Kylin源码分析系列三—rowKey编码
Kylin源码分析系列三—rowKey编码
注:Kylin源码分析系列基于Kylin的2.5.0版本的源码,其他版本可以类比。
1. 相关概念
前面介绍了Kylin中Cube构建的流程,但Cube数据具体是以什么样的形式存在,可能还不是特别清晰明了,这篇文章就详细介绍下Cube数据的数据格式,主要就是其rowKey的编码,看下Kylin是怎样来保存各种维度组合下的各种度量的统计值的。这里首先介绍下Cube数据立方的相关概念。
事实表Fact Table
事实表(Fact Table)是中心表,包含了大批数据并不冗余,其数据列可分为两类:
包含大量数据事实的列;与维表(Lookup Table)的primary key相对应的foreign key。
维表Lookup Table
Lookup Table包含对事实表的某些列进行扩充说明的字段。在Kylin的quick start中给出sample cube(kylin_sales_cube)——其Fact Table为购买记录,lookup table有两个:用于对购买日期PART_DT、商品的LEAF_CATEG_ID与LSTG_SITE_ID字段进行扩展说明。
维度Dimensions
维度是观察数据的角度,一般是一组离散的值,可以类比为数据库表中的列。每个维
度都会有一组值,这里将值的个数成为维度基数(cardinatily)。同时从一个或多个维度来观察数据,则称这一个或多个维度组合成了一个维度组合,这种维度组合在Kylin中也称之为cuboid;如果有n个维度列,则理论上的维度组合有2的N次方个,这样如果维度列很多的时候维度组合的个数就会指数型膨胀,但有些维度组合的使用价值可能会有重复,有些可能就不会用到,这样就会导致资源的浪费。Kylin中针对维度的概念进行了进一步的细化,分为了普通维度Normal Dimensions,必要维度Mandatory Dimensions,层级维度Hierarchy Dimensions和联合维度Joint Dimensions,这样可以进一步减少cuboid的个数。
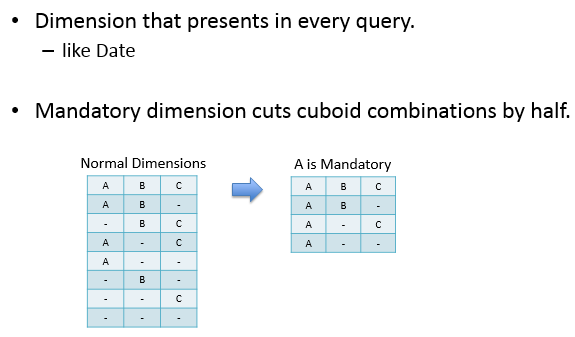
其中Mandatory Dimensions是在每次查询都会用到的维度,比如下图中A如果为Mandatory dimension,则与B、C总共构成了4个cuboid,相较于之前的cuboid(2的3次方,8)减少了一半。
Hierarchy Dimensions为带层级的维度,比如说:省份->城市, 年->季度->月->周->日;如下图所示:

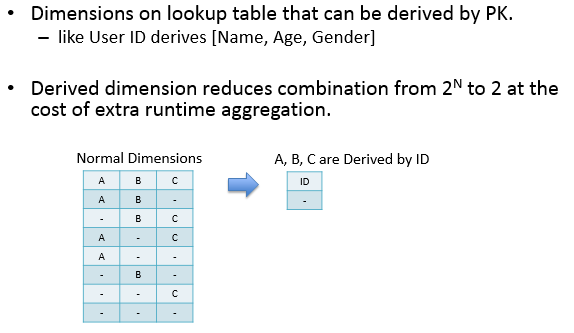
Derived Dimensions指该维度与维表的primary key是一一对应关系,可以更有效地减少cuboid数量,详细的解释参看这里;并且derived dimension只能由lookup table的列生成。如下图所示:
另外Kylin还设计了一个Aggregation Groups聚合组来进一步减少cuboid的个数。
用户根据自己关注的维度组合,可以划分出自己关注的组合大类,这些大类在 Apache Kylin 里面被称为聚合组。例如下图中展示的 Cube,如果用户仅仅关注维度 AB 组合和维度 CD 组合,那么该 Cube 则可以被分化成两个聚合组,分别是聚合组 AB 和聚合组 CD。如图 2 所示,生成的 Cuboid 数目从 16 个缩减成了 8 个。

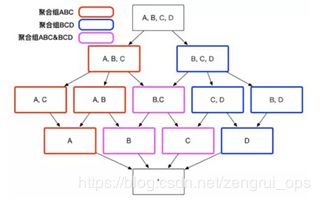
同时,用户关心的聚合组之间可能包含相同的维度,例如聚合组 ABC 和聚合组 BCD 都包含维度 B 和维度 C。这些聚合组之间会衍生出相同的 Cuboid,例如聚合组 ABC 会产生 Cuboid BC,聚合组 BCD 也会产生 Cuboid BC。这些 Cuboid不会被重复生成,一份 Cuboid 为这些聚合组所共有,如下图所示:
有了聚合组用户就可以粗粒度地对 Cuboid 进行筛选,获取自己想要的维度组合。
度量Measures
度量即为用户关心的针对某些维度组合的统计值。kylin会自动为每一个cube创建一个聚合函数为count(1)的度量(kylin设置度量的时候必须要有COUNT),它不需要关联任何列,用户自定义的度量可以选择SUM、COUNT、DISTINCT COUNT、MIN、MAX、TOP_N、RAW、EXTENDED_COLUMN、PERCENTILE,而每一个度量定义时还可以选择这些聚合函数的参数,可以选择常量或者事实表的某一列,一般情况下我们当然选择某一列。这里我们发现kylin并不提供AVG等相对较复杂的聚合函数(方差、平均差更没有了),主要是因为kylin中或有多个cube segment进行合并计生成新的cube segment,而这些复杂的聚合函数并不能简单的对两个值计算之后得到新的值,例如需要增量合并的两个cube中某一个key对应的sum值分别为A和B,那么合并之后的则为A+B,而如果此时的聚合函数是AVG,那么我们必须知道这个key的count和sum之后才能做聚合。这就要求使用者必须自己想办法自己计算了。
其中RAW度量是为了查询数据的明细值,EXTENDED_COLUMN度量是将某些维度列设置成度量,以便在使用其他列过滤但需要查询该列时使用,PERCENTILE度量是一种百分位数统计的方法。
