Kylin源码分析系列四—Cube查询
Kylin源码分析系列四—Cube查询
注:Kylin源码分析系列基于Kylin的2.5.0版本的源码,其他版本可以类比。
一. 简介
前面文章介绍了Cube是如何构建的,那构建完成后用户肯定是需要对这些预统计的数据进行相关的查询操作,这篇文章就介绍下Kylin中是怎样通过SQL语句来进行Cube数据的查询的。Kylin中的查询是在web页面上输入sql语句然后提交来执行相关查询,页面上的提交也是向Kylin的Rest Server发送restful请求,方法与前面文章介绍的Cube构建的触发方式类似,通过angularJS发送restful请求,请求url为/kylin/api/query,Kylin的Rest Server接收到该请求后,进行Cube数据的查询。
Kylin中使用的是Apache Calcite查询引擎。Apache Calcite是面向 Hadoop 的查询引擎,它提供了标准的 SQL 语言、多种查询优化和连接各种数据源的能力,除此之外,Calcite 还提供了 OLAP 和流处理的查询引擎。
Apache Calcite具有以下几个技术特性
- 支持标准SQL 语言;
- 独立于编程语言和数据源,可以支持不同的前端和后端;
- 支持关系代数、可定制的逻辑规划规则和基于成本模型优化的查询引擎;
- 支持物化视图(materialized view)的管理(创建、丢弃、持久化和自动识别);
- 基于物化视图的 Lattice 和 Tile 机制,以应用于 OLAP 分析;
- 支持对流数据的查询。
这里不详细介绍每个特性,读者可以自行去学习了解。Kylin之所以选择这个查询引擎正是由于Calcite 可以很好地支持物化视图和星模式这些 OLAP 分析的关键特性。
二. 源码解析
Rest Server接收到查询的RestFul请求后,根据url将其分发到QueryController控制器来进行处理:
@RequestMapping(value = "/query", method = RequestMethod.POST, produces = { "application/json" })
@ResponseBody
public SQLResponse query(@RequestBody PrepareSqlRequest sqlRequest) {
return queryService.doQueryWithCache(sqlRequest);
}
后面就由QueryService来进行查询处理:
public SQLResponse doQueryWithCache(SQLRequest sqlRequest) {
long t = System.currentTimeMillis();
//检查权限
aclEvaluate.checkProjectReadPermission(sqlRequest.getProject());
logger.info("Check query permission in " + (System.currentTimeMillis() - t) + " ms.");
return doQueryWithCache(sqlRequest, false);
}
public SQLResponse doQueryWithCache(SQLRequest sqlRequest, boolean isQueryInspect) {
Message msg = MsgPicker.getMsg();
// 获取用户名
sqlRequest.setUsername(getUserName());
KylinConfig kylinConfig = KylinConfig.getInstanceFromEnv();
String serverMode = kylinConfig.getServerMode();
// 服务模式不为query和all的无法进行查询
if (!(Constant.SERVER_MODE_QUERY.equals(serverMode.toLowerCase())
|| Constant.SERVER_MODE_ALL.equals(serverMode.toLowerCase()))) {
throw new BadRequestException(String.format(msg.getQUERY_NOT_ALLOWED(), serverMode));
}
// project不能为空
if (StringUtils.isBlank(sqlRequest.getProject())) {
throw new BadRequestException(msg.getEMPTY_PROJECT_NAME());
}
// project not found
ProjectManager mgr = ProjectManager.getInstance(KylinConfig.getInstanceFromEnv());
if (mgr.getProject(sqlRequest.getProject()) == null) {
throw new BadRequestException(msg.getPROJECT_NOT_FOUND());
}
// sql语句不能为空
if (StringUtils.isBlank(sqlRequest.getSql())) {
throw new BadRequestException(msg.getNULL_EMPTY_SQL());
}
// 用于保存用户查询输入的相关参数,一般用于调试
if (sqlRequest.getBackdoorToggles() != null)
BackdoorToggles.addToggles(sqlRequest.getBackdoorToggles());
// 初始化查询上下文,设置了queryId和queryStartMillis
final QueryContext queryContext = QueryContextFacade.current();
