大话西游之王道考研数据结构第七讲---树、森林以及应用
第六讲--二叉树的遍历和线索化二叉树
复习
- 线索化二叉树的目的是什么?
- n个结点的二叉树的链式表示中,空链域有多少个?
- ltag和rtag分别为多少时候,代表什么?
- 为什么后续线索化二叉树中,某些结点有可能找不到其后继结点?
一、树的san种存储结构
这个就比较easy了,我们知道二叉树的存储结构里面就是有一个结点,然后还有结点的两个孩子,一家三口和和睦睦~当然,树也可以这么干,存一个结点,把他所有的孩子都存起来(但是树的孩子可能有很多个,这就对如何存孩子提出了一个要求,我们可以创开辟一个数组,里面存孩子结点,也可以创建一个链表,存孩子结点),这就是传说中的孩子表示法。
二叉树里面,孩子分为左结点(哥哥)和右结点(弟弟)。咱这里当然也可以这么分,我们可以分为左结点(*firstchild,孩子),右结点(*nextsibling,兄弟们)。这就是孩子兄弟表示法。下面我们看下他的结构体:
typedef struct CSNode{
int data;
struct CSNode *firstchild,*nextsibling;
}*CSTree;我们也可以创建一个结点,然后不存他孩子,存他爸~。这个树的结构也就确立下来了(那么为什么二叉树里面不整这一套?),这就是双亲表示法(这里双亲其实就只的父亲,中文翻译成双亲其实不太准确,因为他只有一个父节点)。
这三种种都有缺陷,孩子表示法和孩子兄弟表示法可以方便找孩子,但是很难找爸(那么找爸的复杂度是多少)。双亲表示法可以方便找爸,但是找孩子就很难(找孩子复杂度是多少)。
二、树、森林与二叉树的转换
2.1 树和二叉树的转换(这是考试里面经常爱考的东西,一般是选择题。)
我们看下刚才树的孩子兄弟表示法,有没有发现很神奇的地方,一棵树可以用二叉树的表示法进行表示。只不过树里面的左孩子和二叉树里面的左孩子定义是一样的,只不过树里面的右孩子存的是左孩子的剩下那些兄弟。也就是“左孩子,右兄弟”。
既然可以互相表示,那么二叉树和森林就可以互相转换。
a)树转二叉树:树转化为二叉树后,二叉树中左孩子就是原来树中左孩子,右孩子就是原来树中左孩子剩下的那帮兄弟一个连着一个。我们从下到上,从左到右处理每一个非叶子结点:
1.把他所有孩子,先断绝父子关系,
因为结点的右结点是用来存兄弟的,不是存他孩子的,他的孩子都得放在左结点处,所以他的孩子都得先松开
2.把老大连在当前结点的左结点处
左孩子是用来存孩子的,先把老大加进去
3.把剩下的兄弟,按照顺序依次连到老大的右结点处(为什么不随便连)。
这帮孩子松开以后按照顺序连到他的左结点处,但是孩子之间的连接方式也得定义,因为右结点连得是兄弟,所以下一个孩子是当前孩子的右结点。
举个栗子

第一个非叶子节点应该是第三层的F,把F的孩子断开,然后连在其左结点处:
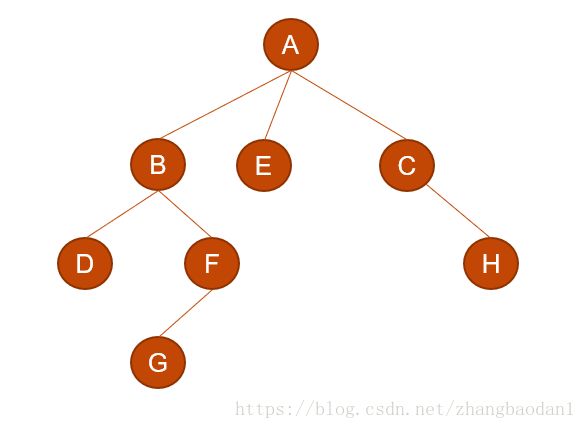
第三层没有其他非叶子节点了,我们看第二层,从左到右,先看B,把他孩子都断开,然后连在左孩子处:

