工具分享:使用python脚本自动将旧Excel数据更新到新表,提高效率
工具分享:使用python脚本自动将旧Excel数据更新到新表,提高效率
- 背景
- 代码缺陷扫描
- 缺陷修改中的无奈
- python代码实现
- 说明
目的:使用python脚本自动将旧Excel数据更新到新表,提高效率,避免人为遗漏,环境安装好之后,可直接使用
背景
代码缺陷扫描
公司为了提高软件质量,引入了许多工具如pclint对代码进行检查,主要检查编码缺陷,如内存泄漏、不合理的指针强转、内存越界、以及公司的编码规范等,保证代码正式上线之前提前拦截不必要风险,代码检查工具每天都会扫描出一些代码缺陷,每个缺陷都会有唯一的checkid跟踪,缺陷需要修改
缺陷修改中的无奈
如下是连续两天的扫描结果
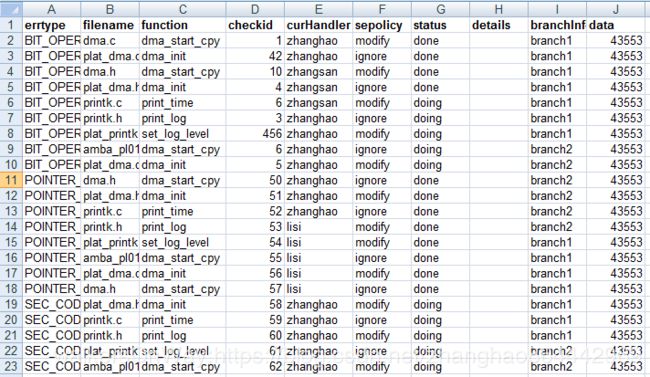
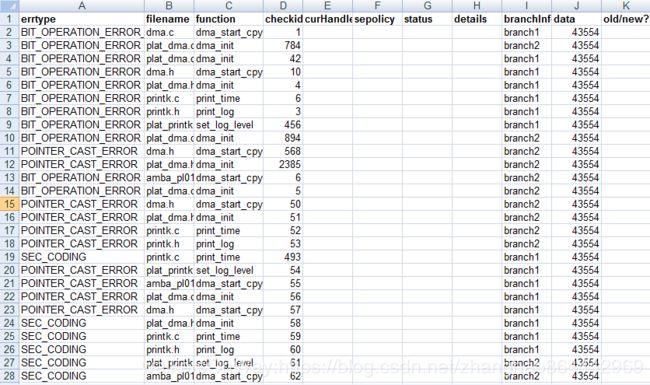
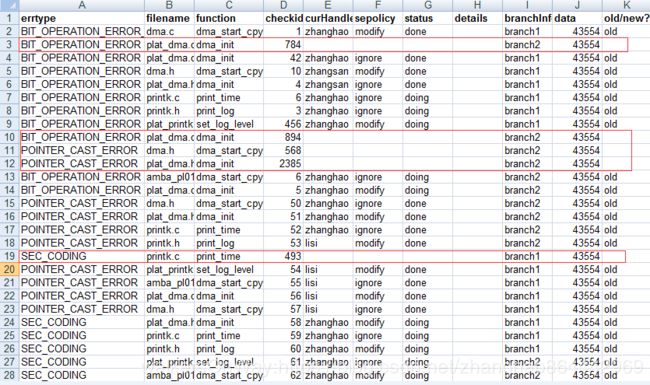
如上图是用0329的数据更新0330的数据,0330新表中只需要处理30号新增的和29号遗留未处理的,脚本既提高了效率,也避免了遗漏
python代码实现
# -*- coding: utf-8 -*-
# import xdrlib ,sys
# Author:walkersOnWay
# Time:2019-03-14
# Environment:python2.7
import xlrd #读取excel数据
import xlwt #创建表格并写入数据
from xlutils.copy import copy #更新已存在的表格数据
class ExcelHelper:
def __init__(self, excelFile, excelSheet):
self.excelFile = excelFile
self.excelSheet = excelSheet
self.nrows = 0
self.ncols = 0
self.__data = self.openExcel(excelFile)
#print "file:sheet = %s, %s; nrows, ncols = %d, %d", self.excelFile, self.excelSheet, self.nrows, self.ncols
#打开文件
def openExcel(self, excelFile):
try:
data = xlrd.open_workbook(excelFile)
return data
except Exception, e:
print str(e)
#根据sheet名读取sheet数据
def getSheetDataByName(self):
listRows = []
table = self.__data.sheet_by_name(self.excelSheet)
self.nrows = table.nrows #行数
self.ncols = table.ncols #列数
for idx in range(0, self.nrows):
listRows.append(table.row_values(idx))
return listRows
#获取单元格数据
def getCellData(self, row, col):
table = self.__data.sheet_by_name(self.excelSheet)
#print "[%d, %d] = " % (row, col), table.cell(row, col).__class__ #此处耗费时间很长,1、在于没返回值 2、返回值的类型不对
print "table.cell(row, col).value", table.cell(row, col).value
return table.cell(row, col).value
#更新单元格数据
def updataCellData(self, row, col, newData):
newDataObj = copy(self.__data) # 类型为worksheet 无nrows 方法
newSheet = newDataObj.get_sheet(1)
newSheet.write(row, col, newData)
newDataObj.save(self.excelFile) #此处需要保存成xls的格式,保存成xlsx会损坏数据,导致打开失败
#获取列数据
def getCol(self, col):
table = self.__data.sheet_by_name(self.excelSheet)
colList = table.col_values(col)
return colList
#打印整张表格数据
def showSheetListRows(self, listRows):
print "file:sheet = %s, %s; nrows, ncols = %d, %d", self.excelFile, self.excelSheet, self.nrows, self.ncols