// 设置新的查询线程名
try (SetThreadName ignored = new SetThreadName("Query %s", queryContext.getQueryId())) {
SQLResponse sqlResponse = null;
// 获取查询的sql语句
String sql = sqlRequest.getSql();
String project = sqlRequest.getProject();
// 是否开启了查询缓存,kylin.query.cache-enabled默认开启
boolean isQueryCacheEnabled = isQueryCacheEnabled(kylinConfig);
logger.info("Using project: " + project);
logger.info("The original query: " + sql);
// 移除sql语句中的注释
sql = QueryUtil.removeCommentInSql(sql);
Pair result = TempStatementUtil.handleTempStatement(sql, kylinConfig);
boolean isCreateTempStatement = result.getFirst();
sql = result.getSecond();
sqlRequest.setSql(sql);
// try some cheap executions
if (sqlResponse == null && isQueryInspect) {
sqlResponse = new SQLResponse(null, null, 0, false, sqlRequest.getSql());
}
if (sqlResponse == null && isCreateTempStatement) {
sqlResponse = new SQLResponse(null, null, 0, false, null);
}
// 缓存中直接查询
if (sqlResponse == null && isQueryCacheEnabled) {
sqlResponse = searchQueryInCache(sqlRequest);
}
// real execution if required
if (sqlResponse == null) {
// 并发查询限制, kylin.query.project-concurrent-running-threshold, 默认为0, 无
// 限制
try (QueryRequestLimits limit = new QueryRequestLimits(sqlRequest.getProject())) {
// 查询,如有必要更新缓存
sqlResponse = queryAndUpdateCache(sqlRequest, isQueryCacheEnabled);
}
}
sqlResponse.setDuration(queryContext.getAccumulatedMillis());
logQuery(queryContext.getQueryId(), sqlRequest, sqlResponse);
try {
recordMetric(sqlRequest, sqlResponse);
} catch (Throwable th) {
logger.warn("Write metric error.", th);
}
if (sqlResponse.getIsException())
throw new InternalErrorException(sqlResponse.getExceptionMessage());
return sqlResponse;
} finally {
BackdoorToggles.cleanToggles();
QueryContextFacade.resetCurrent();
}
}
下面接着调用queryAndUpdateCache,看下具体源码:
private SQLResponse queryAndUpdateCache(SQLRequest sqlRequest, boolean queryCacheEnabled) {
KylinConfig kylinConfig = KylinConfig.getInstanceFromEnv();
Message msg = MsgPicker.getMsg();
final QueryContext queryContext = QueryContextFacade.current();
SQLResponse sqlResponse = null;
try {
// 判断是不是select查询语句
final boolean isSelect = QueryUtil.isSelectStatement(sqlRequest.getSql());
if (isSelect) {
sqlResponse = query(sqlRequest, queryContext.getQueryId());
// 查询下推到其他的查询引擎,比如直接通过hive查询
} else if (kylinConfig.isPushDownEnabled() && kylinConfig.isPushDownUpdateEnabled()) {
sqlResponse = update(sqlRequest);
} else {
logger.debug("Directly return exception as the sql is unsupported, and query pushdown is disabled");
throw new BadRequestException(msg.getNOT_SUPPORTED_SQL());
}
. . .
