当作垃圾回收。给出一个例子:

如图所示,在打印出[0,1]的id之后,该列表就被回收了,进而将地址让给了[2,3]继续使用。
容器类嵌套的地址分布问题
容器类嵌套的地址分布会出现多种可能性
- 使用进行扩展
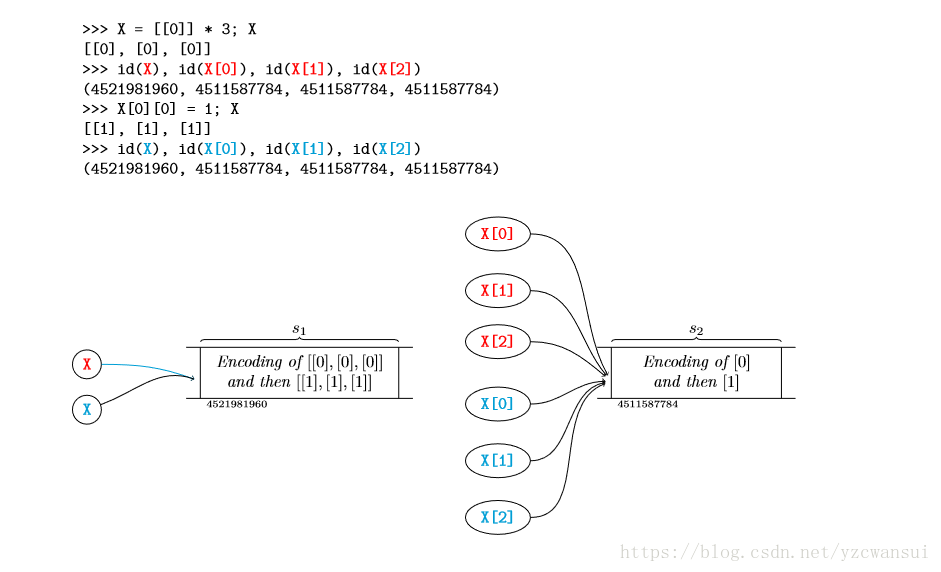
可以发现,用进行扩展出来的元素地址都是相同的,可以大致猜出 * 的行为,就是进行浅拷贝,将引用复制成三分,但是这也会造成问题,当给其中一个赋值的时候,其他使用 * 扩展出来的元素也会相应的跟着发生变换。使用生成器可以避免该问题。
这种情况只会在列表嵌套的情况下发生,如果列表没有嵌套的话,赋值的时候会重新给被赋值的元素开辟一片新的空间
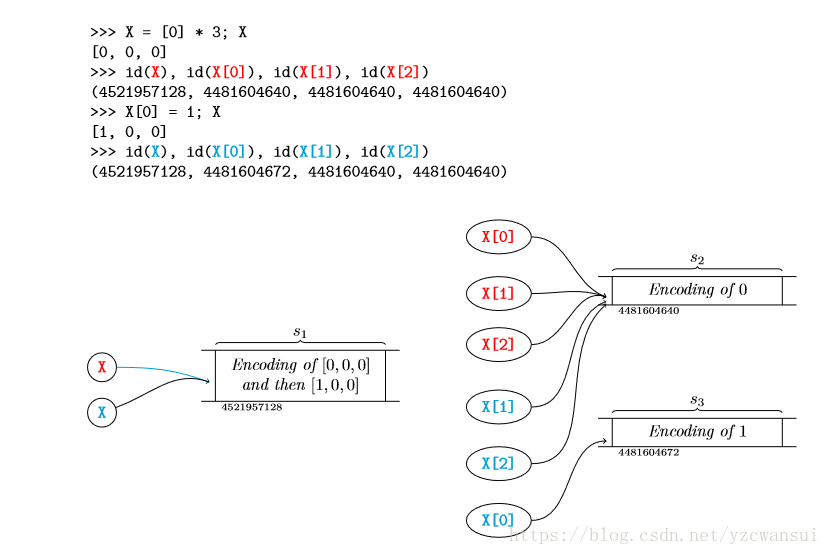
从图中可以看出,当X[0]赋值之后,其id发生了变化。 - 单独声明
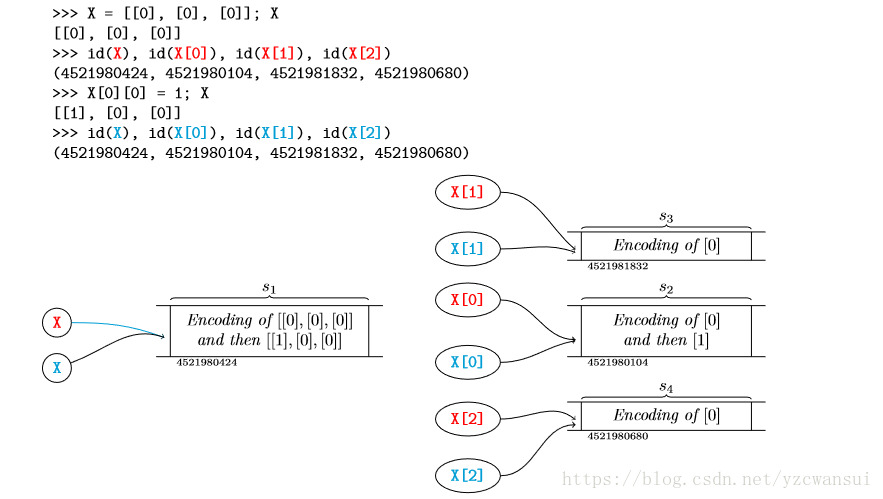
从上图可以看出,三个列表都单独声明的话,会给三个列表不一样的地址,这样就避免了给其中一个赋值,另一个相对应跟着改变的问题。