安装YOLO v4并训练自己数据集(Linux环境)
YOLO v4 论文:https://arxiv.org/abs/2004.10934
YOLO v4 开源代码:https://github.com/AlexeyAB/darknet
YOLO v4的安装基本与YOLO v3相同,作者基本上在YOLOv3的版本基础上进行修改,安装上基本上大同小异,下边简单介绍安装要求。
文章目录
- 1. 安装要求
- 2. 安装
- 2.1 设置Makefile
- 2.2 编译
- 3. Demo测试
- 4. 训练自己数据集
- 4.1数据集准备
- 4.2修改配置文件
- 4.2.1修改cfg/voc.data
- 4.2.2修改data/voc.names
- 4.2.3修改cfg/yolov4-custom.cfg
- 第一处:修改头文件
- 第二处:修改目标类别
- 第三处:卷积层中filters
- 4.3 下载预训练权重
- 4.4 训练模型
- 4.5 何时停止训练
- 5. YOLO不同结果版本对比
- 6. 常见问题
- 6.1 训练过程中出现`Out of memory`
- 6.2 avg (loss)为`nan`
1. 安装要求
- CMake >= 3.8
使用如下命令可以查看自己系统的CMke版本号。
cmake --version
- 1
- CUDA 10.0
使用如下命令查看CUDA版本信息。
cat /usr/local/cuda/version.txt
- 1
- OpenCV >= 2.4
使用如下命令查看OpenCV版本号。
pkg-config opencv --modversion
- 1
- cuDNN >= 7.0 for CUDA
使用如下命令查看cuDNN版本号。
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
- 1
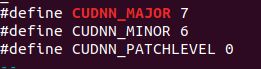
如上图所示的cuDNN版本号为7.6.0。
- GPU with CC >= 3.0
gcc --version
- 1
2. 安装
2.1 设置Makefile
打开darken根目录下的Makefile文件,如下表所示设置里边参数。
| 内容修改 | 不同情况 |
|---|---|
| GPU=1 | 用CUDA构建,用GPU加速(CUDA应该在/usr/local/CUDA中) |
| CUDNN=1 | 使用CUDNN v5-v7构建,使用GPU加速训练(CUDNN应在/usr/local/CUDNN中) |
| CUDNN_HALF=1 | 用于张量核(在泰坦V/Tesla V100/DGX-2及更高版本上)加速探测3x,训练2x |
| OPENCV=1 | 使用OPENCV 4.x/3.x/2.4.x构建-允许检测来自网络摄像机或网络摄像机的视频文件和视频流 |
| DEBUG=1 | 需要对YOLO进行调试 |
| OPENMP=1 | 使用OPENMP支持构建,使用多核CPU加速Yolo |
- 如果已经安装opencv的情况下,需要设置
OPENCV=1; - 如果有Nvidia显卡并且已经安装相应版本CUDA与CUDNN时,设置
GPU=1,CUDNN=1. - 如果显卡为 Titan V / Tesla V100 / DGX-2 或者更新的产品时,设置
CUDNN_HALF=1; - 多核CPU应用时,设置
OPENMP=1
2.2 编译
直接在darknet文件环境下,运行如下代码。
make -j
- 1
在编译过程中,可能会出现Warining,只要不出现Error就是可以的。
3. Demo测试
首先,下载yolov4.weights(官方链接),官方链接是从github中下载,速度较慢,可以从
百度云链接(提取码:ubee)中进行下载。
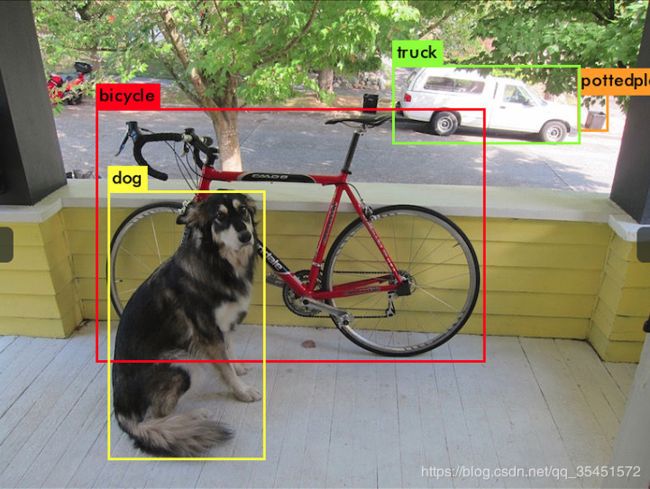
./darknet detect cfg/yolov4.cfg yolov4.weights data/dog.jpg
- 1
规则为:
./darknet detect [训练cfg文件路径] [权重文件路径] [检测图片的路径]
- 1
运行结果如下图所示
4. 训练自己数据集
4.1数据集准备
首先将自己的数据集生成为VOC数据集的格式,至少生成如下格式的文件夹
Annotations
ImageSets
--Main
--test.txt
--train.txt
--trainval.txt
--val.txt
JPEGImages
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
接着将上边四个文件夹放在/darknet/scripts/VOCdevkit/VOC2007内,这个文件夹需要自己来创建一个。接着对/darknet/scripts/voc_label.py进行修改。
第一处
修改第7行
sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
```shell
将“('2012', 'train'), ('2012', 'val'),”删除掉,改为
```shell
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
- 1
- 2
- 3
- 4
- 5
第二处
修改第9行
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
- 1
修改为自己检测目标类别名称
完成修改以后可运行文件,生成YOLO训练时使用的labels
python voc_label.py
- 1
运行结束以后,可以在/darknet/scripts/VOCdevkit/VOC2007文件夹内看到labels文件夹,并且在/darknet/scripts文件夹内会生成2007_train.txt、2007_test.txt、2007_val.txt三个文件。到此,数据准备完成。
4.2修改配置文件
./darknet detector train cfg/voc.data cfg/yolo-voc.cfg darknet19_448.conv.23
- 1
上边是进行训练的命令,可以按照上边的命令对文件进行修改。
4.2.1修改cfg/voc.data
classes= 3 //修改为训练分类的个数
train = /home/ws/darknet/scripts/2007_train.txt //修改为数据阶段生成的2007_train.txt文件路径
