《高性能Mysql第三版》读书笔记
文章目录
- 一 简介
- 二 理论
- Mysql逻辑架构图
- 事务
- 表锁,行级锁
- RR事务隔离级别,如何解决幻读问题
- 多版本并发控制(MVCC)
- MVCC下InnoDB的增删查改是怎么工作的
- 三星系统原则
- 聚簇索引和非聚簇索引
- 覆盖索引
- 使用索引扫描来做排序
- 查询优化器的优化
- BTree B+Tree,索引的模型结构,MyIsam和Innodb的索引区别:
- 二 重构查询
- 一条sql查询执行的链路过程
- 分解关联查询
- 排序优化
一 简介
这篇博客中的知识点,算是在阅读《高性能Mysql第三版》这本书的一个读书笔记,有一点比较尴尬的事情是我并没有买这本书,而是下载了这本书的PDF版本进行阅读(无奈原书太贵)。
但是,还是要强烈的打一个广告,这本书真的很是值得你一读,尽管它的一些知识点是停留在理论的基础上,并没有很深入的讲解底层的实现机制(像是一本运维层面的理论书),但是这些已经很是足够了(对于程序员来说),如果你这些都不会的话,底层给你讲也是白用。
二 理论
Mysql逻辑架构图
(这一部分不是来源于本书)
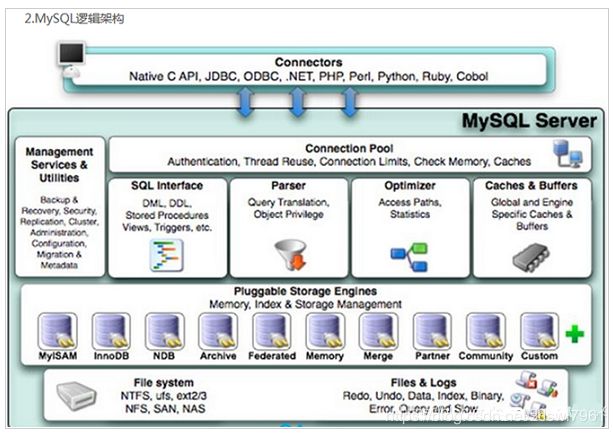
连接层(Connectors)
最上层是一些客户端和连接服务,包含本地socket通信和大多数基于客户端/服务端工具实现的类似于tcp/ip的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
服务层(Server)

引擎层(Engines)
存储引擎层,存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取。
文件系统和日志收集(File System&Logs)
对应了底层mysql数据存储的文件系统,以及提供了对应查询的日志记录(binlog)
事务
事务的隔离级别?幻读和不可重复的区别
表锁,行级锁
表锁:

行级锁:

行锁和表锁的案例分析:
对于表user_info(id,userName,password,school)中,id为主键
1,新建事务窗口A,设置set autocommit = 0,执行update user_info set school =‘浙江财经大学信息学院’ where id = 1,不提交事务
2,新建事务窗口B,执行update user_info set school =‘浙江财经大学信息学院’ where id = 1,此时会发现一致处于阻塞状态
事务A:
mysql> select * from user_info ;
+----+----------+----------+---------+--------------+
| id | userName | password | address | school |
+----+----------+----------+---------+--------------+
| 1 | 23 | 23 | 23 | 浙江财经大学 |
| 2 | 34 | 34 | 34 | 浙江大学 |
+----+----------+----------+---------+--------------+
2 rows in set (0.04 sec)
mysql> set autocommit = 0;
Query OK, 0 rows affected (0.01 sec)
mysql> update user_info set school ='浙江财经大学信息学院' where id
-> = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql>
事务B:
mysql> set autocommit = 0;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user_info ;
+----+----------+----------+---------+--------------+
| id | userName | password | address | school |
+----+----------+----------+---------+--------------+
| 1 | 23 | 23 | 23 | 浙江财经大学 |
| 2 | 34 | 34 | 34 | 浙江大学 |
+----+----------+----------+---------+--------------+
2 rows in set (0.01 sec)
mysql> update user_info set school='浙江大学信息学院' where id = 2;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update user_info set school='浙江大学信息学院' where id = 1;
1205 - Lock wait timeout exceeded; try restarting transaction //会发现获取写锁操作
mysql>
总结:多个事务操作同一行数据时,后来的事务处于阻塞等待状态。这样可以避免了脏读等数据一致性的问题。后来的事务可以操作其他行数据,解决了表锁高并发性能低的问题。
案例二,
对于A事务,我们执行 set autocommit = 0,同时执行 update user_info set school=‘浙江大学’ where userName = ‘23’; (注意此时userName没有索引),不执行commit提交事务
对于B事务,在A事务执行update语句之后,执行update user_info set school=‘浙江财经大学’ where userName = ‘34’;(注意此时userName没有索引,并且更新的语句并不是和A事务相同一行的语句),此时,B事务任然会进行阻塞状态
A事务:
mysql> update user_info set school='浙江大学' where userName = '23';
Query OK, 0 rows affected (0.00 sec)
Rows matched: 1 Changed: 0 Warnings: 0
mysql>
B事务:
mysql> update user_info set school='浙江财经大学' where userName = '34';
1205 - Lock wait timeout exceeded; try restarting transaction //阻塞超时
mysql>
总结:InnoDB的行锁是针对索引加的锁,不是针对记录加的锁。并且该索引不能失效,否则都会从行锁升级为表锁
行锁的劣势:开销大;加锁慢;会出现死锁
行锁的优势:锁的粒度小,发生锁冲突的概率低;处理并发的能力强
加锁的方式:自动加锁。对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁;对于普通SELECT语句,InnoDB不会加任何锁;当然我们也可以显示的加锁:
共享锁:select * from tableName where … + lock in share more
排他锁:select * from tableName where … + for update
Innodb默认是行级别的锁,当又明确指定的主键(索引)时候,是行级锁,否则是表级锁
RR事务隔离级别,如何解决幻读问题
RR事务隔离级别下,是通过MVCC解决了幻读现象:
但是:RR的事务隔离级别并没有解决另一种通常意义上说的也是幻读现象,那就是insert的情况
通常意义上,是通过排他锁进行解决:参考:事务的隔离级别?幻读和不可重复的区别#幻读
多版本并发控制(MVCC)
Mysql的大多数事务型存储引起实现的都不是简单的行级锁,基于提升性能的考虑,他们一般都同时实现了多版本并发控制(MVCC),不仅是Mysql,包括Oracle,PostgreSQL等其他数据库系统也都实现了MVCC,
可以认为MVCC是行级锁的一个变种,但是它在很多情况下避免了加锁的操作。因此开销更低,虽然实现机制有所不同,但大都实现了非阻塞的读操作,写操作也是锁定了必要的行。