上面讲到segment,kylin中的每个cube(逻辑上)中会包含多个segment,每个segment对应着一个物理cube,在实际存储中对应一个hbase的表,用户在构建模型的时候需要定义根据某一个字段进行增量构建(目前仅支持时间,并且这个字段必须是hive的一个分区字段),其实这个选择是作为原始数据选择的条件,例如选择起始时间A到B的数据那么创建的cube则会只包含这个时间段的数据聚合值,创建完一个cube之后可以再次基于以前的cube进行build,每次build会生成一个新的segment,只不过原始数据不一样了(根据每次build指定的时间区间),每次查询的时候会查询所有的segment聚合之后的值进行返回,但是当segment存在过多的时候查询效率就会下降,因此需要在存在多个segment的时候将它们进行合并,合并的时候其实是指定了一个时间区间,内部会选择这个时间区间内的所有segment进行合并,合并完成之后使用新的segment(新的hbase表)替换被合并的多个segment,被合并的几个segment所对应的hbase表会被删除。
2. RowKey组成
2.1 简介
Kylin中的RowKey由shard id + cuboid id + dimension values三部分组成,其中shard id有两个字节,cuboid有八个字节,dimension values为各个维度值经过编码后的值。
Shard id是每个cuboid的分片id,用户在配置rowkey的时候选择一个维度来划分分片,这样每个cuboid会被分成多个分片,对于目前的hbase存储,就是将每个cuboid的数据分成多个region来存储,这样就会分散到hbase的多个regionserver上,因为Kylin使用了hbase的协处理器来进行查询,这样可以将查询分散到各个regionserver上进行查询(过滤和聚合),提高查询速度。
Cuboid id为一个八字节的long类型值(Kylin最多支持63个维度),值的每一位表示维度组合中的一个维度,存在为1,不存在为0,假设有A、B、C、D、E、F、G、H八个维度(使用一个字节即可,前七个字节为0),对于base cuboid(包含所有的维度)的id值为11111111(255),对于维度组合A、B、C、D,cuboid为11110000(240),维度组合A、D、F、H的cuboid为10010101(149),其他的以此类推。
dimension values为各个维度的值,但并不是维度实际的值,而是经过编码后的值,Kylin这样做是为了减少数据的存储空间。
2.2 编码方式
Kylin中的编码方式包括Date编码、Time编码、Integer编码、Boolean编码、Dict编码和Fixed Length编码,用户可以根据需求选择合适的编码方式。
Date编码
将日期类型的数据使用三个字节进行编码,支持的格式包括yyyyMMdd、yyyy-MM-dd、yyyy-MM-dd HH:mm:ss、yyyy-MM-dd HH:mm:ss.SSS,其中如果包含时间戳部分会被截断。
3个字节(23位), 支持0000-01-01到9999-01-01
Time编码
对时间戳字段进行编码,4个字节,支持范围为[ 1970-01-01 00:00:00, 2038/01/19 03:14:07],毫秒部分会被忽略。time编码适用于time, datetime, timestamp等类型。
Integer编码
将数值类型字段直接用数字表示,不做编码转换。Integer编码需要提供一个额外的参数“Length”来代表需要多少个字节。Length的长度为1到8,支持的整数区间为[ -2^(8*N-1), 2^(8*N-1)]。
Dict编码
使用字典将长的值映射成短的ID,适合中低基数的维度,默认推荐编码。但由于字典要被加载到Kylin内存中,在超高基情况下,可能引起内存不足的问题。
简单使用方法:
TrieDictionaryBuilder
b.addValue("part");
b.addValue("part");
b.addValue("par");
b.addValue("partition");
b.addValue("party");
b.addValue("parties");
b.addValue("paint");
TrieDictionary
按照以上的方法构建后,会生成一颗Trie树,结构如下:
-
part - *
-
part - *
-
par - *
t - *
-
par - *
t - *
ition - *
-
par - *
t - *
ition - *
y - *
-
par - *
t - *
i -
es - *
tion - *
y - *
-
pa -
int - *
r - *
t - *
i -
es - *
tion - *
y - *
编码结果:0:paint 1:par 2:part 3:parties 4:partition 5:party
这些编码后的值为int类型。
根据编码获取实际维度值:
Bytes.toString(dict.getValueBytesFromIdWithoutCache(i))
根据维度值获取编码:
BytesConverter converter = new StringBytesConverter();
byte[] bytes = converter.convertToBytes("part");
int id = dict.getIdFromValueBytesWithoutCache(bytes, 0, bytes.length-1, 0);
