对抗生成网络学习(八)——DeblurGAN实现运动图像的去模糊化(tensorflow实现)
一、背景
DeblurGAN是Orest Kupyn等人于17年11月提出的一种模型。前面学习过,GAN可以保存影像的细节纹理特征,比如之前做过的SRGAN可以实现图像的超分辨率,因此,作者利用这个特点,结合GAN和多元内容损失来构建DeblurGAN,以实现对运动图像的去模糊化。
本试验的数据集为GOPRO数据,后面还会有详细的介绍,尽可能用比较少的代码实现DeblurGAN。
[1]文章链接:https://arxiv.org/pdf/1711.07064.pdf
二、DeblurGAN原理
DeblurGAN的创新主要是结合了之前一些GAN的网络结构和loss函数,网上的介绍比较少,先推荐一篇:
[2]《DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks》论文阅读之DeblurGAN
文章中,作者运行DeblurGAN的效果图为:
从左至右依次为:左边模糊影像,中间DeblurGAN生成影像,右边为真实影像。可以看到效果还是非常好的。
这篇文章比较短,作者简要的提出了他们的主要贡献:
We make three contributions. First, we propose a loss and architecture which obtain state-of-the art results in motion deblurring, while being 5x faster than the fastest competitor. Second, we present a method based on random trajectories for generating a dataset for motion deblurring training in an automated fashion from the set of sharp image. We show that combining it with an existing dataset for motion deblurring learning improves results compared to training on real-world images only. Finally, we present a novel dataset and method for evaluation of deblurring algorithms based on how they improve object detection results.
1. 提出了去模糊化的loss函数和模型结构,速度是目前最快编译器的5倍多。
2. 对于原始的清晰影像,用随机轨道法来生成模糊影像作为数据集。
3. 提出去模糊化算法,提高目标检测结果。
本文重点介绍DeblurGAN的实现过程,关于如何生成数据集,可以参考[2]中的介绍或者查看原文,这里只给出生成数据集的示意图和简要介绍,大概类似于对相机长曝光并抖动而产生的影像:

简单的说,就是对清晰图像卷积上各式各样的“blur kernel”,获得合成的模糊图像。作者采用了运动轨迹随机生成方法(用马尔科夫随机过程生成);然后对轨迹进行“sub-pixel interpolation”生成blur kernel。当然,这种方法也只能在二维平面空间中生成轨迹,并不能模拟真实空间中3D相机的运动[2]。
同时作者也给出了生成模糊影像算法的伪代码:

关于模型的网络结构,其实总的来看和普通的GAN并没有什么大的区别:

不过作者所采用的生成器generator的网络结构则类似于自编码器(auto-encoder):
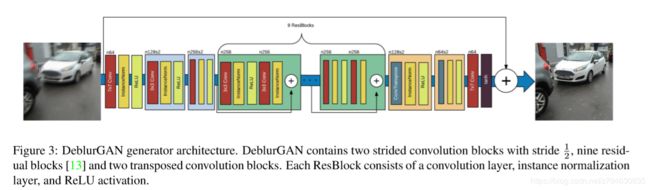
而判别器的网络结构则与PatchGAN相同。
另外,作者提到了他对loss函数进行了改进,令新的loss函数为Content loss与Adversarial loss之和。
关于DeblurGAN的实现代码,我主要参考了[3],并对该代码进行了修改。另外,网上的参考代码非常少,这里再给出几个:
[3]https://github.com/dongheehand/DeblurGAN-tf
[4]https://github.com/LeeDoYup/DeblurGAN-tf
[5]https://github.com/KupynOrest/DeblurGAN
三、DeblurGAN实现
1. 文件结构
所有的文件结构如下:
-- main.py
-- util.py
-- data_loader.py
-- mode.py
-- DeblurGAN.py
-- vgg19.py
-- layer.py
-- vgg19.npy # 这个是需要自己下载的vgg19模型,后面会说明
-- data # 这个是训练数据集,后面也会具体说明
|------ train
|------ blur
|------ image1.png
|------ image2.png
|------ ......
|------ sharp
|------ image1.png
|------ image2.png
|------ ......
|------ val
|------ val_blur
|------ image1.png
|------ image2.png
|------ ......