return sqlResponse;
}
public SQLResponse query(SQLRequest sqlRequest, String queryId) throws Exception {
SQLResponse ret = null;
try {
final String user = SecurityContextHolder.getContext().getAuthentication().getName();
// 加入到查询队列,BadQueryDetector会对该查询进行检测,看是否超时或是否为慢查询(默认
// 90S)
badQueryDetector.queryStart(Thread.currentThread(), sqlRequest, user, queryId);
ret = queryWithSqlMassage(sqlRequest);
return ret;
} finally {
String badReason = (ret != null && ret.isPushDown()) ? BadQueryEntry.ADJ_PUSHDOWN : null;
badQueryDetector.queryEnd(Thread.currentThread(), badReason);
Thread.interrupted(); //reset if interrupted
}
}
private SQLResponse executeRequest(String correctedSql, SQLRequest sqlRequest, Connection conn) throws Exception {
Statement stat = null;
ResultSet resultSet = null;
boolean isPushDown = false;
Pair>, List> r = null;
try {
stat = conn.createStatement();
processStatementAttr(stat, sqlRequest);
resultSet = stat.executeQuery(correctedSql);
r = createResponseFromResultSet(resultSet);
} catch (SQLException sqlException) {
r = pushDownQuery(sqlRequest, correctedSql, conn, sqlException);
if (r == null)
throw sqlException;
isPushDown = true;
} finally {
close(resultSet, stat, null); //conn is passed in, not my duty to close
}
return buildSqlResponse(isPushDown, r.getFirst(), r.getSecond());
}
stat.executeQuery(correctedSql)接着就是calcite对SQL语句的解析优化处理,该部分内容这里不详细描述,具体的堆栈信息如下:

下面接着看OLAPEnumerator中的queryStorage:
private ITupleIterator queryStorage() {
logger.debug("query storage...");
// bind dynamic variables
olapContext.bindVariable(optiqContext);
olapContext.resetSQLDigest();
SQLDigest sqlDigest = olapContext.getSQLDigest();
// query storage engine
// storageEngine为CubeStorageQuery,继承GTCubeStorageQueryBase
IStorageQuery storageEngine = StorageFactory.createQuery(olapContext.realization);
ITupleIterator iterator = storageEngine.search(olapContext.storageContext, sqlDigest,
olapContext.returnTupleInfo);
if (logger.isDebugEnabled()) {
logger.debug("return TupleIterator...");
}
return iterator;
}
然后调用GTCubeStorageQueryBase的search方法,在该方法中为每个cube segment创建一个CubeSegmentScanner:
public ITupleIterator search(StorageContext context, SQLDigest sqlDigest, TupleInfo returnTupleInfo) {
// 这一步有个很重要的步骤就是根据查询条件找到对应的cuboid(findCuboid)
GTCubeStorageQueryRequest request = getStorageQueryRequest(context, sqlDigest, returnTupleInfo);
List scanners = Lists.newArrayList();
SegmentPruner segPruner = new SegmentPruner(sqlDigest.filter);
for (CubeSegment cubeSeg : segPruner.listSegmentsForQuery(cubeInstance)) {
CubeSegmentScanner scanner;
scanner = new CubeSegmentScanner(cubeSeg, request.getCuboid(), request.getDimensions(), //
request.getGroups(), request.getDynGroups(), request.getDynGroupExprs(), //
request.getMetrics(), request.getDynFuncs(), //
request.getFilter(), request.getHavingFilter(), request.getContext());
if (!scanner.isSegmentSkipped())
scanners.add(scanner);
}
if (scanners.isEmpty())
return ITupleIterator.EMPTY_TUPLE_ITERATOR;
return new SequentialCubeTupleIterator(scanners, request.getCuboid(), request.getDimensions(),
request.getDynGroups(), request.getGroups(), request.getMetrics(), returnTupleInfo, request.getContext(), sqlDigest);
}
public CubeSegmentScanner(CubeSegment cubeSeg, Cuboid cuboid, Set dimensions, //
Set groups, List dynGroups, List dynGroupExprs, //
Collection metrics, List dynFuncs, //
TupleFilter originalfilter, TupleFilter havingFilter, StorageContext context) {
logger.info("Init CubeSegmentScanner for segment {}", cubeSeg.getName());