字典编码为一颗Trie树,也叫字典树,是一种哈希树的变种,优点是利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
它有三个基本特性:
根节点不包含字符,除根节点外每一个节点都只包含一个字符; 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串; 每个节点的所有子节点包含的字符都不相同。
Fixed_length编码
适用于超高基数场景,将选取字段的前N个字节作为编码值,当N小于字段长度,会造成字段截断,当N较大时,造成RowKey过长,查询性能下降。只适用于varchar或nvarchar类型。
Fixed_Length_Hex编码
适用于字段值为十六进制字符,比如1A2BFF或者FF00FF,每两个字符需要一个字节。只适用于varchar或nvarchar类型。
2.3 源码解析
这里是基于spark构建引擎来进行相关分析,前面一篇文章讲过Cube构建的过程,在createFactDistinctColumnsSparkStep这一步得到了各个维度的distinct值(SparkFactDistinct、MultiOutputFunction保存字典文件),然后写到文件里面(后面构建字典使用),这里对各维度进行编码主要就是针对这些distinct值来进行,源码位于CreateDictionaryJob这个类中。看下里面的run方法:
public int run(String[] args) throws Exception {
Options options = new Options();
options.addOption(OPTION_CUBE_NAME);
options.addOption(OPTION_SEGMENT_ID);
options.addOption(OPTION_INPUT_PATH);
options.addOption(OPTION_DICT_PATH);
parseOptions(options, args);
final String cubeName = getOptionValue(OPTION_CUBE_NAME);
final String segmentID = getOptionValue(OPTION_SEGMENT_ID);
final String factColumnsInputPath = getOptionValue(OPTION_INPUT_PATH);
final String dictPath = getOptionValue(OPTION_DICT_PATH);
final KylinConfig config = KylinConfig.getInstanceFromEnv();
//对该segment进行字典的构建
DictionaryGeneratorCLI.processSegment(config, cubeName, segmentID, new DistinctColumnValuesProvider() {
@Override
//读取文件中的对应维度的distinct值
public IReadableTable getDistinctValuesFor(TblColRef col) {
// 文件路径为上一步保存distinct值的文件路径
return new SortedColumnDFSFile(factColumnsInputPath + "/" + col.getIdentity(), col.getType());
}
}, new DictionaryProvider() {
@Override
// 获取对应维度使用的编码字典
public Dictionary getDictionary(TblColRef col) throws IOException {
CubeManager cubeManager = CubeManager.getInstance(config);
CubeInstance cube = cubeManager.getCube(cubeName);
List uhcColumns = cube.getDescriptor().getAllUHCColumns();
Path colDir;
// 对于UHC维度列路径类似于
// /kylin/kylin_metadata/kylin-20240f69-5abe-6c82-56c7-
// 11c0ea0ffa42/kylin_sales_cube/dict/{colName}
if (config.isBuildUHCDictWithMREnabled() && uhcColumns.contains(col)) {
colDir = new Path(dictPath, col.getIdentity());
} else {
// 上一步保存distinct值的文件路径,类似于
// /kylin/kylin_metadata/kylin-20240f69-5abe-6c82-56c7-
// 11c0ea0ffa42/kylin_sales_cube/fact_distinct_columns/{colName}
colDir = new Path(factColumnsInputPath, col.getIdentity());
}
FileSystem fs = HadoopUtil.getWorkingFileSystem();
// 过滤以{colName}.rldict开头的文件