|------ val_sharp
|------ image1.png
|------ image2.png
|------ ......2. 数据集准备
这里需要准备的数据有两个,一个是vgg19模型文件,另一个是训练数据集。
(1)vgg19.npy模型文件
先给出vgg19.npy的下载地址;
https://mega.nz/#!xZ8glS6J!MAnE91ND_WyfZ_8mvkuSa2YcA7q-1ehfSm-Q1fxOvvs
打开上述网址,直接下载即可,不过需要注意的是,该文件需要下载:
为了方便大家的使用,我将该数据上传到了百度云上。下载地址为:
百度云地址:https://pan.baidu.com/s/1amFHn_S2nIAIbCBxFP_uEQ
提取码:bqt6
下载好该文件之后,将该文件放到项目的根目录下即可,即'./vgg19.npy'。
(2)训练数据集dataset
关于GOPRO的数据集,网上有不同的版本,这里先给出GOPRO的数据集简要介绍及下载地址,需要注意的是,下载需要:
①GOPRO_Large:该数据集的大小为8.9G,下载链接为(需要):
https://drive.google.com/uc?id=1H0PIXvJH4c40pk7ou6nAwoxuR4Qh_Sa2&export=download
②GOPRO_Large_all:该数据集的大小为35G,下载链接为(需要):
https://drive.google.com/uc?id=1SlURvdQsokgsoyTosAaELc4zRjQz9T2U&export=download
③blurred_sharp.zip:该数据集的大小为1.0G,下载链接为(需要):
https://drive.google.com/uc?export=download&confirm=jg11&id=1CPMBmRj-jBDO2ax4CxkBs9iczIFrs8VA
如果有办法能够打开上述链接,就直接打开并下载即可:

为了防止无法打开上述链接,我将该数据集上传至百度云。下载地址为:
百度云地址:https://pan.baidu.com/s/1lcCeaEeK3lv3rOt_u2hpyQ
提取码:7b3q
下载好该数据后解压,在路径'./blurred_sharp/blurred_sharp/'下,可以看到'blurred'和'sharp'两个文件夹,这里都是我们的训练数据,将'blurred'文件夹下的所有图像移至'./data/train/blur/'文件夹下,将'sharp'文件夹下的所有图像移动至'./data/train/sharp/'文件夹下,这样就制作好了训练数据,但是我们还需要拿出一部分数据作为测试数据。
我是将'./data/train/blur/'中的5张图片剪切至'./data/val/val_blur/'中,同理,将相应编号的'./data/train/sharp/'中的5张图片剪切至'./data/val/val_sharp/'中,需要注意的是这两组图片的编号必须一致对应。
构建好的数据集为:

打开这些照片的属性信息可以看到,所有的照片的大小都为720*720,格式为png。构建好数据集之后,就可以开始试验了。
3. 数据加载文件data_loader.py
data_loader.py文件中主要编写一些加载数据的函数,下面直接给出代码:
import tensorflow as tf
import os
class dataloader():
def __init__(self, args):
self.channel = 3
self.mode = args.mode
self.patch_size = args.patch_size
self.batch_size = args.batch_size
self.train_Sharp_path = args.train_Sharp_path
self.train_Blur_path = args.train_Blur_path
self.test_Sharp_path = args.test_Sharp_path
self.test_Blur_path = args.test_Blur_path
self.test_with_train = args.test_with_train
self.test_batch = args.test_batch
self.load_X = args.load_X
self.load_Y = args.load_Y
self.augmentation = args.augmentation
def build_loader(self):
if self.mode == 'train':
tr_sharp_imgs = sorted(os.listdir(self.train_Sharp_path))
tr_blur_imgs = sorted(os.listdir(self.train_Blur_path))
tr_sharp_imgs = [os.path.join(self.train_Sharp_path, ele) for ele in tr_sharp_imgs]
tr_blur_imgs = [os.path.join(self.train_Blur_path, ele) for ele in tr_blur_imgs]
train_list = (tr_blur_imgs, tr_sharp_imgs)
self.tr_dataset = tf.data.Dataset.from_tensor_slices(train_list)
self.tr_dataset = self.tr_dataset.map(self._parse, num_parallel_calls = 4).prefetch(32)
self.tr_dataset = self.tr_dataset.map(self._resize, num_parallel_calls = 4).prefetch(32)
self.tr_dataset = self.tr_dataset.map(self._get_patch, num_parallel_calls = 4).prefetch(32)
if self.augmentation:
self.tr_dataset = self.tr_dataset.map(self._data_augmentation, num_parallel_calls = 4).prefetch(32)
self.tr_dataset = self.tr_dataset.shuffle(32)
self.tr_dataset = self.tr_dataset.repeat()
self.tr_dataset = self.tr_dataset.batch(self.batch_size)
if self.test_with_train:
val_sharp_imgs = sorted(os.listdir(self.test_Sharp_path))
val_blur_imgs = sorted(os.listdir(self.test_Blur_path))
val_sharp_imgs = [os.path.join(self.test_Sharp_path, ele) for ele in val_sharp_imgs]
val_blur_imgs = [os.path.join(self.test_Blur_path, ele) for ele in val_blur_imgs]
valid_list = (val_blur_imgs, val_sharp_imgs)
self.val_dataset = tf.data.Dataset.from_tensor_slices(valid_list)
self.val_dataset = self.val_dataset.map(self._parse, num_parallel_calls=4).prefetch(32)
self.val_dataset = self.val_dataset.batch(self.test_batch)
iterator = tf.data.Iterator.from_structure(self.tr_dataset.output_types, self.tr_dataset.output_shapes)
self.next_batch = iterator.get_next()
self.init_op = {}
self.init_op['tr_init'] = iterator.make_initializer(self.tr_dataset)
if self.test_with_train:
self.init_op['val_init'] = iterator.make_initializer(self.val_dataset)
elif self.mode == 'test':
val_sharp_imgs = sorted(os.listdir(self.test_Sharp_path))
val_blur_imgs = sorted(os.listdir(self.test_Blur_path))
