es实现近实时搜索推荐的两种方式
在百度搜索框里面,当我们输入某个关键字或关键词的时候,基本上不需要等待多久【秒级】,当然网络太差就不说了,就可以马上列出一大堆相关的词句,这些是怎么实现的呢
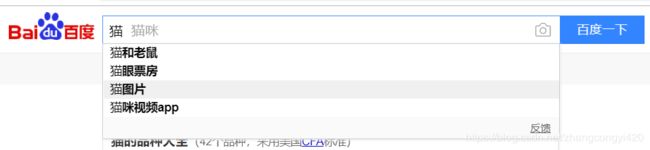
总的来说,实现方式有两种,第一种,实时ajax请求后端接口,即鼠标弹起事件触发,但对于数据量特别大的网站基本上不可能;第二种方式就是搜索引擎来实现了,至于百度的搜索引擎是什么样的,我们无从得知,但是和es的搜索原理应该类似,拿到短语或者句子,去数据仓库做实时检索,将检索出来的一系列doc根据得分情况进行排名,然后拿出得分最高的前N条数据展示给用户,原理大概如此
在es中,有哪些方式可以达到类似的效果呢?下面简单分享两种实现此功能的方式
方式一,match_phrase_prefix
1、首先我们创建一个索引,并插入一组有特征意义的数据如下,
PUT /myindex/mytype/1
{
"title":"hello world"
}
PUT /myindex/mytype/2
{
"title":"hello we"
}
PUT /myindex/mytype/3
{
"title":"hello win"
}
PUT /myindex/mytype/4
{
"title":"hello wed"
}
PUT /myindex/mytype/5
{
"title":"hello cat"
}
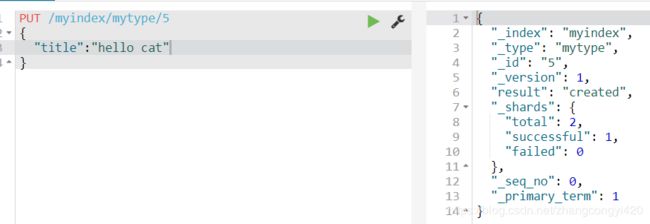
5条数据创建完毕,
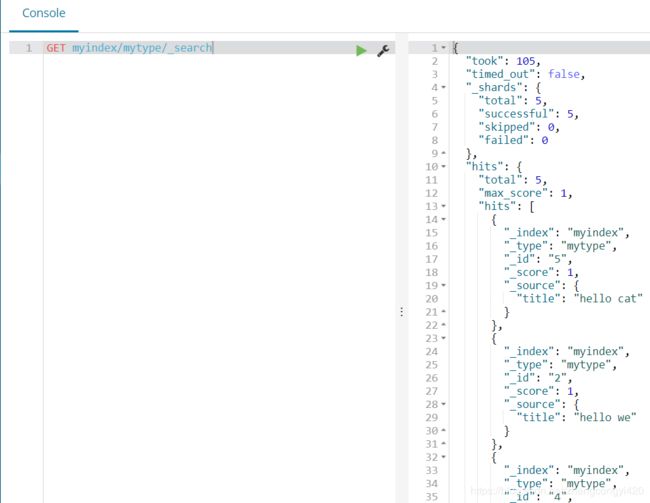
使用match_phrase_prefix进行查询,如果使用"hello w"进行匹配,查询出结果如下,查出4条数据,
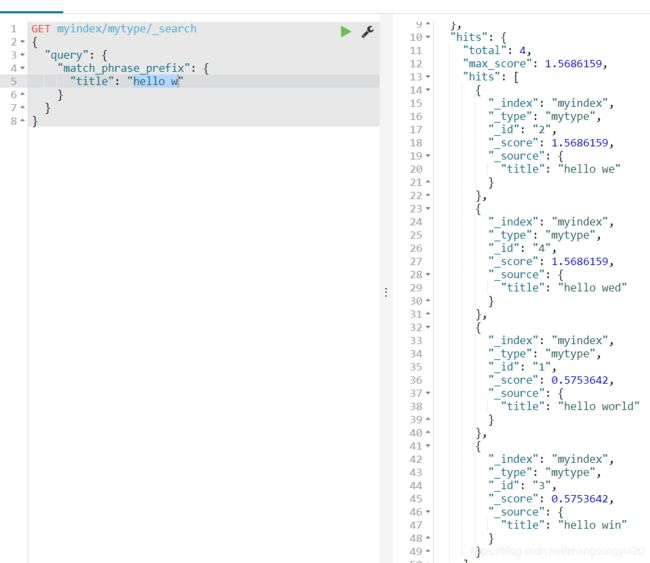
如果使用,"hello we"查询呢?查出了两条数据,可见短语越长,查出的结果越少,同时更加接近预期的documents,