Path dictFile = HadoopUtil.getFilterOnlyPath(fs, colDir, col.getName() + FactDistinctColumnsReducer.DICT_FILE_POSTFIX);
if (dictFile == null) {
logger.info("Dict for '" + col.getName() + "' not pre-built.");
return null;
}
// 读取字典
try (SequenceFile.Reader reader = new SequenceFile.Reader(HadoopUtil.getCurrentConfiguration(), SequenceFile.Reader.file(dictFile))) {
NullWritable key = NullWritable.get();
ArrayPrimitiveWritable value = new ArrayPrimitiveWritable();
reader.next(key, value);
ByteBuffer buffer = new ByteArray((byte[]) value.get()).asBuffer();
try (DataInputStream is = new DataInputStream(new ByteBufferBackedInputStream(buffer))) {
String dictClassName = is.readUTF();
Dictionary dict = (Dictionary) ClassUtil.newInstance(dictClassName);
dict.readFields(is);
logger.info("DictionaryProvider read dict from file: " + dictFile);
return dict;
}
}
}
});
return 0;
}
里面主要看new DistinctColumnValuesProvider和new DictionaryProvider,DistinctColumnValuesProvider是去获取上一步保存的各维度的distinct值,DictionaryProvider是获取对应类型的字典。看下具体的处理函数processSegment:
public static void processSegment(KylinConfig config, String cubeName, String segmentID, DistinctColumnValuesProvider factTableValueProvider, DictionaryProvider dictProvider) throws IOException {
//根据cube的名称和segmentID获取对应的CubeSegment实例
CubeInstance cube = CubeManager.getInstance(config).getCube(cubeName);
CubeSegment segment = cube.getSegmentById(segmentID);
processSegment(config, segment, factTableValueProvider, dictProvider);
}
private static void processSegment(KylinConfig config, CubeSegment cubeSeg, DistinctColumnValuesProvider factTableValueProvider, DictionaryProvider dictProvider) throws IOException {
CubeManager cubeMgr = CubeManager.getInstance(config);
// dictionary
// 获取所有需要构建字典的维度列
for (TblColRef col : cubeSeg.getCubeDesc().getAllColumnsNeedDictionaryBuilt()) {
logger.info("Building dictionary for " + col);
// 读取维度列的distinct值的文件(调用前面new DistinctColumnValuesProvider()中重写的
// getDistinctValuesFor)
IReadableTable inpTable = factTableValueProvider.getDistinctValuesFor(col);
Dictionary preBuiltDict = null;
if (dictProvider != null) {
// 调用前面new DictionaryProvider()中重写的方法获取预先构建的字典,如果没有预先构
// 建会返回null
preBuiltDict = dictProvider.getDictionary(col);
}
// 如果已经构建过了则保存字典,没有则构建。字典保存的目录如:
// /kylin/kylin_metadata/kylin-20240f69-5abe-6c82-56c7-
// 11c0ea0ffa42/kylin_sales_cube/metadata/
