C++ STL详解
转载自:http://www.cnblogs.com/shiyangxt/archive/2008/09/11/1289493.html
一、STL简介
STL(Standard Template Library,标准模板库)是惠普实验室开发的一系列软件的统称。它是由Alexander Stepanov、Meng Lee和David R Musser在惠普实验室工作时所开发出来
的。现在虽说它主要出现在C++中,但在被引入C++之前该技术就已经存在了很长的一段时间。
STL的代码从广义上讲分为三类:algorithm(算法)、container(容器)和iterator(迭代器),几乎所有的代码都采用了模板类和模版函数的方式,这相比于传统的由函数和类
组成的库来说提供了更好的代码重用机会。在C++标准中,STL被组织为下面的13个头文件:、
二、算法
大家都能取得的一个共识是函数库对数据类型的选择对其可重用性起着至关重要的作用。举例来说,一个求方根的函数,在使用浮点数作为其参数类型的情况下的可重用性肯定比
使用整型作为它的参数类性要高。而C++通过模板的机制允许推迟对某些类型的选择,直到真正想使用模板或者说对模板进行特化的时候,STL就利用了这一点提供了相当多的有用
算法。它是在一个有效的框架中完成这些算法的——你可以将所有的类型划分为少数的几类,然后就可以在模版的参数中使用一种类型替换掉同一种类中的其他类型。
STL提供了大约100个实现算法的模版函数,比如算法for_each将为指定序列中的每一个元素调用指定的函数,stable_sort以你所指定的规则对序列进行稳定性排序等等。这样一来
,只要我们熟悉了STL之后,许多代码可以被大大的化简,只需要通过调用一两个算法模板,就可以完成所需要的功能并大大地提升效率。
算法部分主要由头文件
三、容器
在实际的开发过程中,数据结构本身的重要性不会逊于操作于数据结构的算法的重要性,当程序中存在着对时间要求很高的部分时,数据结构的选择就显得更加重要。
经典的数据结构数量有限,但是我们常常重复着一些为了实现向量、链表等结构而编写的代码,这些代码都十分相似,只是为了适应不同数据的变化而在细节上有所出入。STL容器
就为我们提供了这样的方便,它允许我们重复利用已有的实现构造自己的特定类型下的数据结构,通过设置一些模版类,STL容器对最常用的数据结构提供了支持,这些模板的参数
允许我们指定容器中元素的数据类型,可以将我们许多重复而乏味的工作简化。
容器部分主要由头文件,
向量(vector) 连续存储的元素
列表(list) 由节点组成的双向链表,每个结点包含着一个元素
双队列(deque) 连续存储的指向不同元素的指针所组成的数组
集合(set) 由节点组成的红黑树,每个节点都包含着一个元素,节点之间以某种作用于元素对的谓词排列,没有两个不同的元素能够拥有相同的次序
多重集合(multiset) 允许存在两个次序相等的元素的集合
栈(stack) 后进先出的值的排列
队列(queue) 先进先出的执的排列
优先队列(priority_queue) 元素的次序是由作用于所存储的值对上的某种谓词决定的的一种队列
映射(map) 由{键,值}对组成的集合,以某种作用于键对上的谓词排列
多重映射(multimap) 允许键对有相等的次序的映射
四、迭代器
下面要说的迭代器从作用上来说是最基本的部分,可是理解起来比前两者都要费力一些(至少笔者是这样)。软件设计有一个基本原则,所有的问题都可以通过引进一个间接层来
简化,这种简化在STL中就是用迭代器来完成的
。
概括来说,迭代器在STL中用来将算法和容器联系起来,起着一种黏和剂的作用。几乎STL提供的所有算法都是通过迭代器存取元素序列进行工作的,每一个容器都定义了其本身所专有的迭代器,用以存取容器中的元素。
迭代器部分主要由头文件
----------------------------------------------------分割线---------------------------------------------------------------
以下转自:http://www.cnblogs.com/duoduo369/archive/2012/04/12/2439118.html
学完c++快一年了,感觉很有遗憾,因为一直没有感觉到c++的强大之处,当时最大的感觉就是这个东西的输入输出比C语言要简单好写。
后来我发现了qt,opencv,opengl,原来,c++好玩的狠。
在这些图形库之外,最常用的可能就是STL,这个东西由于当时学c++的时候迷迷糊糊,完全是一头雾水,上学期数据结构之后开始有点儿开窍了,现在把才c++STL中常用的函数,用法贴一下,也是记录一下,希望能给一样迷糊的盆友们一些帮助。
整理自《ACM程序设计》
迭代器(iterator)
个人理解就是把所有和迭代有关的东西给抽象出来的,不管是数组的下标,指针,for里面的、list里面的、vector里面的,抽象一下变成了iterator