this.cuboid = cuboid;
this.cubeSeg = cubeSeg;
//the filter might be changed later in this CubeSegmentScanner (In ITupleFilterTransformer)
//to avoid issues like in https://issues.apache.org/jira/browse/KYLIN-1954, make sure each CubeSegmentScanner
//is working on its own copy
byte[] serialize = TupleFilterSerializer.serialize(originalfilter, StringCodeSystem.INSTANCE);
TupleFilter filter = TupleFilterSerializer.deserialize(serialize, StringCodeSystem.INSTANCE);
// translate FunctionTupleFilter to IN clause
ITupleFilterTransformer translator = new BuiltInFunctionTransformer(cubeSeg.getDimensionEncodingMap());
filter = translator.transform(filter);
CubeScanRangePlanner scanRangePlanner;
try {
scanRangePlanner = new CubeScanRangePlanner(cubeSeg, cuboid, filter, dimensions, groups, dynGroups,
dynGroupExprs, metrics, dynFuncs, havingFilter, context);
} catch (RuntimeException e) {
throw e;
} catch (Exception e) {
throw new RuntimeException(e);
}
scanRequest = scanRangePlanner.planScanRequest();
// gtStorage为配置项kylin.storage.hbase.gtstorage, 默认值为
// org.apache.kylin.storage.hbase.cube.v2.CubeHBaseEndpointRPC
String gtStorage = ((GTCubeStorageQueryBase) context.getStorageQuery()).getGTStorage();
scanner = new ScannerWorker(cubeSeg, cuboid, scanRequest, gtStorage, context);
}
然后在CubeSegmentScanner中构建ScannerWorker:
public ScannerWorker(ISegment segment, Cuboid cuboid, GTScanRequest scanRequest, String gtStorage,
StorageContext context) {
inputArgs = new Object[] { segment, cuboid, scanRequest, gtStorage, context };
if (scanRequest == null) {
logger.info("Segment {} will be skipped", segment);
internal = new EmptyGTScanner();
return;
}
final GTInfo info = scanRequest.getInfo();
try {
// 这里的rpc为org.apache.kylin.storage.hbase.cube.v2.CubeHBaseEndpointRPC
IGTStorage rpc = (IGTStorage) Class.forName(gtStorage)
.getConstructor(ISegment.class, Cuboid.class, GTInfo.class, StorageContext.class)
.newInstance(segment, cuboid, info, context); // default behavior
// internal为每个segment的查询结果,后面会调用iterator获取结果,calcite会将各个segment
// 的结果进行聚合, EnumerableDefaults中的aggregate
internal = rpc.getGTScanner(scanRequest);
} catch (Exception e) {
throw new RuntimeException(e);
}
checkNPE();
}
接着调用CubeHBaseEndpointRPC中的getGTScanner方法,然后调用runEPRange方法:
private void runEPRange(final QueryContext queryContext, final String logHeader, final boolean compressionResult,
final CubeVisitProtos.CubeVisitRequest request, final Connection conn, byte[] startKey, byte[] endKey,
final ExpectedSizeIterator epResultItr) {
final String queryId = queryContext.getQueryId();
try {
final Table table = conn.getTable(TableName.valueOf(cubeSeg.getStorageLocationIdentifier()),
HBaseConnection.getCoprocessorPool());
table.coprocessorService(CubeVisitService.class, startKey, endKey, //
new Batch.Call() {
public CubeVisitResponse call(CubeVisitService rowsService) throws IOException {
. . .
ServerRpcController controller = new ServerRpcController();
BlockingRpcCallback rpcCallback = new BlockingRpcCallback<>();
try {
//发送请求到hbase的协处理器进行数据查询
rowsService.visitCube(controller, request, rpcCallback);
CubeVisitResponse response = rpcCallback.get();
if (controller.failedOnException()) {
throw controller.getFailedOn();
}
return response;
} catch (Exception e) {
throw e;
} finally {
// Reset the interrupted state
Thread.interrupted();
}
}
}, new Batch.Callback() {
// 接收到协处理器发回的查询结果
@Override
public void update(byte[] region, byte[] row, CubeVisitResponse result) {
. . .
