MP3解码算法原理解析
写在前面
如果大家对音视频技术感兴趣,可以订阅我的专题 视频播放器和音视频基础知识。
一:MP3编解码整体结构介绍
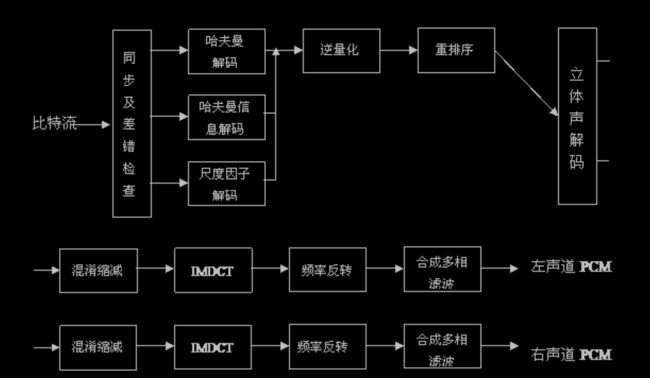
看懵逼了是吧。这里面有很多概念需要一一讲解。
比特流:比特流是一种内容分发协议。它采用高效的软件分发系统和点对点技术共享大体积文件(如一部电影或电视节目),并使每个用户像网络重新分配结点那样提供上传服务。(因为没有专业学过这方面的内容,我暂且把它理解为一段数据,里面的内容有时间再探讨)。
同步及差错检查:mp3的数据流的传输和同步工作中都是以帧为单位的。帧是MP3最小的格式单元,它不可以再被分割。每一帧头部包含了当前帧的一些基本信息,其中就包括同步信息。同步信息的组成是包含连续的12比特的‘1’。mp3视频解码工作的第一步就是使解码器和输入数据流同步。在启动解码器之后,可以搜索数据中连续12个比特的‘1’来完成。在取得同步信息之后,帧头部后续的信息是:帧头信息,包括采样率、填充位、比特率等信息。
哈夫曼解码:你可以这样理解,我把不同的数据通过一个表格进行一一对应,用这个对应的码来表示原来的信息,那么出现频率高的数,我用尽可能短的码来表示。出现频率低的数用长一点的码来表示。这样可以减少表示信息的内容量。而且传输过去之后,再按照这个对照码可以进行还原。大概原理就是这个。
逆量化 量化过程的逆过程,想了解这个各位需要学习一下量化的过程。
- IMDCT:IMDCT是缩写,全称是:Inverse Modified Discrete Cosine Transform(反向修正离散余弦变换)。在MP3中需要使用此算法将输入数据从频域变换到余弦域,对子带滤波进行补偿运算。使用逆向离散余弦变换的公式,对反量化得出的信号进行变换。IMDCT运算公式大概长这样:
 IMDCT运算过程如下图:
IMDCT运算过程如下图:
- 频率反转:对逆向离散余弦变换的输出值中的奇数号子带(0到31号子带中的1,3,5,…,31)中的奇数号样本值(每个子带中的0到17号样本值的1,3,5,…,17号样本值)进行反相处理,用来补偿编码时为提高离散余弦变换效率而进行的频率反转。
针对以上的概念,如果有不清楚的,可以看我的另外一篇博客:MP3头帧解析,里面有一些和帧头信息相关的知识。
同步及差错检查包括了头部信息解码模块 在主控模块开始运行后,主控模块将比特流的数据缓冲区交给同步及差错检查模块,此模块包含两个功能,即头信息解码及帧边信息解码,根据它们的信息进行 尺度因子解码及哈夫曼解码,得出的结果经过逆量化,立体声解码,混淆缩减, IMDCT,频率反转,合成多相滤波这几个模块之后,得出左右声道的 PCM 码 流 , 再由主控模块将其放入输出缓冲区输出到声音播放设备(总之很复杂)。
2、主控模块
主控模块的主要任务是操作输入输出缓冲区,调用其它各模块协同工作。 其中,输入输出缓冲区均由 DSP 控制模块提供接口。
输入缓冲区中放的数据为原始 mp3 压缩数据流,DSP 控制模块每次给出大于最大 可能帧长度的一块缓冲区,这块缓冲区与上次解帧完后的数据(必然小于一帧) 连接在一起,构成新的缓冲区。
输出缓冲区中将存放的数据为解码出来的 PCM 数据,代表了声音的振幅。它由一 块固定长度的缓冲区构成,通过调用 DSP 控制模块的接口函数,得到头指针,在 完成输出缓冲区的填充后,调用中断处理输出至 I2S 接口所连接的音频 ADC 芯片 (立体声音频 DAC 和 DirectDrive 耳机放大器)输出模拟声音。
3、同步及差错检测
同步及差错检测模块主要用于找出数据帧在比特流中的位置,并对以此位置开始 的帧头、CRC 校验码及帧边信息进行解码,这些解码的结果用于后继的尺度因子 解码模块和哈夫曼解码模块。Mpeg1 layer 3 的流的主数据格式见下图:

其中 granule0 和 granule1 表示在一帧里面的粒度组 1 和粒度组 2,channel0 和 channel1 表示在一个粒度组里面的两个通道,scalefactor 为尺度因子 quantized value 为量化后的哈夫曼编码值,它分为 big values 大值区和 count1 1 值区
CRC 校验:表达式为 X16+X15+X2+1
3.1 帧同步
帧同步目的在于找出帧头在比特流中的位置,ISO 1172-3 规定,MPEG1 的帧头 为 12 比特的“1111 1111 1111”,且相邻的两个帧头隔有等间距的字节数,这 个字节数可由下式算出:
N= 144 * 比特率 / 采样率
如果这个式子的结果不是整数,那么就需要用到一个叫填充位的参数,表示间距 为 N +1。
3.2 头信息解码
头信息解码目的是找出这一帧的特征信息,如采样率,是否受保护,是否有填充 位等。头信息见下图: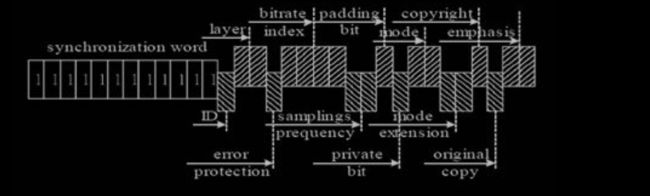
其长度为 4 字节,数据结构如下:
typedef struct tagHeader {
unsigned int sync : 11 ; / / 同步信息
unsigned int version : 2 ; / / 版本
unsigned int layer : 2 ; / / 层
unsigned int error2protection : 1 ; / / CRC 校正
unsigned int bit2rate2index : 4 ; / / 位率索引
unsigned int sample2rate2index : 2 ; / / 采样率索引
unsigned int padding : 1 ; / / 空白字
unsigned int extension : 1 ; / / 私有标志
unsigned int channel2mode : 2 ; / / 立体声模式
unsigned int mode extension : 2 ; / / 保留
unsigned int copyright : 1 ; / / 版权标志
unsigned int original : 1 ; / / 原始媒体
unsigned int emphasis : 2 ; / / 强调方式
} HEADER
3.3 帧边信息解码
帧边信息解码的主要目的在于找出解这帧的各个参数,包括主数据开始位置,尺 度因子长度等。帧边信息如下图所示:
3.4 main_data_begin
main_data_begin(主数据开始)是一个偏移值,指出主数据是在同步字之前多少 个字节开始。需要注意的是,1.帧头不一定是一帧的开始,帧头 CRC 校验字和帧 边信息在帧数据中是滑动的。2.这个数值忽略帧头和帧边信息的存在,如果 main_data_begin = 0, 则主数据从帧边信息的下一个字节开始。 参见下图:
3.5 block_type
block_type 指出如下三种块类型:
block_type = 0 长块
block_type = 1 开始块
block_type = 3 结束块