1 #include2 #include 3 4 using namespace std; 5 6 int main() 7 { 8 vector v; 9 for(int i = 0; i < 10; ++i ) 10 { 11 v.push_back(i); 12 } 13 for(vector ::iterator it = v.begin(); it != v.end(); ++it) 14 { 15 cout << *it << " "; 16 } 17 cout << endl; 18 return 0; 19 }

求和(
accumulate(v.begin(),v.end(),0),把从 v.begin() 开始到 v.end()结束所有的元素加到 0上面去
 View Code
View Code
vector(动态数组)
vector有内存管理的机制,也就是说对于插入和删除,vector可以动态调整所占用的内存空间。
vector相关函数
#include#include using namespace std; int main() { vector v; v.push_back(3); //数组尾部插入3 v.push_back(2); v.push_back(1); v.push_back(0); cout << " 下标 " << v[3] << endl; cout << " 迭代器 " << endl; for(vector ::iterator i = v.begin();i!= v.end();++i) { cout << *i << " "; } cout << endl; //在第一个元素之前插入111 insert begin+n是在第n个元素之前插入 v.insert(v.begin(),111); //在最后一个元素之后插入222 insert end + n 是在n个元素之后插入 v.insert(v.end(),222); for(vector ::iterator i = v.begin();i!= v.end();++i) { cout << *i << " "; } cout << endl; vector arr(10); for(int i = 0; i < 10; i++) { arr[i] = i; } for(vector ::iterator i = arr.begin();i!= arr.end();++i) { cout << *i << " "; } cout << endl; //删除 同insert arr.erase(arr.begin()); for(vector ::iterator i = arr.begin();i!= arr.end();++i) { cout << *i << " " ; } cout << endl ; arr.erase(arr.begin(),arr.begin()+5); for(vector ::iterator i = arr.begin();i!= arr.end();++i) { cout << *i << " " ; } cout << endl ; return 0 ; }

数组转置 (
reverse(v.begin(),v.end())
View Code

排序(
sort(v.begin(),v.end())
View Code
字符串(
输入
View Code

尾部添加字符字符串直接用+号 例如: s += 'a'; s += "abc",或者使用append方法,s.append(“123”)
删除 (erase clear)
s.erase(it + 1,it + 4); clear()
View Code

查找(find)
用find找到string里面第一个要找到元素(char或者串),找到返回数组下标,找不到返回end()迭代器
string和vector有很多相同的东西,比如length(),size(),empty(),reverse(),相对也容易,就不一一说了。
数字化处理(string)
经常会遇到这样一种情况,有一个数字,需要把每一位给提取出来,如果用取余数的方法,花费的时间就会很长,所以可以当成字符串来处理,方便、省时。
例子:求一个整数各位数的和
View Code
string与char *
View Code
sscanf
View Code

string与数值相互转换( sprintf
View Code
set容器
set是用红黑树的平衡二叉索引树的数据结构来实现的,插入时,它会自动调节二叉树排列,把元素放到适合的位置,确保每个子树根节点的键值大于左子树所有的值、小于右子树所有的值,插入重复数据时会忽略。set迭代器采用中序遍历,检索效率高于vector、deque、list,并且会将元素按照升序的序列遍历。set容器中的数值,一经更改,set会根据新值旋转二叉树,以保证平衡,构建set就是为了快速检索(python中的set一旦建立就是一个常量,不能改的)。

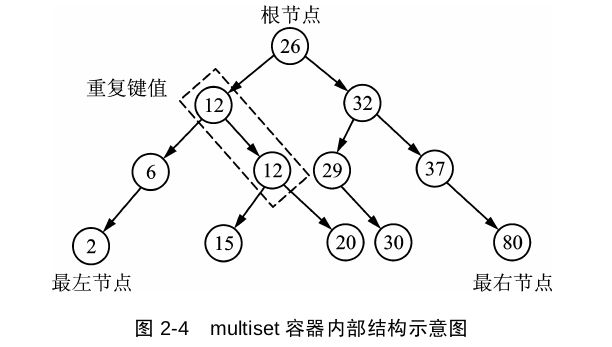
multiset,与set不同之处就是它允许有重复的键值。
正反遍历,迭代器iterator、reverse_iterator
View Code