val_sharp_imgs = [os.path.join(self.test_Sharp_path, ele) for ele in val_sharp_imgs]
val_blur_imgs = [os.path.join(self.test_Blur_path, ele) for ele in val_blur_imgs]
valid_list = (val_blur_imgs, val_sharp_imgs)
self.val_dataset = tf.data.Dataset.from_tensor_slices(valid_list)
self.val_dataset = self.val_dataset.map(self._parse, num_parallel_calls=4).prefetch(32)
self.val_dataset = self.val_dataset.batch(1)
iterator = tf.data.Iterator.from_structure(self.val_dataset.output_types, self.val_dataset.output_shapes)
self.next_batch = iterator.get_next()
self.init_op = {}
self.init_op['val_init'] = iterator.make_initializer(self.val_dataset)
def _parse(self, image_blur, image_sharp):
image_blur = tf.read_file(image_blur)
image_sharp = tf.read_file(image_sharp)
image_blur = tf.image.decode_image(image_blur, channels=self.channel)
image_sharp = tf.image.decode_image(image_sharp, channels=self.channel)
image_blur = tf.cast(image_blur, tf.float32)
image_sharp = tf.cast(image_sharp, tf.float32)
return image_blur, image_sharp
def _resize(self, image_blur, image_sharp):
image_blur = tf.image.resize_images(image_blur, (self.load_Y, self.load_X), tf.image.ResizeMethod.BICUBIC)
image_sharp = tf.image.resize_images(image_sharp, (self.load_Y, self.load_X), tf.image.ResizeMethod.BICUBIC)
return image_blur, image_sharp
def _parse_Blur_only(self, image_blur):
image_blur = tf.read_file(image_blur)
image_blur = tf.image.decode_image(image_blur, channels=self.channel)
image_blur = tf.cast(image_blur, tf.float32)
return image_blur
def _get_patch(self, image_blur, image_sharp):
shape = tf.shape(image_blur)
ih = shape[0]
iw = shape[1]
ix = tf.random_uniform(shape=[1], minval=0, maxval=iw - self.patch_size + 1, dtype=tf.int32)[0]
iy = tf.random_uniform(shape=[1], minval=0, maxval=ih - self.patch_size + 1, dtype=tf.int32)[0]
img_sharp_in = image_sharp[iy:iy + self.patch_size, ix:ix + self.patch_size]
img_blur_in = image_blur[iy:iy + self.patch_size, ix:ix + self.patch_size]
return img_blur_in, img_sharp_in
def _data_augmentation(self, image_blur, image_sharp):
rot = tf.random_uniform(shape=[1], minval=0, maxval=3, dtype=tf.int32)[0]
flip_rl = tf.random_uniform(shape=[1], minval=0, maxval=3, dtype=tf.int32)[0]
flip_updown = tf.random_uniform(shape=[1], minval=0, maxval=3, dtype=tf.int32)[0]
image_blur = tf.image.rot90(image_blur, rot)
image_sharp = tf.image.rot90(image_sharp, rot)
rl = tf.equal(tf.mod(flip_rl, 2), 0)
ud = tf.equal(tf.mod(flip_updown, 2), 0)
image_blur = tf.cond(rl, true_fn=lambda: tf.image.flip_left_right(image_blur),
false_fn=lambda: image_blur)
image_sharp = tf.cond(rl, true_fn=lambda: tf.image.flip_left_right(image_sharp),
false_fn=lambda: image_sharp)
image_blur = tf.cond(ud, true_fn=lambda: tf.image.flip_up_down(image_blur),
false_fn=lambda: image_blur)
image_sharp = tf.cond(ud, true_fn=lambda: tf.image.flip_up_down(image_sharp),
false_fn=lambda: image_sharp)
return image_blur, image_sharp
4. vgg19文件vgg19.py
vgg19.py文件主要是用来加载vgg19模型的,这里直接给出代码:
import tensorflow as tf
import numpy as np
import time
VGG_MEAN = [103.939, 116.779, 123.68]
class Vgg19:
def __init__(self, vgg19_npy_path):
self.data_dict = np.load(vgg19_npy_path, encoding='latin1').item()
print("npy file loaded")
def build(self, rgb):
"""
load variable from npy to build the VGG
:param rgb: rgb image [batch, height, width, 3] values scaled [-1, 1]
"""
start_time = time.time()
print("build vgg19 model started")
rgb_scaled = ((rgb + 1) * 255.0) / 2.0
# Convert RGB to BGR
red, green, blue = tf.split(axis=3, num_or_size_splits=3, value=rgb_scaled)
bgr = tf.concat(axis=3, values=[blue - VGG_MEAN[0], green - VGG_MEAN[1], red - VGG_MEAN[2]])
self.conv1_1 = self.conv_layer(bgr, "conv1_1")
self.relu1_1 = self.relu_layer(self.conv1_1, "relu1_1")
self.conv1_2 = self.conv_layer(self.relu1_1, "conv1_2")
self.relu1_2 = self.relu_layer(self.conv1_2, "relu1_2")
self.pool1 = self.max_pool(self.relu1_2, 'pool1')
self.conv2_1 = self.conv_layer(self.pool1, "conv2_1")