MVCC示例(简约逻辑):参考:Mysql中MVCC的使用及原理详解
1,插入数据(insert):记录的版本号即当前事务的版本号
执行一条数据语句:insert into testmvcc values(1,“test”);
MVCC下InnoDB的增删查改是怎么工作的
假设事务id为1,那么插入后的数据行如下:
![]()
2,在更新操作的时候,采用的是先标记旧的那行记录为已删除,并且删除版本号是事务版本号,然后插入一行新的记录的方式(这个??),比如,针对上面那行记录,事务id为2,要把name字段更新,
update table set name= ‘new_value’ where id=1;

3、删除操作的时候,就把事务版本号作为删除版本号。比如
delete from table where id=1;

补充:
- 1.MVCC手段只适用于Msyql隔离级别中的读已提交(Read committed)和可重复读(Repeatable Read).
- 2.Read uncimmitted由于存在脏读,即能读到未提交事务的数据行,所以不适用MVCC.原因是MVCC的创建版本和删除版本只要在事务提交后才会产生。
- 3.串行化由于是会对所涉及到的表加锁,并非行锁,自然也就不存在行的版本控制问题。
- 4.通过以上总结,可知,MVCC主要作用于事务性的,有行锁控制的数据库模型。
三星系统原则
Lahdenmarki和Leach在书中介绍了如何评价一个索引是否适合某个查询的“三星系统”:
- 索引讲相关的记录放到一起则获得一星。
- 如果索引中的数据顺序和查找中的排列顺序一致则获得二星。
- 如果索引中的列包含查询中需要的全部列则获取”三星“

聚簇索引和非聚簇索引
聚簇索引:聚簇索引既存储了表数据key又存储了行值,物理地址的逻辑顺序和表存储的顺序一致!是唯一的(主键毫无疑问是一个聚簇索引)
非聚簇索引:存放了表数据的物理地址和key值,可根据key值对应的物理地址再查询具体的行值,但是物理地址存放的顺序和表存放的逻辑顺序没有强一致性!
覆盖索引
如果一个索引包含(或者是覆盖)所有需要查询的字段的值,我们就称之为”覆盖索引“
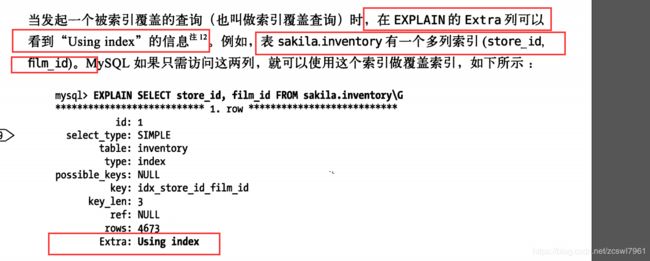