简单说一下match_phrase_prefix的原理吧,还记得我们之前使用过的match_phrase吧,即短语查询,
如果我们使用match_phrase只能查出一条数据,原因是match_phrase是精确匹配的,
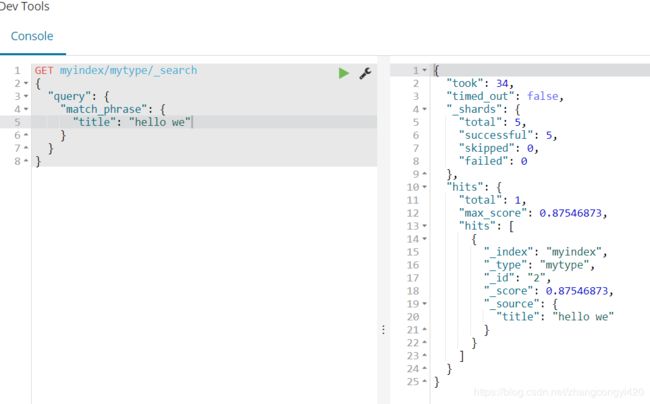
通俗解释就是,假如输入了 hello w,es会立即去文档库中检索相关文档,hello匹配到了立即返回,这时,再以hello w 为前缀到文档库进行类似的前缀匹配,匹配上了再返回所有包含hello w的document,但是总体来说,这种方式由于存在全文检索,总会有以后缀去进行大量的索引扫描,因此数据量小还没什么,数据量大的话,性能并不是特别好,因此接下来看下面的一种方式,即使用ngram实现近实时的搜索推荐,
方式二 ngram
大概介绍一下ngram的使用原理,我们来看一个单词,quick,对于这个单词来说,es可以通过不同的切分方式将quick切分成不同长度的词,
quick,5种长度下的ngram
ngram length=1,q u i c k
ngram length=2,qu ui ic ck
ngram length=3,qui uic ick
ngram length=4,quic uick
ngram length=5,quick
使用edge ngram将每个单词都进行进一步的分词切分,用切分后的ngram来实现前缀搜索推荐功能,使用这种方式搜索,其实就是在搜索之前已经对index下的相关要做搜索的字段进行了字段的拆分,更通俗来讲,就是我们在进行数据插入到index之前,自定义field的edge ngram 切分方式,即自定义分词器,然后在搜索的时候就使用自定义的分词器就可以让edge ngram 规则生效了,
因此,搜索的时候,不用再根据一个前缀,然后扫描整个倒排索引了; 简单的拿前缀去倒排索引中匹配即可,如果匹配上了,就可以了;
下面简单演示一下,
1、自定义分词器,使用edge ngram规则,
min_gram 和 max_gram 指定关键词可以切分的范围,比如如果范围是1-5,那么假如单词是hello,就可以出现上述描述的从1个一直到5个字符的完整过程,
PUT /my_index
{
"settings": {
"analysis": {
"filter": {
"autocomplete_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20
}
},
"analyzer": {
"autocomplete": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"autocomplete_filter"
]
}
}
}
}
}

执行成功之后,我们来测试一下,
GET /my_index/_analyze
{
"analyzer": "autocomplete",
"text": "quick brown"
}
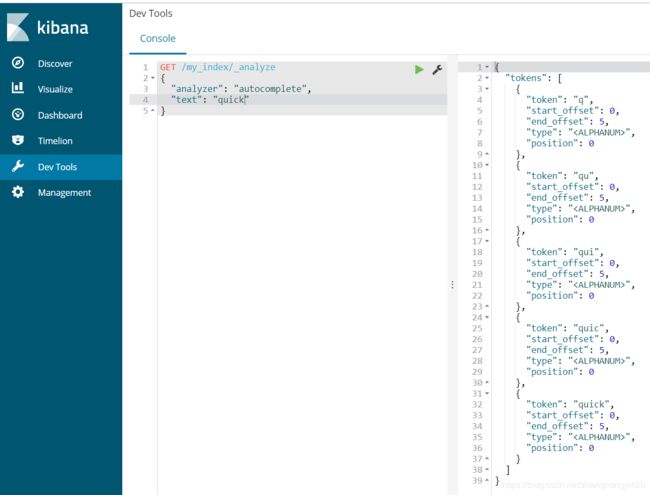
可以看到,通过这种方式,已经达到上面我们所说的效果了,即quick被切分成不同长度的短语了,接下来,指定我们即将插入数据的字段属性,
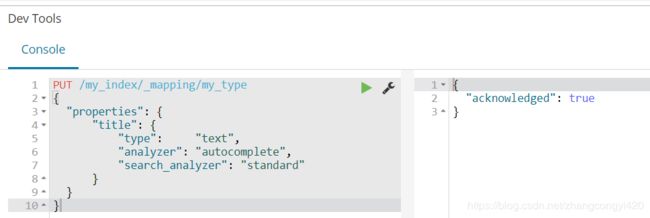
PUT /my_index/_mapping/my_type
{
"properties": {
"title": {
"type": "text",
"analyzer": "autocomplete",
"search_analyzer": "standard"
}
}
}
最后我们插入五条测试数据,直接拷贝上文的五条数据插入即可,


可以看到,同样可以达到预期的效果,但是使用这种方式在进行搜索的时候,服务器的性能会更加高效,当然这里由于没有web界面,不好演示,实际应用中,可以在大批量的数据下,测试一下两种方式的响应时间就可以对比一下效果。
本篇到此结束,最后感谢观看!