valid = /home/ws/darknet/scripts/2007_val.txt //修改为数据阶段生成的2007_val.txt文件路径
names = data/voc.names
backup = backup
- 1
- 2
- 3
- 4
- 5
4.2.2修改data/voc.names
在上边修改的文件内有一个data/voc.names文件,里边保存目标分类的名称,修改为自己类别的名称即可。
4.2.3修改cfg/yolov4-custom.cfg
第一处:修改头文件
文件开头的配置文件可以按照下边的说明进行修改
# Testing
#batch=1
#subdivisions=1
# Training
batch=64 //每次迭代要进行训练的图片数量 ,在一定范围内,一般来说Batch_Size越大,其确定的下降方向越准,引起的训练震荡越小。
subdivisions=8 //源码中的图片数量int imgs = net.batch * net.subdivisions * ngpus,按subdivisions大小分批进行训练
height=416 //输入图片高度,必须能够被32整除
width=416 //输入图片宽度,必须能够被32整除
channels=3 //输入图片通道数
momentum=0.9 //冲量
decay=0.0005 //权值衰减
angle=0 //图片角度变化,单位为度,假如angle=5,就是生成新图片的时候随机旋转-5~5度
saturation = 1.5 //饱和度变化大小
exposure = 1.5 //曝光变化大小
hue=.1 //色调变化范围,tiny-yolo-voc.cfg中-0.1~0.1
learning_rate=0.001 //学习率
burn_in=1000
max_batches = 120200 //训练次数,建议设置为classes*2000,但是不要低于4000
policy=steps //调整学习率的策略
//根据batch_num调整学习率,若steps=100,25000,35000,则在迭代100次,25000次,35000次时学习率发生变化,该参数与policy中的steps对应
steps=40000,80000 // 一般设置为max_batch的80%与90%
scales=.1,.1 //相对于当前学习率的变化比率,累计相乘,与steps中的参数个数保持一致;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
注意:如果修改max_batches总的训练次数,也需要对应修改steps,适当调整学习率。
具体的含义可以查看YOLO网络中参数的解读
第二处:修改目标类别
修改三处classes,分别位于970行、1058行与1146行,将其修改为自己数据集的目标数量;
classes=3
- 1
第三处:卷积层中filters
在每个[yolo]层之前的3个[convolutional]中,将[filters=255]改为filters=(classes + 5)x3,记住只要在每个[yolo]层之前的最后一个[convolutional]即可。
分别位于963行、1051行与1139行,将其修改为自己数据集的目标数量;
filters=255 #filters=(classes + 5)x3
activation=linear
[yolo]
mask = 0,1,2
- 1
- 2
- 3
- 4
- 5
- 6
4.3 下载预训练权重
谷歌网盘地址: yolov4.conv.137
百度网盘地址: yolov4.conv.137 ,提取码:dw15
4.4 训练模型
./darknet detector train data/obj.data yolov4-custom.cfg yolov4.conv.137
- 1
作者制作了如下的图,能够直接观察损失、时间等信息,非常实用。
4.5 何时停止训练
通常每个类(对象)有足够的2000次迭代,但总共不少于4000次迭代。但是为了更精确地定义什么时候应该停止培训,通过观察avg数值。
Region Avg IOU: 0.798363, Class: 0.893232, Obj: 0.700808, No Obj: 0.004567, Avg Recall: 1.000000, count: 8 Region Avg IOU: 0.800677, Class: 0.892181, Obj: 0.701590, No Obj: 0.004574, Avg Recall: 1.000000, count: 8
9002: 0.211667, 0.60730 avg loss, 0.001000 rate, 3.868000 seconds, 576128 images Loaded: 0.000000 seconds
- 1
- 2
- 3
在训练期间,您将看到不同的错误指示符,当不再减少0时应该停止。XXXXXXX avg
当你看到平均损失为0。xxxxxx avg不再减少在许多迭代,然后你应该停止培训。最终的平均损失可能是0.05(对于小模型和容易的数据集)到3.0(对于大模型和困难的数据集)。
5. YOLO不同结果版本对比
| 模型名称 | mAP0.5 | FPS | BFlops |
|---|---|---|---|
| yolov4 608 | 65.7% | 34 | 128.5 |
| yolov4 512 | 64.9% | 45 | 91.1 |
| yolov4 416 | 62.8% | 55 | 60.1 |
| yolov4 320 | 60% | 63 | 35.5 |
| yolov3-tiny-prn | 33.1% | 370 | 3.5 |
| EfficientNetB0-Yolov3 | 45.5% | 55 | 18.3 |
| yolov3-spp | 60.6% | 38 | 141.5 |
| yolov3 | 55.3% | 66 | 65.9 |
| yolov3-tiny | 33.1% | 345 | 5.6 |
6. 常见问题
6.1 训练过程中出现Out of memory
这个是超出内存,是因为模型训练送入图像太多,应该减少.cfg文件中的subdivisions数值。
6.2 avg (loss)为nan
如果在训练过程中,avg (loss)部分为nan是正常现象,如果都为nan时,可能为学习率太大,应该适当减少学习率,同时应该注意,使用多GPU训练时,学习率应该除以GPU的数量。