self.relu2_1 = self.relu_layer(self.conv2_1, "relu2_1")
self.conv2_2 = self.conv_layer(self.relu2_1, "conv2_2")
self.relu2_2 = self.relu_layer(self.conv2_2, "relu2_2")
self.pool2 = self.max_pool(self.relu2_2, 'pool2')
self.conv3_1 = self.conv_layer(self.pool2, "conv3_1")
self.relu3_1 = self.relu_layer(self.conv3_1, "relu3_1")
self.conv3_2 = self.conv_layer(self.relu3_1, "conv3_2")
self.relu3_2 = self.relu_layer(self.conv3_2, "relu3_2")
self.conv3_3 = self.conv_layer(self.relu3_2, "conv3_3")
self.relu3_3 = self.relu_layer(self.conv3_3, "relu3_3")
self.conv3_4 = self.conv_layer(self.relu3_3, "conv3_4")
self.relu3_4 = self.relu_layer(self.conv3_4, "relu3_4")
self.pool3 = self.max_pool(self.relu3_4, 'pool3')
self.conv4_1 = self.conv_layer(self.pool3, "conv4_1")
self.relu4_1 = self.relu_layer(self.conv4_1, "relu4_1")
self.conv4_2 = self.conv_layer(self.relu4_1, "conv4_2")
self.relu4_2 = self.relu_layer(self.conv4_2, "relu4_2")
self.conv4_3 = self.conv_layer(self.relu4_2, "conv4_3")
self.relu4_3 = self.relu_layer(self.conv4_3, "relu4_3")
self.conv4_4 = self.conv_layer(self.relu4_3, "conv4_4")
self.relu4_4 = self.relu_layer(self.conv4_4, "relu4_4")
self.pool4 = self.max_pool(self.relu4_4, 'pool4')
self.conv5_1 = self.conv_layer(self.pool4, "conv5_1")
self.relu5_1 = self.relu_layer(self.conv5_1, "relu5_1")
self.conv5_2 = self.conv_layer(self.relu5_1, "conv5_2")
self.relu5_2 = self.relu_layer(self.conv5_2, "relu5_2")
self.conv5_3 = self.conv_layer(self.relu5_2, "conv5_3")
self.relu5_3 = self.relu_layer(self.conv5_3, "relu5_3")
self.conv5_4 = self.conv_layer(self.relu5_3, "conv5_4")
self.relu5_4 = self.relu_layer(self.conv5_4, "relu5_4")
self.pool5 = self.max_pool(self.conv5_4, 'pool5')
self.data_dict = None
print(("build vgg19 model finished: %ds" % (time.time() - start_time)))
def max_pool(self, bottom, name):
return tf.nn.max_pool(bottom, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name=name)
def relu_layer(self, bottom, name):
return tf.nn.relu(bottom, name=name)
def conv_layer(self, bottom, name):
with tf.variable_scope(name):
filt = self.get_conv_filter(name)
conv = tf.nn.conv2d(bottom, filt, [1, 1, 1, 1], padding='SAME')
conv_biases = self.get_bias(name)
bias = tf.nn.bias_add(conv, conv_biases)
return bias
def get_conv_filter(self, name):
return tf.constant(self.data_dict[name][0], name="filter")
def get_bias(self, name):
return tf.constant(self.data_dict[name][1], name="biases")5. 图像处理文件util.py
由于数据其实是成对出现的,所以在util.py文件中需要将读取到的数据成对处理,下面给出代码:
from PIL import Image
import numpy as np
import random
import os
def image_loader(image_path, load_x, load_y, is_train = True):
imgs = sorted(os.listdir(image_path))
img_list = []
for ele in imgs:
img = Image.open(os.path.join(image_path, ele))
if is_train:
img = img.resize((load_x, load_y), Image.BICUBIC)
img_list.append(np.array(img))
return img_list
def data_augument(lr_img, hr_img, aug):
if aug < 4:
lr_img = np.rot90(lr_img, aug)
hr_img = np.rot90(hr_img, aug)
elif aug == 4:
lr_img = np.fliplr(lr_img)
hr_img = np.fliplr(hr_img)
elif aug == 5:
lr_img = np.flipud(lr_img)
hr_img = np.flipud(hr_img)
elif aug == 6:
lr_img = np.rot90(np.fliplr(lr_img))
hr_img = np.rot90(np.fliplr(hr_img))
elif aug == 7:
lr_img = np.rot90(np.flipud(lr_img))
hr_img = np.rot90(np.flipud(hr_img))
return lr_img, hr_img
def batch_gen(blur_imgs, sharp_imgs, patch_size, batch_size, random_index, step, augment=False):
img_index = random_index[step * batch_size: (step + 1) * batch_size]
all_img_blur = []
all_img_sharp = []
for _index in img_index:
all_img_blur.append(blur_imgs[_index])
all_img_sharp.append(sharp_imgs[_index])
blur_batch = []
sharp_batch = []
for i in range(len(all_img_blur)):
ih, iw, _ = all_img_blur[i].shape
ix = random.randrange(0, iw - patch_size + 1)
iy = random.randrange(0, ih - patch_size + 1)
img_blur_in = all_img_blur[i][iy:iy + patch_size, ix:ix + patch_size]
img_sharp_in = all_img_sharp[i][iy:iy + patch_size, ix:ix + patch_size]
if augment:
aug = random.randrange(0, 8)
img_blur_in, img_sharp_in = data_augument(img_blur_in, img_sharp_in, aug)
blur_batch.append(img_blur_in)
sharp_batch.append(img_sharp_in)
blur_batch = np.array(blur_batch)
sharp_batch = np.array(sharp_batch)
return blur_batch, sharp_batch
6. 图层文件layer.py
DeblurGAN中用到的卷积、反卷积、以及norm层都在layer文件中进行定义,代码为:
import tensorflow as tf
import numpy as np
def Conv(name, x, filter_size, in_filters, out_filters, strides, padding):
with tf.variable_scope(name):
kernel = tf.get_variable('filter', [filter_size, filter_size, in_filters, out_filters], tf.float32,
initializer=tf.random_normal_initializer(stddev=0.01))
bias = tf.get_variable('bias', [out_filters], tf.float32, initializer=tf.zeros_initializer())
return tf.nn.conv2d(x, kernel, [1, strides, strides, 1], padding=padding) + bias
def Conv_transpose(name, x, filter_size, in_filters, out_filters, fraction=2, padding="SAME"):
with tf.variable_scope(name):
n = filter_size * filter_size * out_filters
kernel = tf.get_variable('filter', [filter_size, filter_size, out_filters, in_filters], tf.float32,
initializer=tf.random_normal_initializer(stddev=np.sqrt(2.0/n)))
size = tf.shape(x)
output_shape = tf.stack([size[0], size[1] * fraction, size[2] * fraction, out_filters])
x = tf.nn.conv2d_transpose(x, kernel, output_shape, [1, fraction, fraction, 1], padding)
return x
def instance_norm(x, BN_epsilon=1e-3):
mean, variance = tf.nn.moments(x, axes=[1, 2])
x = (x - mean) / ((variance + BN_epsilon) ** 0.5)
return x7. 构建模型文件DeblurGAN.py
前面的文件都是在做一些准备工作,这一步才是需要建立DeblurGAN模型,代码为:
from layer import *
from data_loader import dataloader
from vgg19 import Vgg19
class DeblurGAN():
def __init__(self, args):
self.data_loader = dataloader(args)
print("data has been loaded")
self.channel = 3
self.n_feats = args.n_feats
self.mode = args.mode
self.batch_size = args.batch_size
self.num_of_down_scale = args.num_of_down_scale
self.gen_resblocks = args.gen_resblocks
self.discrim_blocks = args.discrim_blocks
self.vgg_path = args.vgg_path
self.learning_rate = args.learning_rate
self.decay_step = args.decay_step
def down_scaling_feature(self, name, x, n_feats):
x = Conv(name=name + 'conv', x=x, filter_size=3, in_filters=n_feats,
out_filters=n_feats * 2, strides=2, padding='SAME')
x = instance_norm(x)
x = tf.nn.relu(x)
return x
def up_scaling_feature(self, name, x, n_feats):
x = Conv_transpose(name=name + 'deconv', x=x, filter_size=3, in_filters=n_feats,
out_filters=n_feats // 2, fraction=2, padding='SAME')
x = instance_norm(x)
x = tf.nn.relu(x)
return x
def res_block(self, name, x, n_feats):
_res = x
x = tf.pad(x, [[0, 0], [1, 1], [1, 1], [0, 0]], mode='REFLECT')
x = Conv(name=name + 'conv1', x=x, filter_size=3, in_filters=n_feats,
out_filters=n_feats, strides=1, padding='VALID')
x = instance_norm(x)
x = tf.nn.relu(x)
x = tf.pad(x, [[0, 0], [1, 1], [1, 1], [0, 0]], mode='REFLECT')
x = Conv(name=name + 'conv2', x=x, filter_size=3, in_filters=n_feats,
out_filters=n_feats, strides=1, padding='VALID')
x = instance_norm(x)
x = x + _res
return x
def generator(self, x, reuse=False, name='generator'):
with tf.variable_scope(name_or_scope=name, reuse=reuse):
_res = x
x = tf.pad(x, [[0, 0], [3, 3], [3, 3], [0, 0]], mode='REFLECT')
x = Conv(name='conv1', x=x, filter_size=7, in_filters=self.channel,
out_filters=self.n_feats, strides=1, padding='VALID')
# x = instance_norm(name = 'inst_norm1', x = x, dim = self.n_feats)
x = instance_norm(x)
x = tf.nn.relu(x)
for i in range(self.num_of_down_scale):
x = self.down_scaling_feature(name='down_%02d' % i, x=x, n_feats=self.n_feats * (i + 1))
for i in range(self.gen_resblocks):
x = self.res_block(name='res_%02d' % i, x=x, n_feats=self.n_feats * (2 ** self.num_of_down_scale))
for i in range(self.num_of_down_scale):
x = self.up_scaling_feature(name='up_%02d' % i, x=x,
n_feats=self.n_feats * (2 ** (self.num_of_down_scale - i)))
x = tf.pad(x, [[0, 0], [3, 3], [3, 3], [0, 0]], mode='REFLECT')
x = Conv(name='conv_last', x=x, filter_size=7, in_filters=self.n_feats,