// dict/DEFAULT.KYLIN_SALES/SELLER_ID/e7cd07a8-7ad3-5ad2-1e39-6f37e12921b1.dict
if (preBuiltDict != null) {
logger.debug("Dict for '" + col.getName() + "' has already been built, save it");
cubeMgr.saveDictionary(cubeSeg, col, inpTable, preBuiltDict);
} else {
logger.debug("Dict for '" + col.getName() + "' not pre-built, build it from " + inpTable.toString());
cubeMgr.buildDictionary(cubeSeg, col, inpTable);
}
}
// snapshot lookup tables
......
}
到这一步各个需要进行字段编码的维度的字典就构建好了,后面再计算Cube,拼接RowKey的时候直接使用这里的字典来获取对应维度值的编码值。下面接着看下Cube数据的RowKey是怎么拼接的。前面Cube构建的文章中讲述了构建的过程,这里直接看SparkCubingByLayer中execute方法调用的EncodeBaseCuboid的call方法:
public Tuple2 call(String[] rowArray) throws Exception {
if (initialized == false) {
synchronized (SparkCubingByLayer.class) {
if (initialized == false) {
KylinConfig kConfig = AbstractHadoopJob.loadKylinConfigFromHdfs(conf, metaUrl);
try (KylinConfig.SetAndUnsetThreadLocalConfig autoUnset = KylinConfig
.setAndUnsetThreadLocalConfig(kConfig)) {
CubeInstance cubeInstance = CubeManager.getInstance(kConfig).getCube(cubeName);
CubeDesc cubeDesc = cubeInstance.getDescriptor();
CubeSegment cubeSegment = cubeInstance.getSegmentById(segmentId);
CubeJoinedFlatTableEnrich interDesc = new CubeJoinedFlatTableEnrich(
EngineFactory.getJoinedFlatTableDesc(cubeSegment), cubeDesc);
// 计算出base cuboid id
long baseCuboidId = Cuboid.getBaseCuboidId(cubeDesc);
Cuboid baseCuboid = Cuboid.findForMandatory(cubeDesc, baseCuboidId);
baseCuboidBuilder = new BaseCuboidBuilder(kConfig, cubeDesc, cubeSegment, interDesc,
AbstractRowKeyEncoder.createInstance(cubeSegment, baseCuboid),
MeasureIngester.create(cubeDesc.getMeasures()), cubeSegment.buildDictionaryMap());
initialized = true;
}
}
}
}
baseCuboidBuilder.resetAggrs();
// 根据Hive中读出的RDD(所有的维度列值)进行处理。
// 这里的rowKey为shard id + cuboid id + values
byte[] rowKey = baseCuboidBuilder.buildKey(rowArray);
Object[] result = baseCuboidBuilder.buildValueObjects(rowArray);
return new Tuple2<>(new ByteArray(rowKey), result);
}
接着看BaseCuboidBuilder 的buildKey函数:
public byte[] buildKey(String[] flatRow) {
int[] rowKeyColumnIndexes = intermediateTableDesc.getRowKeyColumnIndexes();
List columns = baseCuboid.getColumns();
String[] colValues = new String[columns.size()];
for (int i = 0; i < columns.size(); i++) {
colValues[i] = getCell(rowKeyColumnIndexes[i], flatRow);
}
//rowKey编码
return rowKeyEncoder.encode(colValues);
}
接着调用RowKeyEncoder的encode方法:
public byte[] encode(String[] values) {
byte[] bytes = new byte[this.getBytesLength()];
//header部分有(shard id和cuboid id, 2字节+8字节)
int offset = getHeaderLength();
for (int i = 0; i < cuboid.getColumns().size(); i++) {
TblColRef column = cuboid.getColumns().get(i);
int colLength = colIO.getColumnLength(column);
//这里填入各个维度列的编码值
fillColumnValue(column, colLength, values[i], bytes, offset);
offset += colLength;
}
//fill shard id and cuboid id
fillHeader(bytes);
return bytes;
}
看下fillColumnValue函数:
protected void fillColumnValue(TblColRef column, int columnLen, String valueStr, byte[] outputValue, int outputValueOffset) {
// special null value case
if (valueStr == null) {
Arrays.fill(outputValue, outputValueOffset, outputValueOffset + columnLen, defaultValue());
return;
}
colIO.writeColumn(column, valueStr, 0, this.blankByte, outputValue, outputValueOffset);
}
最终的填入编码值就在RowKeyColumnIO的wireColumn函数中:
public void writeColumn(TblColRef col, String value, int roundingFlag, byte defaultValue, byte[] output, int outputOffset) {
// 获取维度列的编码方法,调用CubeDimEncMap的get方法
DimensionEncoding dimEnc = dimEncMap.get(col);
if (dimEnc instanceof DictionaryDimEnc)
dimEnc = ((DictionaryDimEnc) dimEnc).copy(roundingFlag, defaultValue);
// 调用对应的encode方法对维度值进行编码
dimEnc.encode(value, output, outputOffset);
}
这里看下字典编码方式(其他的编码方式类似),dimEnc为DictionaryDimEnc,看下encode方法:
public void encode(String valueStr, byte[] output, int outputOffset) {
try {
// 根据字典获取维度值的编码值,最后将int类型的编码值转换成byte数组
int id = dict.getIdFromValue(valueStr, roundingFlag);
BytesUtil.writeUnsigned(id, output, outputOffset, fixedLen);
} catch (IllegalArgumentException ex) {
for (int i = outputOffset; i < outputOffset + fixedLen; i++) {
output[i] = defaultByte;
}
logger.error("Can't translate value " + valueStr + " to dictionary ID, roundingFlag " + roundingFlag + ". Using default value " + String.format("\\x%02X", defaultByte));
}
// 若num为300, bytes为byte[2], offset为0, size为2
public static void writeUnsigned(int num, byte[] bytes, int offset, int size) {
for (int i = offset + size - 1; i >= offset; i--) {
// bytes[1]为44, num右移8位后为1, bytes[0]为1
bytes[i] = (byte) num;
num >>>= 8;
}
}
这里就完成了Cube的Base Cuboid的RowKey的编码工作,后面的各个层级的cuboid的RowKey的值均根据Base Cuboid的RowKey变换而来,Cube查询的时候也是使用这些RowKey值到hbase查询相关的数据。
看完RowKey的编码,顺便看下对应的度量值是怎么保存的,在计算完各个层级的cube数据后各个RDD的格式为JavaPairRDD
protected void execute(OptionsHelper optionsHelper) throws Exception {
. . .
