高级前端软件工程师知识整理之安全篇
1. CSRF跨域攻击的安全性问题怎么防范?
CSRF(Cross Site Request Forgery, 跨站域请求伪造)是一种网络的攻击方式,可以在受害者毫不知情的情况下以受害者名义伪造请求发送给受攻击站点,从而在并未授权的情况下执行在权限保护之下的操作。被攻击的站点通常是只通过cookie手段来验证用户操作的有效性。被攻击过程如下:

从上图可以看出,要完成一次CSRF攻击,受害者必须依次完成两个步骤:
- 登录受信任网站A,并在本地生成Cookie。
- 在不登出A的情况下,访问危险网站B。
对跨域有一定理解的朋友可能会有疑问?从网站B访问网站A,先不管cookie是不是会被带上,但它已经跨域了啊,还能访问成功吗?好吧,我们用实践测试一下。我搭建了一个上图的执行环境:
网站A域名:http://127.0.0.1:8081
网站B域名:http://127.0.0.1:8020
网站A的服务端只有cookie验证手段,我从网站B通过常用的ajax方法访问网站A,发现确实跨域了,没有办法达到攻击效果:
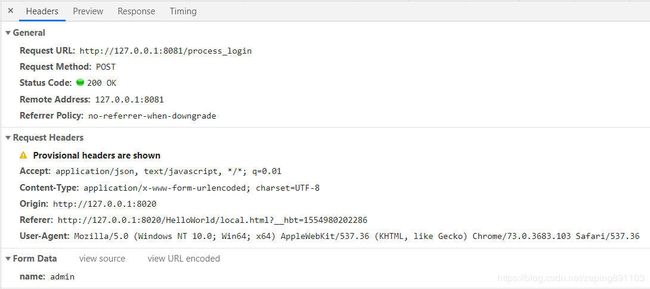
那我们换一种方法,网站B使用表单+iframe方法访问网站A,发现访问成功并且没有跨域问题存在,攻击成功:
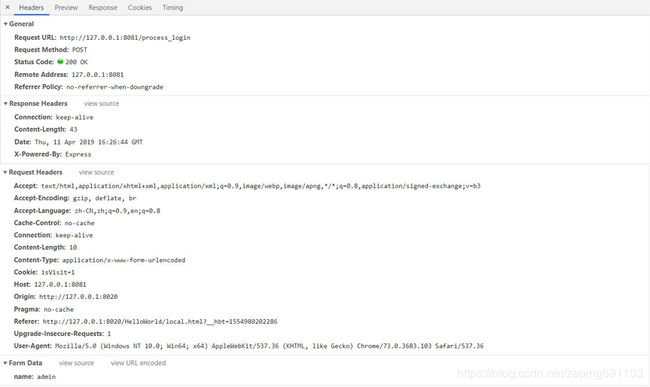
上图显示,虽然我从网站B建立起网站A的访问链接,但是浏览器也会把cookie值带上。也就是说,浏览器并不管你的访问来源是什么,只要访问域名一致并且没有跨域问题,就会把cookie字段放到header中。这证实了CSRF攻击的可能性。
那就是说,攻击的必备条件,就是允许跨域访问,所以说跨域是把双刃剑,用好了可以解决很多网络访问的问题,用不好则容易被攻击。有关跨域方法,可以去看看我的这篇文章《18~19年大厂高级前端面招汇总之跨域篇》,可以知道实现跨域的方法主要有:
- 表单访问+iframe
- CORS
- JSONP
- 服务代理
针对这些跨域方法,为了防止CSRF攻击,我们可以使用的方法有:
- 在请求地址中添加 token 并验证
- 在 HTTP 头中自定义属性并验证
- 验证 HTTP Referer 字段,即访问站点原始地址
- 在提交任务时增加输入验证码操作
详细可以看《CSRF 攻击的应对之道》这篇文章。最后,贴上刚才表单访问+iframe的攻击代码,仅供交流:
POST
2. XSS攻击的安全性问题怎么防范?
XSS(Cross Site Scripting),也称为跨站脚本, 是发生在目标用户的浏览器层面上的,当渲染DOM树的过程中发生了不在预期内执行JS代码时,就发生了XSS攻击。跨站脚本的重点不在‘跨站’,而在于‘脚本’。大多数XSS攻击的主要方式是嵌入一段远程或者第三方域上的JS代码后,实际上是在目标网站的作用域下执行了这段非法js代码。
XSS攻击主要有三种:
- 反射型XSS
- 存储型XSS
- DOM型XSS
举个例子,比如在浏览器打开了网站A,网站A中有一段特殊的URL,其中包含恶意JS脚本,该网站通过一些方法诱导用户打开,这时将会进入URL所在域名的站点并向服务端发送请求,如执行亚马逊网上书店搜索功能。有一种情况是,当搜索不到内容时,会返回“查找不到关键字XXX”,这一过程是服务端将恶意JS脚本从URL中取出且返回给浏览器。如果亚马逊网站没有做XSS攻击防范,则有可能会执行这段恶意JS脚本,后果是窃取用户数据并发送到攻击者的网站,或者冒充用户的行为,调用目标网站接口执行攻击者指定的操作。
这个就是典型的反射型XSS攻击,反射型 XSS 漏洞常见于通过URL传递参数的功能,如网站搜索、跳转等。DOM型XSS其实也是反射型的XSS一种,只是跟服务端无关,即少了中间向服务端发送请求并返回这一步,是单纯的前端代码不严谨造成的漏洞,这类攻击会比较少。
存储型XSS,是基于存储的XSS攻击,通过发表带有恶意跨域脚本的帖子/文章,从而把恶意脚本存储在服务器内,每个访问该帖子/文章的人就会触发并执行这段恶意脚本。
那作为前端工程师,如何要防范XSS攻击并对症下药?这也是本人比较关心的问题。
首先要解决两个误区:
(1)在用户提交时,由前端过滤输入,然后提交到后端。这样做是否可行呢?
答案是不可行。一旦攻击者绕过前端过滤,直接构造请求,就可以提交恶意代码了。
(2)后端在写入数据库前,对输入进行过滤,然后把“安全的”内容,返回给前端。这样是否可行呢?
我们举一个例子,一个正常的用户输入了 5 < 7 这个内容,在写入数据库前,被转义,变成了 5 < 7。问题是这种情况并不知道输出环境是什么,比如我就要输出5小于7,而 5 < 7明显是不对的。
所以,针对XSS攻击尽量在前端防范。防范方法:
(1)防止 HTML 中出现注入,这样也就不会执行非法js脚本。
- 尽可能避免使用 .
innerHTML、.outerHTML、document.write,而应该使用.textContent、.setAttribute() - 如果用 Vue/React 技术栈,尽可能避免使用
v-html/dangerouslySetInnerHTML功能,在 render 阶段同样避免使用innerHTML、outerHTML - DOM中的内联事件监听器,如
location、onclick、onerror、onload、onmouseover等,标签的href属性,JavaScript 的eval()、setTimeout()、setInterval()等,都能把字符串作为代码运行。如果不可信的数据(如用户输入的文本内容)拼接到字符串中传递给这些 API,很容易产生安全隐患,请务必避免这样去做。
(2)在1的基础上,如果非得拼接一段HTML文本追加到DOM中,也不要直接使用innerHTML,建议采用合适的转义库,对 HTML 模板各处插入点进行充分的转义。常用的模板引擎,如 doT.js、ejs、FreeMarker 等。如果是Vue/React技术栈,这个问题就更好解决了,如使用一个v-for循环执行就可以把列表数据加入到DOM中。
(3)如果针对留言等功能,对显示的文本精准度要求不高,那就直接把 & < > " ' / 等这几个字符转义掉,这就基本可以避免XSS攻击,如CSDN种的留言功能。转换参考算法如下:
function htmlEscape(text) {
return text.replace(/[<>"&]/g, function(match, pos, originalText) {
switch(match) {
case "<":
return "<";
case ">":
return ">";
case "&":
return "&";
case "\"":
return """;
}
});
}
var txt = htmlEscape('5<7');
console.log(txt); // 5<7另外,也可以使用he.js实现转换(编码)与反转换(解码),原理大同小异,github地址:https://github.com/mathiasbynens/he
推荐文章《如何防止XSS攻击?》及前端安全类书本《WEB前端黑客技术揭秘》