// 获取hbase协处理器返回的查询结果中的相关状态数据
Stats stats = result.getStats();
queryContext.addAndGetScannedRows(stats.getScannedRowCount());
queryContext.addAndGetScannedBytes(stats.getScannedBytes());
queryContext.addAndGetReturnedRows(stats.getScannedRowCount()
- stats.getAggregatedRowCount() - stats.getFilteredRowCount());
RuntimeException rpcException = null;
if (result.getStats().getNormalComplete() != 1) {
// record coprocessor error if happened
rpcException = getCoprocessorException(result);
}
queryContext.addRPCStatistics(storageContext.ctxId, stats.getHostname(),
cubeSeg.getCubeDesc().getName(), cubeSeg.getName(), cuboid.getInputID(),
cuboid.getId(), storageContext.getFilterMask(), rpcException,
stats.getServiceEndTime() - stats.getServiceStartTime(), 0,
stats.getScannedRowCount(),
stats.getScannedRowCount() - stats.getAggregatedRowCount()
- stats.getFilteredRowCount(),
stats.getAggregatedRowCount(), stats.getScannedBytes());
if (queryContext.getScannedBytes() > cubeSeg.getConfig().getQueryMaxScanBytes()) {
rpcException = new ResourceLimitExceededException(
"Query scanned " + queryContext.getScannedBytes() + " bytes exceeds threshold "
+ cubeSeg.getConfig().getQueryMaxScanBytes());
} else if (queryContext.getReturnedRows() > cubeSeg.getConfig().getQueryMaxReturnRows()) {
rpcException = new ResourceLimitExceededException(
"Query returned " + queryContext.getReturnedRows() + " rows exceeds threshold "
+ cubeSeg.getConfig().getQueryMaxReturnRows());
}
if (rpcException != null) {
queryContext.stop(rpcException);
return;
}
try {
// 对返回的查询结果数据进行处理(查询结果数据可能被压缩)
if (compressionResult) {
epResultItr.append(CompressionUtils.decompress(
HBaseZeroCopyByteString.zeroCopyGetBytes(result.getCompressedRows())));
} else {
epResultItr.append(
HBaseZeroCopyByteString.zeroCopyGetBytes(result.getCompressedRows()));
}
} catch (IOException | DataFormatException e) {
throw new RuntimeException(logHeader + "Error when decompressing", e);
}
}
});
} catch (Throwable ex) {
queryContext.stop(ex);
}
. . .
}
Kylin通过发送visitCube请求到HBase协处理器进行查询,协处理器中执行的函数位于CubeVisitService中,函数名为visitCube:
public void visitCube(final RpcController controller, final CubeVisitProtos.CubeVisitRequest request,
RpcCallback done) {
List regionScanners = Lists.newArrayList();
HRegion region = null;
StringBuilder sb = new StringBuilder();
byte[] allRows;
String debugGitTag = "";
CubeVisitProtos.CubeVisitResponse.ErrorInfo errorInfo = null;
// if user change kylin.properties on kylin server, need to manually redeploy coprocessor jar to update KylinConfig of Env.
KylinConfig kylinConfig = KylinConfig.createKylinConfig(request.getKylinProperties());
// 获取请求中的查询ID
String queryId = request.hasQueryId() ? request.getQueryId() : "UnknownId";
logger.info("start query {} in thread {}", queryId, Thread.currentThread().getName());
try (SetAndUnsetThreadLocalConfig autoUnset = KylinConfig.setAndUnsetThreadLocalConfig(kylinConfig);
SetThreadName ignored = new SetThreadName("Query %s", queryId)) {
final long serviceStartTime = System.currentTimeMillis();
region = (HRegion) env.getRegion();
region.startRegionOperation();
debugGitTag = region.getTableDesc().getValue(IRealizationConstants.HTableGitTag);
final GTScanRequest scanReq = GTScanRequest.serializer
.deserialize(ByteBuffer.wrap(HBaseZeroCopyByteString.zeroCopyGetBytes(request.getGtScanRequest())));
// 获取查询超时时间
final long deadline = scanReq.getStartTime() + scanReq.getTimeout();
checkDeadline(deadline);
List> hbaseColumnsToGT = Lists.newArrayList();
// 获取要查询的hbase的 Column列(例如,F1:M)
for (IntList intList : request.getHbaseColumnsToGTList()) {
hbaseColumnsToGT.add(intList.getIntsList());
}
StorageSideBehavior behavior = StorageSideBehavior.valueOf(scanReq.getStorageBehavior());
// 从request请求体中获RawScan
final List hbaseRawScans = deserializeRawScans(
ByteBuffer.wrap(HBaseZeroCopyByteString.zeroCopyGetBytes(request.getHbaseRawScan())));
appendProfileInfo(sb, "start latency: " + (serviceStartTime - scanReq.getStartTime()), serviceStartTime);
final List cellListsForeachRawScan = Lists.newArrayList();
for (RawScan hbaseRawScan : hbaseRawScans) {
if (request.getRowkeyPreambleSize() - RowConstants.ROWKEY_CUBOIDID_LEN > 0) {
//if has shard, fill region shard to raw scan start/end
updateRawScanByCurrentRegion(hbaseRawScan, region,
request.getRowkeyPreambleSize() - RowConstants.ROWKEY_CUBOIDID_LEN);
}
// 根据RawScan来构建HBase的Scan(确定startRow,stopRow,fuzzyKeys和hbase
// columns)
Scan scan = CubeHBaseRPC.buildScan(hbaseRawScan);
RegionScanner innerScanner = region.getScanner(scan);
regionScanners.add(innerScanner);
InnerScannerAsIterator cellListIterator = new InnerScannerAsIterator(innerScanner);
cellListsForeachRawScan.add(cellListIterator);
}
final Iterator> allCellLists = Iterators.concat(cellListsForeachRawScan.iterator());
if (behavior.ordinal() < StorageSideBehavior.SCAN.ordinal()) {
//this is only for CoprocessorBehavior.RAW_SCAN case to profile hbase scan speed
List| temp = Lists.newArrayList();
int counter = 0;
for (RegionScanner innerScanner : regionScanners) {
while (innerScanner.nextRaw(temp)) {
counter++;
}
}
appendProfileInfo(sb, "scanned " + counter, serviceStartTime);
}
if (behavior.ordinal() < StorageSideBehavior.SCAN_FILTER_AGGR_CHECKMEM.ordinal()) {
scanReq.disableAggCacheMemCheck(); // disable mem check if so told
}
final long storagePushDownLimit = scanReq.getStoragePushDownLimit();
ResourceTrackingCellListIterator cellListIterator = new ResourceTrackingCellListIterator(allCellLists,
scanReq.getStorageScanRowNumThreshold(), // for old client (scan threshold)
!request.hasMaxScanBytes() ? Long.MAX_VALUE : request.getMaxScanBytes(), // for new client
deadline);
IGTStore store = new HBaseReadonlyStore(cellListIterator, scanReq, hbaseRawScans.get(0).hbaseColumns,
hbaseColumnsToGT, request.getRowkeyPreambleSize(), behavior.delayToggledOn(),
request.getIsExactAggregate());
IGTScanner rawScanner = store.scan(scanReq);
// 这里会根据查询中是否有聚合来将rawScanner进行包装,包装成GTAggregateScanner来对这个
// region中查询出来的数据进行聚合操作
IGTScanner finalScanner = scanReq.decorateScanner(rawScanner, behavior.filterToggledOn(),
behavior.aggrToggledOn(), false, request.getSpillEnabled());
ByteBuffer buffer = ByteBuffer.allocate(BufferedMeasureCodec.DEFAULT_BUFFER_SIZE);
ByteArrayOutputStream outputStream = new ByteArrayOutputStream(BufferedMeasureCodec.DEFAULT_BUFFER_SIZE);//ByteArrayOutputStream will auto grow
long finalRowCount = 0L;
try {
// 对查询的每条Record进行处理
for (GTRecord oneRecord : finalScanner) {
buffer.clear();
try {
oneRecord.exportColumns(scanReq.getColumns(), buffer);
} catch (BufferOverflowException boe) {
buffer = ByteBuffer.allocate(oneRecord.sizeOf(scanReq.getColumns()) * 2);
oneRecord.exportColumns(scanReq.getColumns(), buffer);
}
outputStream.write(buffer.array(), 0, buffer.position());
finalRowCount++;
//if it's doing storage aggr, then should rely on GTAggregateScanner's limit check
if (!scanReq.isDoingStorageAggregation()
&& (scanReq.getStorageLimitLevel() != StorageLimitLevel.NO_LIMIT
&& finalRowCount >= storagePushDownLimit)) {
//read one more record than limit
logger.info("The finalScanner aborted because storagePushDownLimit is satisfied");
break;
}
}
} catch (KylinTimeoutException e) {
logger.info("Abort scan: {}", e.getMessage());
errorInfo = CubeVisitProtos.CubeVisitResponse.ErrorInfo.newBuilder()
.setType(CubeVisitProtos.CubeVisitResponse.ErrorType.TIMEOUT).setMessage(e.getMessage())
.build();
} catch (ResourceLimitExceededException e) {
logger.info("Abort scan: {}", e.getMessage());
errorInfo = CubeVisitProtos.CubeVisitResponse.ErrorInfo.newBuilder()
.setType(CubeVisitProtos.CubeVisitResponse.ErrorType.RESOURCE_LIMIT_EXCEEDED)
.setMessage(e.getMessage()).build();
} finally {
finalScanner.close();
}
long rowCountBeforeAggr = finalScanner instanceof GTAggregateScanner
? ((GTAggregateScanner) finalScanner).getInputRowCount()
: finalRowCount;
appendProfileInfo(sb, "agg done", serviceStartTime);
logger.info("Total scanned {} rows and {} bytes", cellListIterator.getTotalScannedRowCount(),
cellListIterator.getTotalScannedRowBytes());
//outputStream.close() is not necessary
byte[] compressedAllRows;
if (errorInfo == null) {
allRows = outputStream.toByteArray();
} else {
allRows = new byte[0];
}
if (!kylinConfig.getCompressionResult()) {
compressedAllRows = allRows;
} else {
// 对结果进行压缩传输,减少网络传输数据量
compressedAllRows = CompressionUtils.compress(allRows);
}
appendProfileInfo(sb, "compress done", serviceStartTime);
logger.info("Size of final result = {} ({} before compressing)", compressedAllRows.length, allRows.length);
OperatingSystemMXBean operatingSystemMXBean = (OperatingSystemMXBean) ManagementFactory
.getOperatingSystemMXBean();
double systemCpuLoad = operatingSystemMXBean.getSystemCpuLoad();
double freePhysicalMemorySize = operatingSystemMXBean.getFreePhysicalMemorySize();
double freeSwapSpaceSize = operatingSystemMXBean.getFreeSwapSpaceSize();
appendProfileInfo(sb, "server stats done", serviceStartTime);
sb.append(" debugGitTag:" + debugGitTag);
CubeVisitProtos.CubeVisitResponse.Builder responseBuilder = CubeVisitProtos.CubeVisitResponse.newBuilder();
if (errorInfo != null) {
responseBuilder.setErrorInfo(errorInfo);
}
// 向请求端发送查询结果
done.run(responseBuilder.//
setCompressedRows(HBaseZeroCopyByteString.wrap(compressedAllRows)).//too many array copies
setStats(CubeVisitProtos.CubeVisitResponse.Stats.newBuilder()
.setFilteredRowCount(cellListIterator.getTotalScannedRowCount() - rowCountBeforeAggr)
.setAggregatedRowCount(rowCountBeforeAggr - finalRowCount)
.setScannedRowCount(cellListIterator.getTotalScannedRowCount())
.setScannedBytes(cellListIterator.getTotalScannedRowBytes())
.setServiceStartTime(serviceStartTime).setServiceEndTime(System.currentTimeMillis())
.setSystemCpuLoad(systemCpuLoad).setFreePhysicalMemorySize(freePhysicalMemorySize)
.setFreeSwapSpaceSize(freeSwapSpaceSize)
.setHostname(InetAddress.getLocalHost().getHostName()).setEtcMsg(sb.toString())
.setNormalComplete(errorInfo == null ? 1 : 0).build())
.build());
} catch (DoNotRetryIOException e) {
. . .
} catch (IOException ioe) {
. . .
} finally {
. . .
}
. . .
}
}
| 例子:
Cube的涉及维度如下:

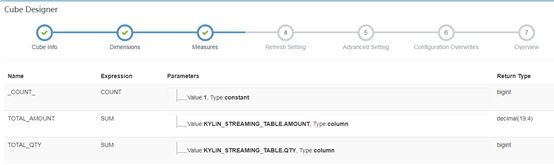
度量为:
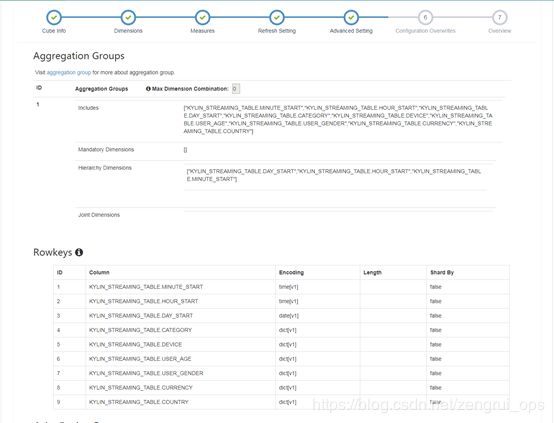
维度和rowKey设计如下:
针对查询语句:select minute_start, count(*), sum(amount), sum(qty) from kylin_streaming_table where user_age in(10,11,12,13,14,15) and country in('CHINA','CANADA','INDIA') group by minute_start order by minute_start
如上述代码流程所示:
首先会根据查询涉及的列计算出cuboid的id为265(100001001),由于涉及minute_start,而minute_start、hour_start和day_start为衍生维度,所以最终的cuboid为457(111001001),后面会根据查询的条件计算出scan,包括范围(5个维度列和3个度量列)为[null, null, null, 10, CANADA, null, null, null](pkStart)到[null, null, null, 15, INDIA, null, null, null](pkEnd)(后面的三个null值会被忽略掉)和根据笛卡尔积会计算出18个filter值(fuzzyKeys):
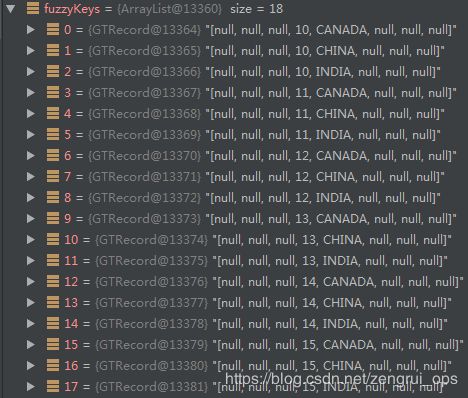
用于后面查询过滤(使用FuzzyRowFilter过滤器);还有就是查询hbase涉及的column也会根据查询语句中涉及的列来进行确定。然后后面会使用getGTScanner中的preparedHBaseScans来对scan的range(pkStart和pkEnd)和fuzzyKeys进行编码转化然后序列化形成请求体中的hbaseRawScan,后面的hbase协处理器就是用这个参数来构建HBase的Scan进行查询。
三. 总结
之前有测试Kylin的查询,发现其查询性能非常稳定,不会随查询的数据量的增长而大幅的增长,通过上面的源码分析基本可以知道其原因,Kylin通过Calcite将SQL语句解析优化后,得到具体的hbase的scan查询,然后使用hbase的协处理器(endpoint模式)来查询,将查询请求通过protobuf协议发送到hbase的regionServer,然后通过协处理器来进行过滤查询和初步聚合,最后会将查询结果进行压缩然后发回请求端,然后再进一步聚合得到最终的查询结果。