for tmpList in listRows:
for k in range(0, self.ncols):
print " ", tmpList[k],
print "\n"
class ExcelHandler:
#def __init__(self, oldExcel, newExcel)
def __init__(self, oldExcel, newExcel, handleColIdxList): #改进
self.oldExcel = oldExcel #旧文件
self.newExcel = newExcel #新文件
self.handleColIdxList = handleColIdxList #改进:要处理的列
#用旧表更新新表
def flushSheet(self, oldSheet, newSheet):
oldExcelHelper = ExcelHelper(self.oldExcel, oldSheet)
oldColList = oldExcelHelper.getCol(3)
newExcelHelper = ExcelHelper(self.newExcel, newSheet)
newColList = newExcelHelper.getCol(3)
oldCurRow = 0
newCurRow = 0
for oldVal in oldColList:
newCurRow = 0
for newVal in newColList:
if 0 == oldCurRow or 0 == newCurRow:
newCurRow += 1
continue
if(oldVal == newVal):
#for idx in range(4, 8): #ok
for idx in self.handleColIdxList: #改进,自定义要处理的列
oldExcelHelper = ExcelHelper(self.oldExcel, oldSheet)
newExcelHelper = ExcelHelper(self.newExcel, newSheet)
newExcelHelper.updataCellData(newCurRow, idx, oldExcelHelper.getCellData(oldCurRow, idx))
oldExcelHelper = ExcelHelper(self.oldExcel, oldSheet)
newExcelHelper = ExcelHelper(self.newExcel, newSheet)
newExcelHelper.updataCellData(newCurRow, 10, "old")
newCurRow += 1
oldCurRow += 1
#test
#读取并打印Excel中Sheet数据
#excelHelper1 = ExcelHelper("data/file1.xls", "0329")
#print "3 list is \n", excelHelper1.getCol(3)
#excelHelper1.showSheetListRows(excelHelper1.getSheetDataByName())
#excelHelper2 = ExcelHelper("data/file.xlsx", "0330")
#excelHelper2.showSheetListRows(excelHelper2.getSheetDataByName())
#读写单元格
#excelHelper1.getCellData(2, 3)
#excelHelper1.updataCellData(1, 0, "BIT_OPERATION_ERROR_NEW111222")
#同步两张sheet表格数据
handleColIdxList = [4, 6, 7] #改进:自定义需要更新的列索引
mExcelHandler = ExcelHandler("data/file1.xls", "data/file1.xls", handleColIdxList) #改进
#mExcelHandler = ExcelHandler("data/file1.xls", "data/file1.xls")
mExcelHandler.flushSheet("0329", "0330")
脚本中class ExcelHelper可实现指定sheet数据打印,列数据读取,单元数据读写等操作,Excel读写操作可借鉴此类
说明
- 需安装PyCharm环境,下载地址:https://www.jetbrains.com/pycharm/
- Excel操作需要依赖xlrd、xlwt和xlutils包,需要提前安装,如安装xlutils执行pip install xlutils,其余安装方法类似
- 更新数据后,save时文件名后缀需使用fileName.xls,使用fileName.xlsx会报错
- 测试代码及数据:链接:https://pan.baidu.com/s/1f9xf1StfWGHUA1hE0Ja86A
提取码:5axh