// 从上一步保存的cuboid文件中读出cube数据
JavaPairRDD inputRDDs = SparkUtil.parseInputPath(inputPath, fs, sc, Text.class, Text.class);
// 转换为hfile的格式
final JavaPairRDD hfilerdd;
if (quickPath) {
// 只有一个Column Family
hfilerdd = inputRDDs.mapToPair(new PairFunction, RowKeyWritable, KeyValue>() {
@Override
public Tuple2 call(Tuple2 textTextTuple2) throws Exception {
KeyValue outputValue = keyValueCreators.get(0).create(textTextTuple2._1,
textTextTuple2._2.getBytes(), 0, textTextTuple2._2.getLength());
return new Tuple2<>(new RowKeyWritable(outputValue.createKeyOnly(false).getKey()), outputValue);
}
});
} else {
hfilerdd = inputRDDs.flatMapToPair(new PairFlatMapFunction, RowKeyWritable, KeyValue>() {
@Override
public Iterator> call(Tuple2 textTextTuple2)
throws Exception {
List> result = Lists.newArrayListWithExpectedSize(cfNum);
Object[] inputMeasures = new Object[cubeDesc.getMeasures().size()];
// 从字节数组中反序列化出所有的度量值
inputCodec.decode(ByteBuffer.wrap(textTextTuple2._2.getBytes(), 0, textTextTuple2._2.getLength()),
inputMeasures);
for (int i = 0; i < cfNum; i++) {
// 创建KeyValue,里面的value值又被序列化为ByteBuffer
KeyValue outputValue = keyValueCreators.get(i).create(textTextTuple2._1, inputMeasures);
result.add(new Tuple2<>(new RowKeyWritable(outputValue.createKeyOnly(false).getKey()),
outputValue));
}
return result.iterator();
}
});
}
hfilerdd.repartitionAndSortWithinPartitions(new HFilePartitioner(keys),
RowKeyWritable.RowKeyComparator.INSTANCE)
.mapToPair(new PairFunction, ImmutableBytesWritable, KeyValue>() {
@Override
public Tuple2 call(
Tuple2 rowKeyWritableKeyValueTuple2) throws Exception {
return new Tuple2<>(new ImmutableBytesWritable(rowKeyWritableKeyValueTuple2._2.getKey()),
rowKeyWritableKeyValueTuple2._2);
}
}).saveAsNewAPIHadoopDataset(job.getConfiguration());
logger.info("HDFS: Number of bytes written=" + jobListener.metrics.getBytesWritten());
Map counterMap = Maps.newHashMap();
counterMap.put(ExecutableConstants.HDFS_BYTES_WRITTEN, String.valueOf(jobListener.metrics.getBytesWritten()));
// save counter to hdfs
HadoopUtil.writeToSequenceFile(sc.hadoopConfiguration(), counterPath, counterMap);
//HadoopUtil.deleteHDFSMeta(metaUrl);
}
2.4 总结
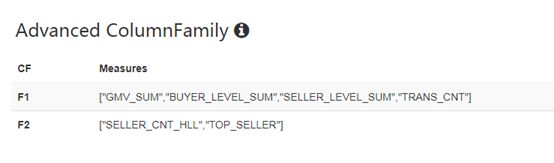
上面就是Kylin中Cube数据的RowKey和各个度量值的编码保存过程,cube数据最后存储在hbase中,通过hbase shell查看形式如下:
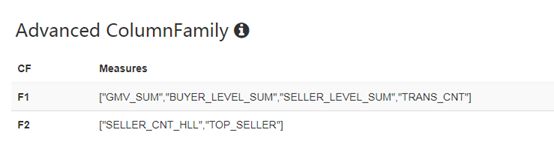
前面是RowKey值,后面是ColumnFamily和Qualifier,看到有两个(F1:M和F2:M),与前面创建cube时的配置一致。前面Cube配置如下: