目标检测分割--Mask R-CNN
Mask R-CNN ICCV2017 best paper
https://arxiv.org/pdf/1703.06870
Mask R-CNN= Faster R-CNN + FCN, 大致可以这么理解!
大神都去哪了? Facebook AI Research (FAIR) 越来越厉害了,强强联合
Code will be made available 官方代码暂时没有
https://github.com/felixgwu/mask_rcnn_pytorch
https://github.com/CharlesShang/FastMaskRCNN
Mask-RCNN implementation in MXNet
https://github.com/xilaili/maskrcnn.mxnet
TuSimple
GitHub: https://github.com/TuSimple/mx-maskrcnn
本文主要讲 Faster R-CNN 拓展到图像分割上,提出了 Mask R-CNN 简单快捷的解决 Instance segmentation,什么是 Instance segmentation,就是将一幅图像中所有物体框出来,并将物体进行像素级别的分割提取。如下图示例:

2 Related Work
R-CNN: 基于候选区域的物体检测成为目标检测算法中最流行的的,尤其是 Faster R-CNN 效果很好。
Instance Segmentation: 受到 R-CNN 的影响,大家纷纷采用R-CNN 思路来做 分割,文献【8】提出的 fully convolutional instance segmentation 是效果最好的。但是有明显的问题,如下图所示:

3 Mask R-CNN
Mask R-CNN在概念上是很简单:对于每一个候选区域 Faster R-CNN 有两个输出,一个类别标签,一个矩形框坐标信息。这里我们加了第三个分支用于输出 object mask即分割出物体。
Faster R-CNN: 这里简要回顾一下 Faster R-CNN,它有两个步骤组成,Region Proposal Network (RPN) 用于提取候区域,第二个步骤本质上和Fast R-CNN一样,使用 RoIPool 对候选区域提取特征进行类别分类和坐标回归。用于两个步骤的特征是可以共享的,这样可以提高速度。
Mask R-CNN: Mask R-CNN 也是采用了两个步骤,第一个步骤就是 RPN 提取候选区域,在第二个步骤,平行于预测类别和坐标信息,对于每个 RoI, Mask R-CNN 输出一个二值 mask。这与当前大部分系统不一样,当前这些系统的类别分类依赖于 mask 的预测。我们还是沿袭了 Fast R-CNN 的精神,它将矩形框分类和坐标回归并行的进行,这么做很大的简化了R-CNN的流程。
在训练阶段,我们对每个样本的 RoI 定义了多任务损失函数 L = L_cls + L_box + L_mask ,其中 L_cls 和 L_box 的定义和Fast R-CNN 是一样的。在 mask 分支中对每个 RoI 的输出是 K*m*m,表示K个 尺寸是 m*m的二值 mask,K是物体类别数目,。这里我们使用了 per-pixel sigmoid,将 的损失函数定义为 L_mask average binary cross-entropy,我们的 L_mask 只定义对应类别的 mask损失,其他类别的mask输出不会影响该类别的 loss。
我们定义 L_mask 的方式使得我们的网络在生成每个类别的 mask 不会受类别竞争影响,解耦了mask和类别预测。
Mask Representation: 对于每个 RoI 我们使用 一个 FCN 网络来预测 m*m mask。m*m是一个小的特征图尺寸,如何将这个小的特征图很好的映射到原始图像上?为此我们提出了一个 叫 RoIAlign 的网络层来解决该问题,它在 mask 预测中扮演了重要的角色。
RoIAlign: RoIPool 是一个标准的提特征运算,它从每个 RoI 提取出一个小的特征( 7×7),RoIPool 首先对浮点的 RoI 进行量化,然后再提取分块直方图,最后通过 最大池化 组合起来。这种分块直方图对于分类没有什么大的影响,但是对像素级别精度的 mask 有很大影响。
为了解决上述问题,我们提出了一个 RoIAlign 网络层 解决 RoIPool 量化引入的问题,将提取的特征和输入合适的对应起来。我们的改变也是很简单的:我们避免对 RoI 的边界或 bins 进行量化。使用线性差值精确计算每个 RoI bin 最后组合起来。
Network Architecture: 为了验证我们方法的适应性,我们在不同的网络系统中实现了 Mask R-CNN,这里主要分别考虑了文献【14,21]中的两个系统,如下图所示:
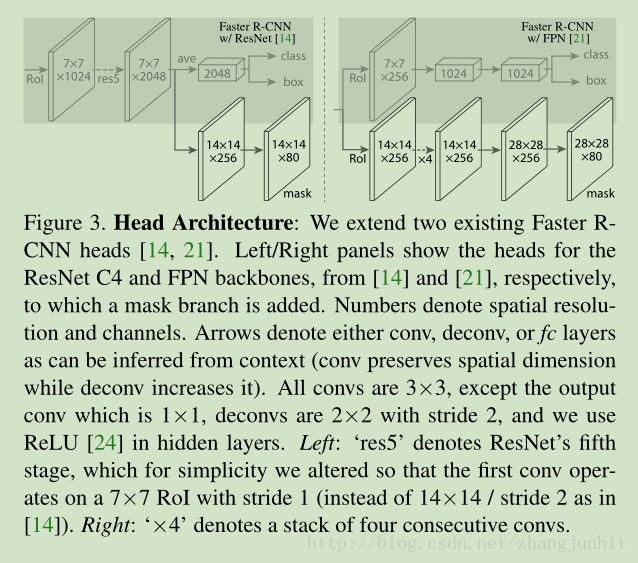
其中采用 FPN 的架构在精度和速度上都更胜一筹。
3.1. Implementation Details
Training: 对于 mask loss L_mask 只在正样本的 RoIs 上面定义。
我们采用文献【9】的图像-中心 训练方法。将图像长宽较小的一侧归一化到 800个像素。在每个 mini-batch 上每个 GPU 有2个图像,每个图像 N个样本 RoIs,正负样本比例 1:3.其中 对于 C4 框架的 N=64, 对 FPN框架的 N=512。在8个GPU上训练,还有其他一些参数设置。
Inference: 在测试阶段,C4的候选区域个数是300, FPN 是 1000.对这些候选区域我们进行坐标回归,再非极大值抑制。然后对前100个得分最高的检测框进行 mask 分支运算。这样做可以提高速度改善精度。在 mask 分支中 ,我们对每个 RoI 给出 K 个 mask预测,但是我们只使用 分类分支给出的那个类别对应的 mask。然后我们将 m×m 浮点 mask 归一化到 RoI 尺寸,使用一个0.5阈值进行二值化。
- Experiments: Instance Segmentation
更多的图片结果:
Instance segmentation:
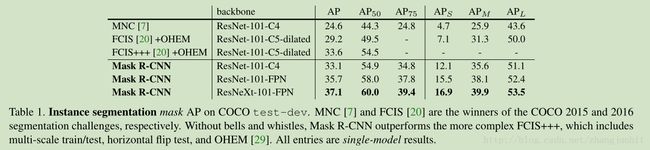
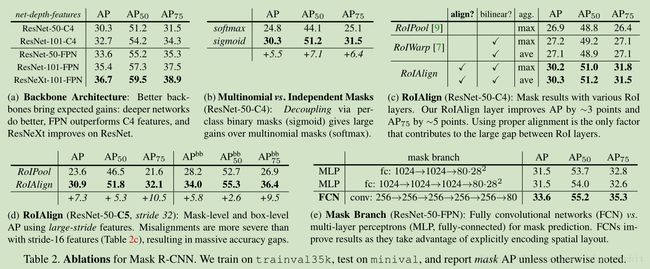
一些对比:
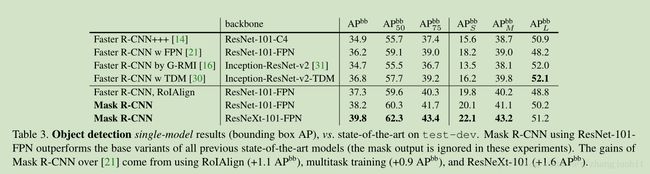
Object detection:
Human Pose Estimation:

4.4. Timing
Inference:
ResNet-101-FPN model runs at 195ms per image on an Nvidia Tesla M40 GPU (plus
15ms CPU time resizing the outputs to the original resolution)
ResNet-101-C4 : ∼400ms