block_type = 2 短块
在编码过程中进行 IMDCT 变换时,针对不同信号为同时得到较好的时域和频域 分辨率定义了两种不同的块长:长块的块长为 18 个样本,短块的块长为 6 个样 本。这使得长块对于平稳的声音信号可以得到更高的频率分辨率,而短块对跳变 信号可以得到更高的时域分辨率。由于在短块模式下,3 个短块代替 1 个 长 块 , 而短块的大小恰好是一个长块的 1/3,所以 IMDCT 的样本数不受块长的影响。对 于给定的一帧声音信号,IMDCT 可以全部使用长块或全部使用短块,也可以长短 块混合使用。因为低频区的频域分辨率对音质有重大影响,所以在混合块模式下 , IMDCT 对最低频的 2 个子带使用长块,而对其余的 30 个子带使用短块。这样, 既能保证低频区的频域分辨率,又不会牺牲高频区的时域分辨率。长块和短块之 间的切换有一个过程,一般用一个带特殊长转短(即,起始块 block_type = 1) 或短转长(即终止块,block_type = 3)数据窗口的长块来完成这个长短块之间 的切换。因此长块也就是包括正常窗,起始块和终止块数据窗口的数据块;短块 也包含 18 个数据,但是是由 6 个数据独立加窗后在经过连接计算得到的。
3.6 big_values, count1
每一个粒度组的频谱都是用不同的哈夫曼表来进行编码的。编码时,把整个从 0 到奈奎斯特频率的频率范围(共 576 个频率线)分成几个区域,然后再用不同的 表编码。划分过程是根据最大的量化值来完成的,它假设较高频率的值有较低的 幅度或者根本不需要编码。从高频开始,一对一对的计算量化值等于“0”的数 目,此数目记为“rzero”。然后 4 个一组地计算绝对值不超过“1”的量化值(也 就是说,其中只可能有-1,0 和+1 共 3 个可能的量化级别)的数目,记为“count1”,在此区域只应用了 4 个哈夫曼编码表。最后,剩下的偶数个值的 对数记为“big values”, 在此区域只应用了 32 个哈夫曼编码表。在此范围 里的最大绝对值限制为 8191。此后,为增强哈夫曼编码性能,进一步划分了频 谱。也就是说,对 big values 的区域(姑且称为大值区)再细化,目的是为了 得到更好的错误顽健性和更好的编码效率。在不同的区域内应用了不同的哈夫曼 编码表。具体使用哪一个表由 table_select 给出。从帧边信息表中可以看到: 当 window_switch_flag == 0 时,只将大值区在细分为 2 个区,此时 region1_count 无意义,此时的 region0_count 的值是标准默认的;但当 window_switch_flag == 1 时再将大值区细分为 3 个区。但是由于 region0_count 和 region1_count 是根据从 576 个频率线划分的, 因此有可能 超出了 big_values *2 的范围,此时以 big_values *2 为准. region0_count 和 region1_count 表示的只是一个索引值,具体频带要根据标准中的缩放因子频带 表来查得.
参见下图:

3.7 处理流程

4、缩放因子(scale factor)解码
缩放因子用于对哈夫曼解码数据进行逆量化的样点重构。根据帧边信息中的 scalefactor_compress 和标准中的对应表格来确定的 slen1 和 slen2 对缩放因 子进行解码,即直接从主数据块中读取缩放因子信息并存入表 scalefac_l[gr][ch][sfb]和 scalefac_s[gr][ch][sfb]中。对第 2 粒度组解码 时,若为长块,则必须考虑尺度因子选择信息。
4.1 尺度因子带(scalefactor-band)
在 mpeg layer 3 中 576 条频率线根据人耳的听觉特性被分成多个组,每个组对 应若干个尺度因子,这些组就叫做尺度因子带,每个长窗有 21 个尺度因子带而 每个短窗有 12 个尺度因子带。
4.2 scfsi
scfsi(尺度因子选择信息)用于指出是否将粒度组 1 的尺度因子用于粒度组 2。 如果为 0 表示不用,则在比特流中需读取粒度组 2 的尺度因子。
4.3 处理流程

5、哈夫曼解码
哈夫曼编码是一种变长编码,在 mp3 哈夫曼编码中,高频的一串零值不编码,不 超过 1 的下一个区域使用四维哈夫曼编码,其余的大值区域采用二维哈夫曼编 码,而且可选择地分为三个亚区,每个有独立选择的哈夫曼码表。通过每个亚区 单独的自适应码表,增强编码效率,而且同时降低了对传输误码的敏感度。 在程序实现上,哈夫曼表逻辑存储采用了广义表结构,物理存储上使用数组结构 。 查表时,先读入 4bit 数据,以这 4bit 数据作为索引,其指向的元素有两种类型 , 一种是值结构,另一种是链表指针式结构,在链表指针式结构中给出了还需要读 取的 bit 数,及一个偏移值。如果索引指向的是一个值结构,则这个值结构就包 含了要查找的数据。如果索引指向的是一个链表指针式结构,则还需再读取其中 指定的比特数,再把读取出的比特数同偏移值相加,递归的找下去,直到找到值 结构为止。
5.1 处理流程
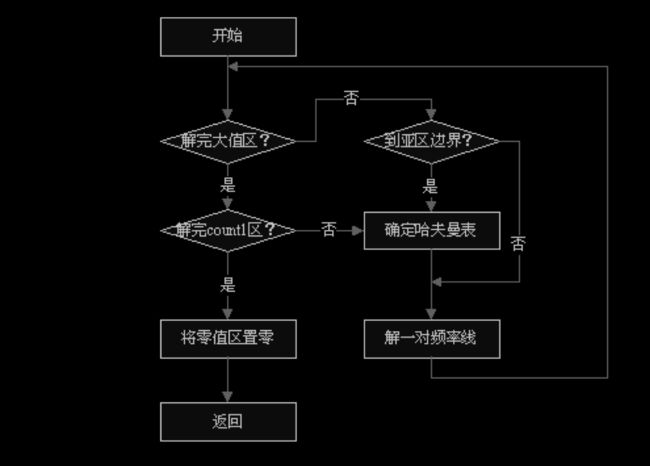
6、逆量化
6.1 逆量化公式
逆量化由下面公式算出:
短窗模式:

长窗模式:

其中:
| is[i] | 由 huffman 编码构造的频率线 |
|---|---|
| sbg | subblock_gain |
| scalefac_multiplier | = (scalefac_scale + 1) / 2 |
其它值均可在帧边信息中找到。
7、联合立体声转换
7.1 强度立体声转换
在强度立体声模式中,左声道传的是幅值,右声道的 scalefactor 传的是立体声 的位置 is_pos。需要转换的频率线有一个低边界,这个低边界是由右声道的 zero_part 决定的,并且使用右声道的尺度因子来作为 is_pos。
强度立体声比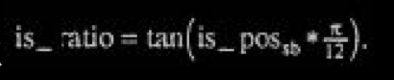
左声道:

右声道: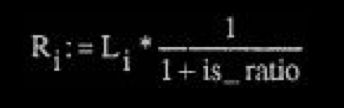
其中 Mi 是 channel[0]的值,Si 是 channel[1]的值
7.3 处理流程
强度立体声模式: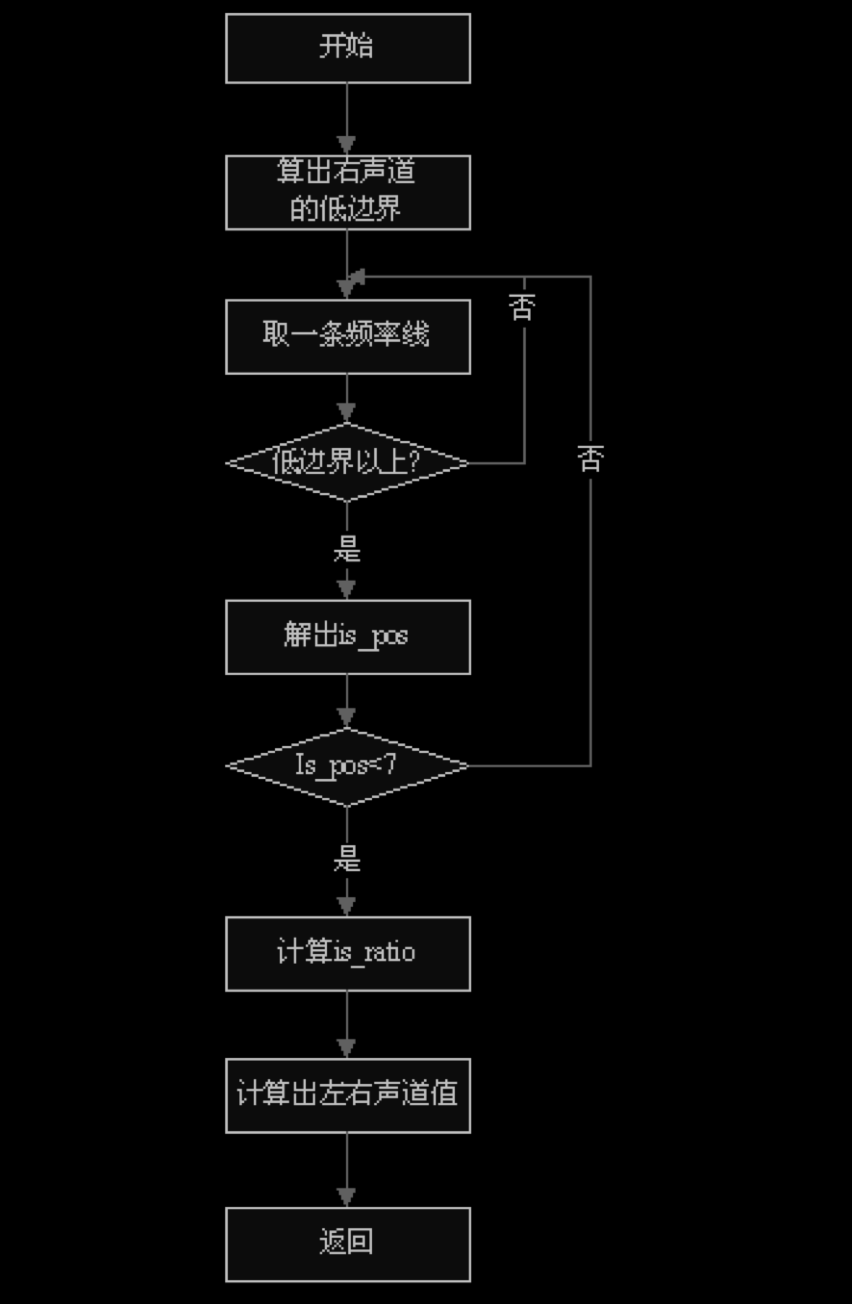
MS_STEREO 因公式单一,较易理解,故流程图略去。
8、重排序
重排序的目的在于把哈夫曼解码之后的短块的每个尺度因子带 3 个窗,每个窗 sfbwidth(尺度因子带宽度)个采样的顺序整理成为每个子带三个窗,每个窗六个 采样 xr[sb][window][freq_line]的顺序。
8.1 处理流程

混淆缩减
对于长块,在进入 IMDCT 之前应当先进行混淆缩减。其算法思想是用蝶形算法进 行相邻块相邻频率线的调整。如图:
其计算公式如下:

其中 ci 可由 ISO 1172.3 table B.9 查得
计算流程如下(pascal 描述):
For sb = 1 to 32 do
For i = 0 to 7 do
Xar[18sb- i -1] = xr[18sb – i - 1]cs[i] – xr[18sb + i]ca[i]
Xar[18sb+i] = xr[18sb +i]cs[i] + xr[18sb -i- 1]ca[i]
End for
End for
10、IMDCT 覆盖叠加
MDCT 的目的在于进行时域到频域的转换,减少信号的相关性,使得信号的压缩 可以更加高效地完成,而它的反变换 IMDCT 的目的在于将信号还原为没有变换之 前的数值,使频域值向时域值过渡。
其公式如下:
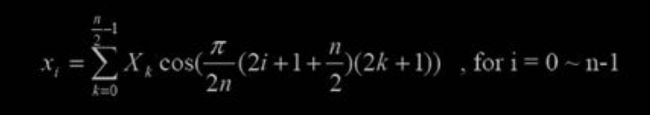
在进行了 IMDCT 变换之后,需对频率信号进行加窗、覆盖、叠加。
10.1 加窗:
长块:

开始块:

结束块:

短块的每个窗口分别计算:

10.2 叠加:
将每一块变换出来的值的前半部分与前一块的后半部分相加,并把后半部分保留 来和下一块的前半部分相加。如下公式:
resulti = zi + si
for i = 0 to 17
si = zi+18
for i = 0 to 17
10.3 Szu-Wei Lee 的快速算法
Szu-Wei Lee 的 IMDCT 快速算法是针对非 2 的 n 次幂个点的 IMDCT 快速算法。他 的主要步骤如下:
- 将 N 点 MDCT 化为 N/2 点 DCT-IV
- 将 N/2 点 DCT-IV 化为 N/2 点 SDCT-II
- 将 N/2 点 SDCT-II 化为 2 个相同的 N/4 点 SDCT-II
- 计算 SDCT-II(9 点)
在本程序中,因为对短块使用这个快速算法并没有带来较大的速度改善,故只对 长块使用此快速算法,相较于直接运算的 648 次乘和 612 次加来,它只用 43 次 乘和 115 次加。
11、频率反转
在 IMDCT 之后,进入合成多相滤波之前必须进行频率反转补偿以校正多相滤波器 组的频率反转。方法是将奇数号子带的奇数个采样值乘以-1.
12、合成多相滤波
合成多相滤波的目的是将频域信号转化为时域信号。其原理流程如下:
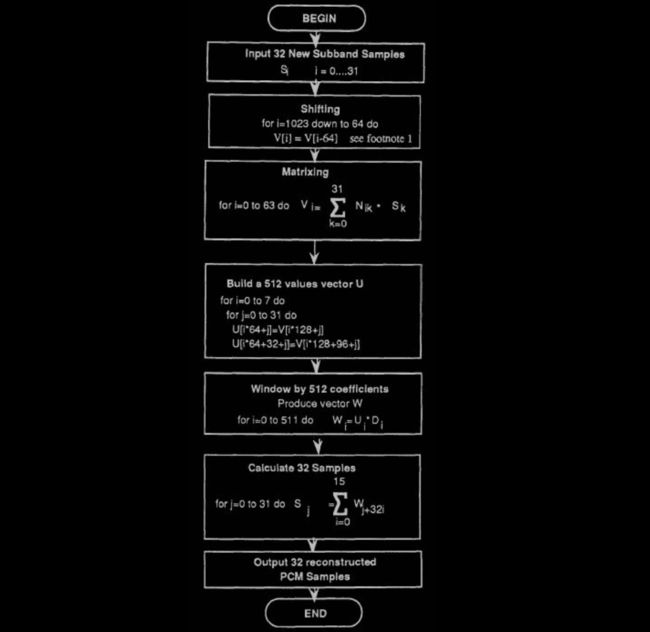
上图流程可简述如下:
1. 将从 32 个子带抽来的 32 个 sample 值通过一个矩阵运算算 出 64 个中间值
将这 64 个中间值放入一个长度为 1024 的 FIFO 缓冲区(这个 缓冲区初始化为 0)。
从这个缓冲区中每连续的 128 个值中取头尾各 32 个值,合 为 64 个值。完成后组成 512 值的向量 U
加窗,即将 Ui 与窗口系数 Di 相乘,得到另一 512 值向量 W
最后将这 512 值向量 W 每连续的 32 个值中顺次取一个值, 一次共取得 512/32 = 16 个值相加。完成后一共取得 32 个 最终的时域信号值。
Byeong Gi Lee 的 dct 快速算法
Byeong Gi Lee 的 DCT 快速算法是用于 2 的 n 次幂个点的 dct 快速算法。它用于 N 点的 DCT 时仅需(N/2) * log2N 次乘法和小于 3·*(N/2)*log2 N ) 次加法。 其基本思想是,将 N 个点的 DCT 转化为两个 N/2 个点的 DCT 的和。 进一步分解, 即重复这个过程,减少乘法数量。
由于向量 Vi 的运算是一个类似于 DCT 的变换,故使用了此快速算法。32 点运算 共使用了 80 次乘法和 80 次加法 119 次减法。
术语说明
| MPEG | Motion Picture Expert Group |
|---|---|
| IMDCT | 反离散余弦变换 |
| gr | granule 粒度组 |
| ch | channel 通道 |