注意,这里是先把D,F断开,然后把D连在B的左结点处,把F连在D的右结点处,G的位置相对不变。
同理我们处理C:
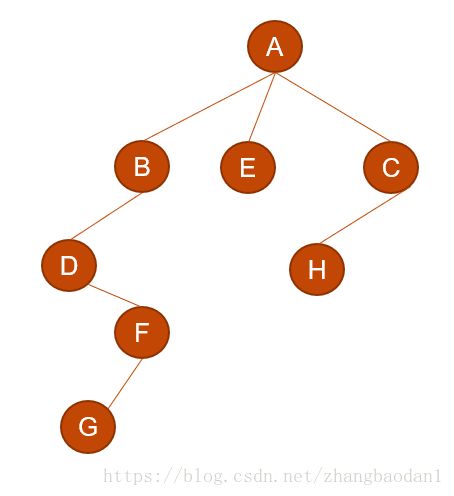
然后处理A:
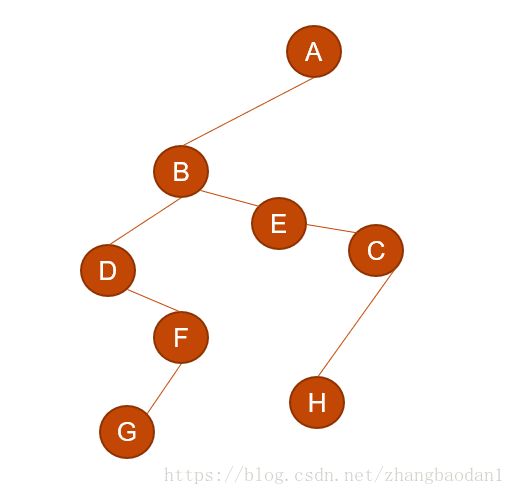
这样就转成一个二叉树了~
2.2 森林转二叉树
这个东西其实就是树转二叉树的高阶版本,因为森林是由一个个树组成的,所以:
1.把每个树转化成二叉树。
2.把第一个树的根节点当做整个转化后二叉树的根节点,第一个树的右结点肯定是空的(想想为什么),我们依次把剩下几棵转化为二叉树的树当成它的兄弟,连在右结点处就好了。
2.3 二叉树转树
永远记住左孩子右兄弟,做的时候就比较容易:
我们可以看到,这个二叉树根节点A没有右子树,说明A没有兄弟,也说明我们转化以后因该是一个树,而不是森林(如果是森林的话,右结点肯定有东西)。
转成树时候,从上到下,从左到右.把当前结点左孩子,以及左孩子右结点,左孩子右结点的右结点,左孩子右结点的右结点的右结点...都断开,依次连到当前结点上。就OK了
我们先看A:按照这个规矩处理完是这个样子:

然后看B,处理完以后:

然后看C,处理完以后:
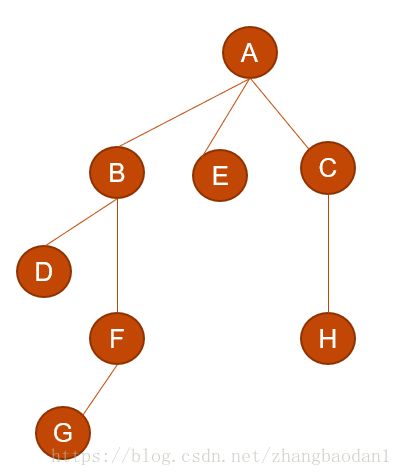
C就一个孩子H,把H放左边、放下边、放右边都是一样的(因为森林里面,直说孩子,不说左孩子右孩子,就算说也说得是第一个孩子和右兄弟)。
然后处理F,处理F的方式和C一样,结果也就是上图~
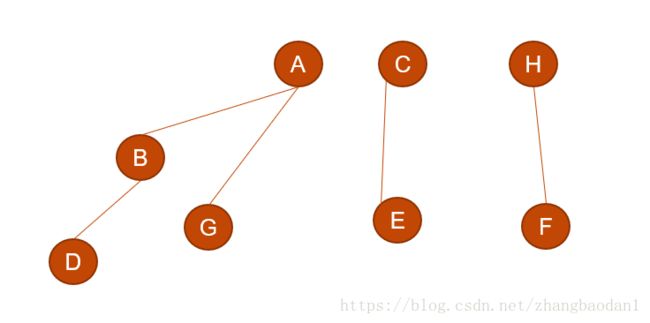
2.3 二叉树转森林
和二叉树转树是一样的操作方式,只不过根节点连右子树的话,转出来是森林,森林中树的个数取决于从从根节点开始,一直访问右结点,能访问几次,不连的话出来是树
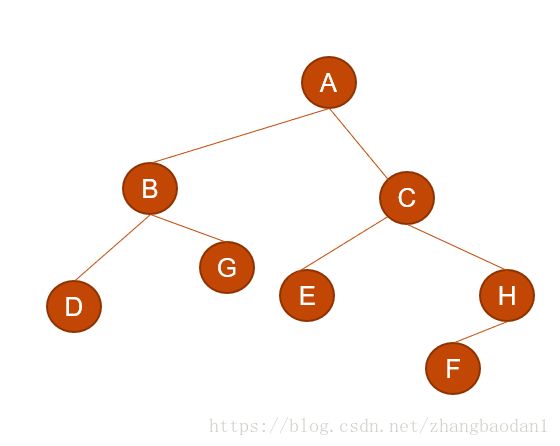
先划分子树:

然后处理每一个子树:
三、二叉排序树(考研大题必考内容)
二叉排序树或者是一棵空树,或者是一颗具有下列特征的非空二叉树:
1)若左子树为空,则左子树上所有结点关键字均小于根节点的关键字值
2)若右子树为空,则右子树上所有结点关键字值均大于根结点的关键字值
3)左、右子树本身也分别是一颗二叉排序树
说白了,对于任意结点,都有左<当前结点<右,也就是L 这里,我们学校考研里面对这个东西的代码不做要求,如果想看的话,可以去网上搜,这里我也提供我当初写的代码: (个人小建议,本科学数据结构和算法时候,老师上面讲一个内容,下面一定要会利用博客,搜搜这个东西别人是怎么写的,然后自己实现一遍)。 我们主要说一下,二叉排序树在做题时候,一般会怎么考: 1.二叉排序树的插入 排序二叉树插入结点的过程是:若原二叉排序树为空,则直接插入节点,否则,若关键字k小于根结点关键字,则插入到左子树中,若关键字k大于根结点关键字,则插入到右子树中 举个栗子 1.插入的新结点一定是叶结点 2.待插入的序列顺序不一样,最后二叉树的结果也不一样(如果待插入序列是32,47,48,49,51,54的结果是什么?)。 2.二叉排序树的删除 如果要把二叉排序树中的某个结点删除了,我们肯定得找个结点补在他的位置,不然就是两个二叉排序树了,而补完以后,一定不能破坏二叉排序树(L 1.删除结点是叶子结点,就直接删除。 2.只有一颗左子树或者右子树,把左/右子树放在原来位置就好 3.有左右两棵子树: a.我们可以找比它小一点点的那个结点,把这个结点放在原位置 小一点点的意思是,如果你要删除49,小一点点的就是48(47小太多了),那么如何找到小一点点的那个结点?我们知道其左子树都是比它小的,我们需要找到左子树里面最大的,而左子树里面,我们只要一直找右结点,找到最后一个就是他最大的(也就是他的前驱结点)! b.我们可以找比它大一点点的那个结点,把这个结点放在原来位置 同a一样的思路,我们找右子树里面最左面的结点(也就是他的后继结点)。 c.为什么要找小一点点的(大一点点的)而不能小(大)太多? 因为,如果小很多的话,比如我们找了47,那么48就在47的左子树里面了,这是不允许的。 3.二叉排序树的查找效率的分析 查找效率也就是我们要查找的一个结点,成功的查找长度是多少,失败的查找是多少? a.成功的查找长度 成功意思就是待查找的数字肯定在二叉排序树里面,如果是54的话,我们需要查找1次,如果是32--2次,47-2次,49-3次,48-4次 ,51-4次 所以平均查找长度就是: 而我们每查找一次,就会往下走一层,所以结点查找的长度就是结点的深度,或者是所属层数,所以公式也可以是: 那么如果待插入序列是32,47,48,49,51,54的结果是什么? b.失败的查找长度 失败就是待查找的结点不在二叉排序树里面,而我们的排序二叉树,只有查找到要找的结点或者查找NULL结点才会罢休,查找到结点这个想法是不可能了,因为我们求得是失败,所以我们只能查找到空结点。 这里面,32有两个空结点,47有一个空结点,所以一共有3个层为3的空结点,但是我们前面乘以了2,不是3,2的意思就是我们在二叉排序树里面找了几次结点(有的书上说应该乘以3,有的是乘以2,这里我们以乘以2为主)。48和51各有两个空结点,所以是4*4. 哈夫曼树的提出主要是用在密码学,压缩存储,数据传输方面,英文有26个字母,每个字母使用的频率是不一样的,比如s,a这些字母使用频率就很高,而x这种字母频率就很低。如果我们给每个字母编码,每个字母编码长度都是一样的,这样的编码其实不是最高效的。我们一般采用变长编码,如果我们能给s编码为0,a编码为01, x编码为000101。这样使用频率越高,编码越短,会增加传输效率。比如我们有001010101---我们就可以翻译为sax,至于为什么可以,后面再说。 定义书上有,这里说下怎么构建:假设我们现在有一个文本,文本里面字母出现频率(也就是权重)如下 a ---30, s---31, b--20, c---10, x ----3, q ----7, d----6 首先排个序: WPL = (30 + 31 +20)*2 + 10*3 + 7*4 + (3+6)*5 编码:a:00 s:01 b:10 c:110 q:1110 x:11110 d:11111 为什么没有一个码是其他码的前缀? 1.x和d的顺序可以交换,我习惯小的放左面~所以哈夫曼编码的树结构可以不一样 2.哈夫曼的总结点数为多少? 3.每一个原始结点在树中都是什么结点 4.哈夫曼中有没有度为1的结点? #include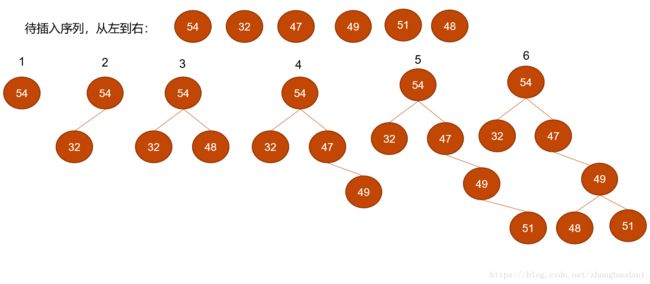
![]()

![]() 就是结点
就是结点![]() 所属的层数,说白了,把每个结点的层数一加然后除以结点个数。
所属的层数,说白了,把每个结点的层数一加然后除以结点个数。![]()
三、哈夫曼(考研大题必考内容)