out_filters=self.channel, strides=1, padding='VALID')
x = tf.nn.tanh(x)
x = x + _res
x = tf.clip_by_value(x, -1.0, 1.0)
return x
def discriminator(self, x, reuse=False, name='discriminator'):
with tf.variable_scope(name_or_scope=name, reuse=reuse):
x = Conv(name='conv1', x=x, filter_size=4, in_filters=self.channel,
out_filters=self.n_feats, strides=2, padding="SAME")
x = instance_norm(x)
x = tf.nn.leaky_relu(x)
n = 1
for i in range(self.discrim_blocks):
prev = n
n = min(2 ** (i+1), 8)
x = Conv(name='conv%02d' % i, x=x, filter_size=4, in_filters=self.n_feats * prev,
out_filters=self.n_feats * n, strides=2, padding="SAME")
x = instance_norm(x)
x = tf.nn.leaky_relu(x)
prev = n
n = min(2 ** self.discrim_blocks, 8)
x = Conv(name='conv_d1', x=x, filter_size=4, in_filters=self.n_feats * prev,
out_filters=self.n_feats * n, strides=1, padding="SAME")
# x = instance_norm(name = 'instance_norm_d1', x = x, dim = self.n_feats * n)
x = instance_norm(x)
x = tf.nn.leaky_relu(x)
x = Conv(name='conv_d2', x=x, filter_size=4, in_filters=self.n_feats * n,
out_filters=1, strides=1, padding="SAME")
x = tf.nn.sigmoid(x)
return x
def build_graph(self):
# if self.in_memory:
self.blur = tf.placeholder(name="blur", shape=[None, None, None, self.channel], dtype=tf.float32)
self.sharp = tf.placeholder(name="sharp", shape=[None, None, None, self.channel], dtype=tf.float32)
x = self.blur
label = self.sharp
self.epoch = tf.placeholder(name='train_step', shape=None, dtype=tf.int32)
x = (2.0 * x / 255.0) - 1.0
label = (2.0 * label / 255.0) - 1.0
self.gene_img = self.generator(x, reuse=False)
self.real_prob = self.discriminator(label, reuse=False)
self.fake_prob = self.discriminator(self.gene_img, reuse=True)
epsilon = tf.random_uniform(shape=[self.batch_size, 1, 1, 1], minval=0.0, maxval=1.0)
interpolated_input = epsilon * label + (1 - epsilon) * self.gene_img
gradient = tf.gradients(self.discriminator(interpolated_input, reuse=True), [interpolated_input])[0]
GP_loss = tf.reduce_mean(tf.square(tf.sqrt(tf.reduce_mean(tf.square(gradient), axis=[1, 2, 3])) - 1))
d_loss_real = - tf.reduce_mean(self.real_prob)
d_loss_fake = tf.reduce_mean(self.fake_prob)
self.vgg_net = Vgg19(self.vgg_path)
self.vgg_net.build(tf.concat([label, self.gene_img], axis=0))
self.content_loss = tf.reduce_mean(tf.reduce_sum(tf.square(
self.vgg_net.relu3_3[self.batch_size:] - self.vgg_net.relu3_3[:self.batch_size]), axis=3))
self.D_loss = d_loss_real + d_loss_fake + 10.0 * GP_loss
self.G_loss = - d_loss_fake + 100.0 * self.content_loss
t_vars = tf.trainable_variables()
G_vars = [var for var in t_vars if 'generator' in var.name]
D_vars = [var for var in t_vars if 'discriminator' in var.name]
lr = tf.minimum(self.learning_rate, tf.abs(2 * self.learning_rate - (
self.learning_rate * tf.cast(self.epoch, tf.float32) / self.decay_step)))
self.D_train = tf.train.AdamOptimizer(learning_rate=lr).minimize(self.D_loss, var_list=D_vars)
self.G_train = tf.train.AdamOptimizer(learning_rate=lr).minimize(self.G_loss, var_list=G_vars)
self.PSNR = tf.reduce_mean(tf.image.psnr(((self.gene_img + 1.0) / 2.0), ((label + 1.0) / 2.0), max_val=1.0))
self.ssim = tf.reduce_mean(tf.image.ssim(((self.gene_img + 1.0) / 2.0), ((label + 1.0) / 2.0), max_val=1.0))
logging_D_loss = tf.summary.scalar(name='D_loss', tensor=self.D_loss)
logging_G_loss = tf.summary.scalar(name='G_loss', tensor=self.G_loss)
logging_PSNR = tf.summary.scalar(name='PSNR', tensor=self.PSNR)
logging_ssim = tf.summary.scalar(name='ssim', tensor=self.ssim)
self.output = (self.gene_img + 1.0) * 255.0 / 2.0
self.output = tf.round(self.output)
self.output = tf.cast(self.output, tf.uint8)
8. 试验过程文件mode.py
mode.py文件主要编写train和test函数,不过这个文件其实可以和main文件进行合并,先给出代码:
import os
import tensorflow as tf
from PIL import Image
import numpy as np
import time
import util
def train(args, model, sess, saver):
if args.fine_tuning:
saver.restore(sess, args.pre_trained_model)
print("saved model is loaded for fine-tuning!")