使用索引扫描来做排序


这里面我的测试库user_info中,创建了一个组合索引pk_school(userName,password,school),使用下面sql语句:
即没有对应where查询条件,并且order by 的字段对应组合索引的顺序,并且查询的结果address不存在对应的组合索引中,这种情况下,是不走任何索引。(这种情况似乎只能走覆盖索引)
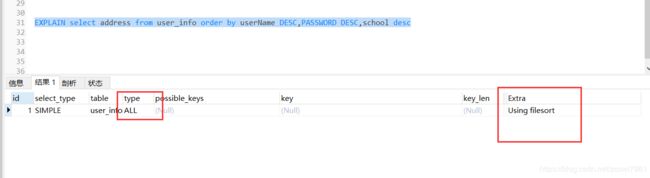
EXPLAIN select address from user_info order by userName DESC,PASSWORD DESC,school desc
使用下列sql:
即通过设置userName为固定值,会走索引
EXPLAIN select address from user_info where userName = '12' order by PASSWORD DESC,school desc

但是,如果下面的sql是不会走索引的:
EXPLAIN select address from user_info where userName = '12' order by PASSWORD,school DESC
原因是因为orderby后面的password默认是走AES排序的,只有当索引的列顺序和order by子句的顺序完全一致,并且所有列的排序方向(倒序或者是正序)都一样时,mysql才能使用索引来对结果做排序
我们在做Mysql的性能分析(Explain语句)最后一个Extra会出现一些常见的Using Where,Using Index,Using filsort,using index condition(5.6版本之后),以及他们的组合的秒速:
- Using filsort:常见的理解就是该条语句走了文件排序,即不走任何索引(也就是mysql需要做一次额外的排序)
- Using index:使用覆盖索引的时候就会出现
- Using where:在查找使用索引的情况下,需要回表去查询所需的数据
- using index condition:查询使用了索引,但是需要回表查询数据(5.6版本之后)
- using index & using where:查询使用了索引,但是需要的数据在索引中都能找到,所以不需要回表查询
- Using where; Using index; Using filesort:这句话的意思是,查询使用了索引,并且查询的结果也在索引中找到,但是需要做一次额外的排序
查询优化器的优化
例如:如果建的组合索引(name,cid),而查询的语句是cid = 1 and name = ‘小红’,为什么还能利用到索引?
当按照索引中的所有列(这句话确切的说应该是符合左前缀原则的列,因为在(name,cid,password)这个组合索引下,查询语句 password = ‘124’ and name = ‘小红’ 是任然能够使用到这个组合索引的)进行精度匹配时,(= 或者 IN)时,索引可以被用到,并且type为const。理论上索引对顺序是敏感的,但是由于Mysql的查询优化器会自动调整where 子句的条件顺序以使用适合的索引,索引Mysql不存在where的顺序问题而造成索引失效。
BTree B+Tree,索引的模型结构,MyIsam和Innodb的索引区别:
MyIsam的索引文件和数据文件是分开的,Innodb表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录
参考 :深入理解MySQL索引底层实现原理
二 重构查询
一条sql查询执行的链路过程
当我们向Mysql发送一个(更新/删除/修改/增加)请求的时候,Mysql到底做了什么?

1,客户端发送一条查询给服务器
2,服务器先检查查询缓存,如果命中了缓存,则立即返回存储在缓存中的结果,否则进入到下一个阶段
3,服务器进行SQL解析,预处理,再由优化器生成对应的执行计划
4,Mysql根据优化器生成的执行计划,调用存储引擎的API来执行查询
5,将结果返回给客户端
语法解析器和预处理:

查询优化器:

分解关联查询

在很多场景下,通过重构查询讲关联放到应用程序中讲会更加高效,这样的场景有很多,比如:当应用能够方便地缓存单个查询的结果的时候,当可以讲数据分布到不同的 Mysql服务器的时候,当能够使用IN()的方式关联查询的时候,当查询中使用同一个数据库表的时候。
排序优化
无论如何排序都是一个成本很高的操作,所以从性能角度考虑,应尽可能的避免排序或者尽可能避免对大量数据进行排序。
当不能使用索引生成排序结果的时候,Mysql需要自己进行排序,如果数据量小则在内存中进行,如果数据量大则需要使用磁盘,不过Mysql将这一过程称为文件排序(filesort,可以查看使用索引扫描来进行排序),即完全是内存排序不需要任何磁盘文件时也是如此。
如果需要排序的数据量小于“排序缓存区”,Mysql使用内存进行 快速排序 操作,如果内存不够排序,那么Mysql会先将数据分块,对每个独立的快使用“快速排序”,进行排序,并将各个快的排序结果存放在磁盘上,然后将各个排序好的快进行合并,最后返回排序结果。