自定义比较函数,insert的时候,set会使用默认的比较函数(升序),很多情况下需要自己编写比较函数。
1、如果元素不是结构体,可以编写比较函数,下面这个例子是用降序排列的(和上例插入数据相同):
View Code

2、元素本身就是结构体,直接把比较函数写在结构体内部,下面的例子依然降序:
View Code

multiset与set的不同之处就是key可以重复,以及erase(key)的时候会删除multiset里面所有的key并且返回删除的个数。
map
map也是使用红黑树,他是一个键值对(key:value映射),便利时依然默认按照key程序的方式遍历,同set。

View Code

用map实现数字分离
string --> number
之前用string进行过数字分离,现在使用map
View Code

number --> string
View Code

multimap
multimap由于允许有重复的元素,所以元素插入、删除、查找都与map不同。
插入insert(pair
View Code
至于删除和查找,erase(key)会删除掉所有key的map,查找find(key)返回第一个key的迭代器
deque
deque和vector一样,采用线性表,与vector唯一不同的是,deque采用的分块的线性存储结构,每块大小一般为512字节,称为一个deque块,所有的deque块使用一个Map块进行管理,每个map数据项记录各个deque块的首地址,这样以来,deque块在头部和尾部都可已插入和删除元素,而不需要移动其它元素。使用push_back()方法在尾部插入元素,使用push_front()方法在首部插入元素,使用insert()方法在中间插入元素。一般来说,当考虑容器元素的内存分配策略和操作的性能时,deque相对vectore更有优势。(下面这个图,我感觉Map块就是一个list< map

插入删除
遍历当然可以使用下标遍历,在这里使用迭代器。
View Code
list
list
插入:push_back尾部,push_front头部,insert方法前往迭代器位置处插入元素,链表自动扩张,迭代器只能使用++--操作,不能用+n -n,因为元素不是物理相连的。
遍历:iterator和reverse_iterator正反遍历
删除:pop_front删除链表首元素;pop_back()删除链表尾部元素;erase(迭代器)删除迭代器位置的元素,注意只能使用++--到达想删除的位置;remove(key) 删除链表中所有key的元素,clear()清空链表。
查找:it = find(l.begin(),l.end(),key)
排序:l.sort()
删除连续重复元素:l.unique() 【2 8 1 1 1 5 1】 --> 【 2 8 1 5 1】
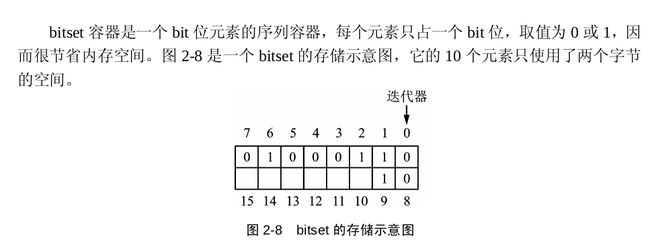
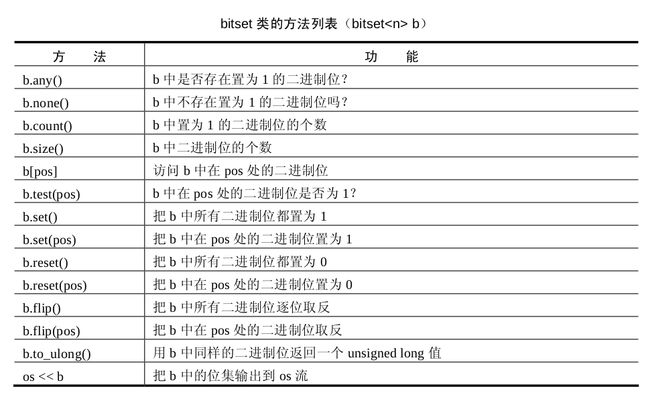
bitset
从来没用过,上两幅图吧就:
stack(后进先出)
这个印象深刻,学数据结构的时候做表达式求值的就是用的栈。

View Code
stack然我唯一费解之处在于,貌似它没有iterator,可以试试s.begin()编译器报错的。
queue(先进先出)

queue有入队push(插入)、出队pop(删除)、读取队首元素front、读取队尾元素back、empty,size这几种方法
priority_queue(最大元素先出)

![]()
View Code

重载操作符同set重载操作符。