print("model path is %s" % args.pre_trained_model)
num_imgs = len(os.listdir(args.train_Sharp_path))
merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter('./logs', sess.graph)
if args.test_with_train:
f = open("valid_logs.txt", 'w')
epoch = 0
step = num_imgs // args.batch_size
blur_imgs = util.image_loader(args.train_Blur_path, args.load_X, args.load_Y)
sharp_imgs = util.image_loader(args.train_Sharp_path, args.load_X, args.load_Y)
while epoch < args.max_epoch:
random_index = np.random.permutation(len(blur_imgs))
for k in range(step):
s_time = time.time()
blur_batch, sharp_batch = util.batch_gen(blur_imgs, sharp_imgs, args.patch_size,
args.batch_size, random_index, k)
for t in range(args.critic_updates):
_, D_loss = sess.run([model.D_train, model.D_loss],
feed_dict={model.blur: blur_batch, model.sharp: sharp_batch, model.epoch: epoch})
_, G_loss = sess.run([model.G_train, model.G_loss],
feed_dict={model.blur: blur_batch, model.sharp: sharp_batch, model.epoch: epoch})
e_time = time.time()
if epoch % args.log_freq == 0:
summary = sess.run(merged, feed_dict={model.blur: blur_batch, model.sharp: sharp_batch})
train_writer.add_summary(summary, epoch)
if args.test_with_train:
test(args, model, sess, saver, f, epoch, loading=False)
print("%d training epoch completed" % epoch)
print("D_loss : {}, \t G_loss : {}".format(D_loss, G_loss))
print("Elpased time : %0.4f" % (e_time - s_time))
# print("D_loss : %0.4f, \t G_loss : %0.4f" % (D_loss, G_loss))
# print("Elpased time : %0.4f" % (e_time - s_time))
if (epoch) % args.model_save_freq == 0:
saver.save(sess, './model/DeblurrGAN', global_step=epoch, write_meta_graph=False)
epoch += 1
saver.save(sess, './model/DeblurrGAN_last', write_meta_graph=False)
if args.test_with_train:
f.close()
def test(args, model, sess, saver, file, step=-1, loading=False):
if loading:
import re
print(" [*] Reading checkpoints...")
ckpt = tf.train.get_checkpoint_state(args.pre_trained_model)
if ckpt and ckpt.model_checkpoint_path:
ckpt_name = os.path.basename(ckpt.model_checkpoint_path)
saver.restore(sess, os.path.join(args.pre_trained_model, ckpt_name))
print(" [*] Success to read {}".format(ckpt_name))
else:
print(" [*] Failed to find a checkpoint")
blur_img_name = sorted(os.listdir(args.test_Blur_path))
sharp_img_name = sorted(os.listdir(args.test_Sharp_path))
PSNR_list = []
ssim_list = []
blur_imgs = util.image_loader(args.test_Blur_path, args.load_X, args.load_Y, is_train=False)
sharp_imgs = util.image_loader(args.test_Sharp_path, args.load_X, args.load_Y, is_train=False)
if not os.path.exists('./result/'):
os.makedirs('./result/')
for i, ele in enumerate(blur_imgs):
blur = np.expand_dims(ele, axis = 0)
sharp = np.expand_dims(sharp_imgs[i], axis = 0)
output, psnr, ssim = sess.run([model.output, model.PSNR, model.ssim], feed_dict = {model.blur : blur, model.sharp : sharp})
if args.save_test_result:
output = Image.fromarray(output[0])
split_name = blur_img_name[i].split('.')
output.save(os.path.join(args.result_path, '%s_sharp.png'%(''.join(map(str, split_name[:-1])))))
PSNR_list.append(psnr)
ssim_list.append(ssim)
length = len(PSNR_list)
mean_PSNR = sum(PSNR_list) / length
mean_ssim = sum(ssim_list) / length
if step == -1:
file.write('PSNR : {} SSIM : {}' .format(mean_PSNR, mean_ssim))
file.close()
else:
file.write("{}d-epoch step PSNR : {} SSIM : {} \n".format(step, mean_PSNR, mean_ssim))9. 参数设置的主文件main.py
最后就是main.py文件了,主要是参数设置,然后运行模型即可。代码为:
import tensorflow as tf
from DeblurGAN import DeblurGAN
from mode import *
import argparse
parser = argparse.ArgumentParser()
def str2bool(v):
return v.lower() in ('true')
## Model specification
parser.add_argument("--n_feats", type=int, default=64)
parser.add_argument("--num_of_down_scale", type=int, default=2)
parser.add_argument("--gen_resblocks", type=int, default=9)
parser.add_argument("--discrim_blocks", type=int, default=3)
## Data specification
parser.add_argument("--train_Sharp_path", type=str, default="./data/train/sharp/")
parser.add_argument("--train_Blur_path", type=str, default="./data/train/blur")
parser.add_argument("--test_Sharp_path", type=str, default="./data/val/val_sharp")
parser.add_argument("--test_Blur_path", type=str, default="./data/val/val_blur")
parser.add_argument("--vgg_path", type=str, default="./vgg19.npy")
parser.add_argument("--patch_size", type=int, default=256)
parser.add_argument("--result_path", type=str, default="./result")
parser.add_argument("--model_path", type=str, default="./model")
## Optimization
parser.add_argument("--batch_size", type=int, default=1)
parser.add_argument("--max_epoch", type=int, default=200)
parser.add_argument("--learning_rate", type=float, default=1e-4)
parser.add_argument("--decay_step", type=int, default=150)
parser.add_argument("--test_with_train", type=str2bool, default=True)
parser.add_argument("--save_test_result", type=str2bool, default=True)
## Training or test specification
parser.add_argument("--mode", type=str, default="train")
parser.add_argument("--critic_updates", type=int, default=5)
parser.add_argument("--augmentation", type=str2bool, default=False)
parser.add_argument("--load_X", type=int, default=640)
parser.add_argument("--load_Y", type=int, default=360)
parser.add_argument("--fine_tuning", type=str2bool, default=False)
parser.add_argument("--log_freq", type=int, default=1)
parser.add_argument("--model_save_freq", type=int, default=20)
parser.add_argument("--pre_trained_model", type=str, default="./model/")
parser.add_argument("--test_batch", type=int, default=5)
args = parser.parse_args()
model = DeblurGAN(args)
model.build_graph()
print("Build DeblurGAN model!")
