3D人体姿态估计--Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose
Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose
Project and Code: https://www.seas.upenn.edu/~pavlakos/projects/volumetric/
输入一张彩色图像,输出人体 3D姿态信息,采用 CNN网络端对端训练,技术创新点:1)对三维空间进行网格划分,2)Coarse-to-Fine 渐进优化
流程示意图:

3.1. Volumetric representation for 3D human pose
对于3D 人体姿态估计问题,问题的一般定义是 人体N个关节,每个关节有一个 3D 坐标(x,y,z)

上面公式是计算 预测坐标和真值坐标的欧式距离。 尽管这样描述问题很简单明了,但是这个问题是 highly non-linear problem,很难学习。
这里我们对3D 空间进行网格划分, For each joint we create a volume of size w×h×d,对每个关节我们定义一个 w×h×d 的 volume(容积器),将该volume 划分为 w×h×d,假设 p(i,j,k) 表示 一个关节落入容积器的(i,j,k) voxel(三维坐标点)。
同时定义一个关节真值坐标(x,y,x)落入容积器的(i,j,k) voxel 的概率如下:

误差函数定义如下:

上述问题的定义方式能够简化问题的求解。同时也为后面的Coarse-to-fine 提供了好的基础
A major advantage of the volumetric representation is that it casts the highly non-linear problem of direct 3D coordinate regression to a more manageable form of prediction in a discretized space
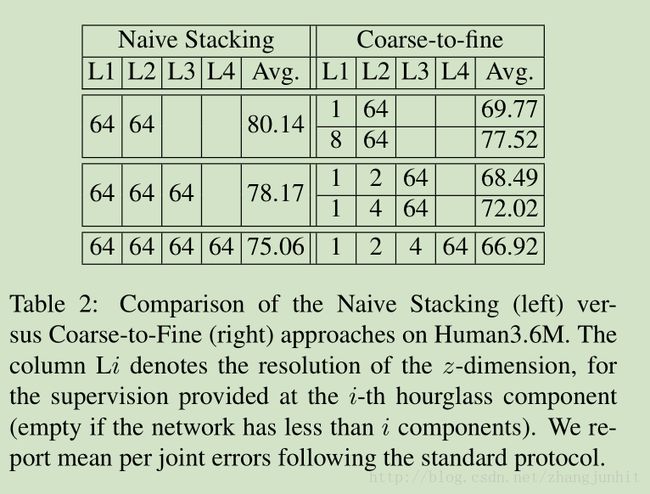
3.2. Coarse-to-fine prediction

注意这里的 Coarse-to-Fine 主要是针对 第三维度深度 z 而言的,深度信息是最难的,2D 已经做的比较成熟了。
In particular, the first steps are supervised with lower resolution targets for the (most challenging and technically unobserved) z-dimension. Precisely, we use targets of size 64 × 64 × d per joint, where d typically takes values from the set {1,2,4,8,16,32,64}
d 的取值为 {1,2,4,8,16,32,64}
3.3. Decoupled architecture with volumetric target
在某些情况下因为关节的 3D 真值数据无法获取 导致不能进行 端对端训练,例如我们使用 in-the-wild images。 这里我们参考 3D Interpreter Network 【35】,进行2步训练。
predicting 2D keypoint heatmaps, followed by an inference step of the 3D joint positions with our volumetric representation
首先预测 2D 关节点heatmaps, 然后在3D 网格空间坐标上进行 3D 关节点坐标推理
The first step can be trained with 2D labeled in-the-wild imagery, while the second step requires only 3D data (e.g., MoCap)
Independently, each of these sources are abundantly available

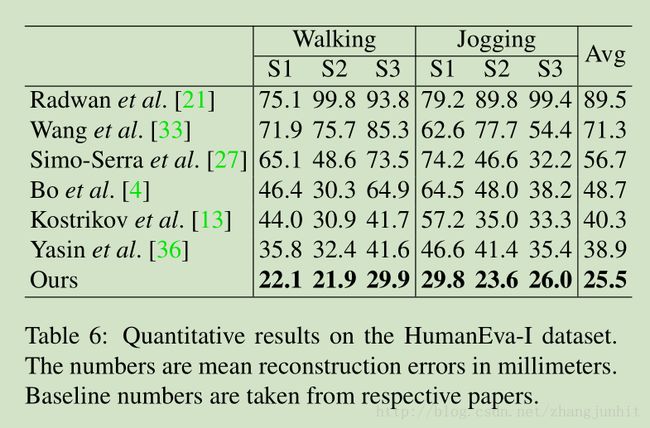
- Empirical evaluation