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver(max_to_keep=None)
if args.mode == 'train':
train(args, model, sess, saver)
elif args.mode == 'test':
f = open("test_results.txt", 'w')
test(args, model, sess, saver, f, step=-1, loading=True)
f.close()
四、试验结果
准备好了所有文件之后,下面是关于模型的运行。首先需要训练函数,将main.py代码中的mode参数设置为train,然后执行训练即可:
parser.add_argument("--mode", type=str, default="train")最开始我是设置epoch为300,每50个epoch保存一次模型结果。但是用GPU(GTX1060 3G)训练了一晚上,只训练了51个epoch,因此我将上面的epoch相关参数设置小了一些。最终我只用训练50个epoch的模型进行测试。
测试的时候,需要修改上面的mode参数,将其改为test,然后就可以直接开始运行代码:
parser.add_argument("--mode", type=str, default="test")下面直接给出运行的试验结果:

粗略以看效果还不错,下面可以放大看看细节上的恢复效果:


放大来看的话,相比于blur影像,确实可以明显的感觉图像清晰了很多,但是也许是训练的次数还不够或者是原图像过度模糊难以复原,放大了看仍有一些地方比较模糊。
五、分析
1. 文件结构见三
2. DeblurGAN开创性的用GAN做了图像去模糊化的工作。
2019-12-16更新
3. 没想到做这篇文章的人这么多,大家都遇到的一些问题我在这里再统一提一下:
① G_loss过大的问题:大部分都反应d_loss是正常的,但是g_loss值很大,经常过亿,但是模型的效果都很好。
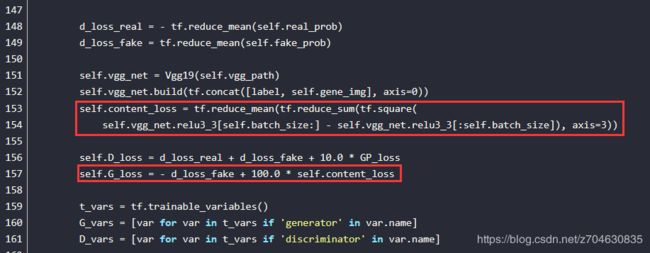
原因:个人觉得既然模型效果和d_loss没问题,那应该是g_loss的公式没写对吧,底下有人评论说请教过原作者了,将deblurGAN.py文件中的第153行中的tf.reduce_sum改成tf.reduce_mean效果会好很多。我们来看一下吧,如下图,第157行的g_loss由两部分构成,不过d_loss是没问题的,说明问题应该在100*self.content_loss上,自然的,我们就应该把目光投向content_loss,也就是153-154行。
后面是原文中作者给出的content loss:建议采用L1范或L2范,作者并给出了相关公式。这里作者用的是L2范,计算的话就是用平滑图像的feature map - 模糊图像的feature map,再平方求和,最后除以feature map的面积(长成宽个像素)。feature map取得是conv 3-3层。所以对照原文的content loss和代码的153-154行,原作者似乎是没有除feature map的面积。

②无法加载vgg的问题:加载vgg时候报错ValueError: Object arrays cannot be loaded when allow_pickle=False。
我看到有人回复,原因是因为你的numpy版本太高了,将numpy版本降到1.13就可以。
③batch_size不能设置为其他值,比如设置为16就报错:ValueError: Dimensions must be equal, but are 8 and 16 for 'discriminator_2/sub_1' (op: 'Sub') with input shapes: [16,?,8,128], [16,128]
不是说不能设置为其他值,只不过设置为其他值得时候模型中的涉及到shape变化的地方一定要注意是否对应,不对应的地方必然报错,解决办法需要自己改一下模型里面层的操作。
④其他关于数据加载的问题,这里不再多做解释了,认真查一下代码路径之类的问题,代码基本都能运行
4 另外说明一下,这篇文章的实验是去年做的,自己用空余时间在做GAN,做这篇文章的时候大概才接触了3个月的GAN吧,实验和回答中难免有一些不足的地方,原作者的代码中,我自己删了一些保存结果的代码,还有验证部分的代码,我自己只是想实验这个效果,所以我自己主要保留了训练和测试部分。
最后,非常感谢大家的回复和相关讨论,