麦克风阵列语音增强(一)
1. 引言
对于语音增强的研究,基本上可以划分成两大分支:单通道的语音增强算法和麦克风阵列的语音增强算法(也称为,多通道的语音增强算法)。麦克风阵列的语音增强方法的优势在于考虑了声源的位置信息,可以实现空间滤波,所以对具有方向性的噪声具有较好的抑制效果。因此,麦克风阵列的技术在抑制一些具有方向性的干扰语音上应用较广。波束形成,这个词也就是这么来的。因为对期望方向的语音信号进行保留,抑制非期望方向的信号,其实就是在做语音信号的波束形成。对于麦克风阵列波束形成的研究主要可分成三类:固定波束形成、自适应波束形成和后置滤波算法,如下图1-1所示。
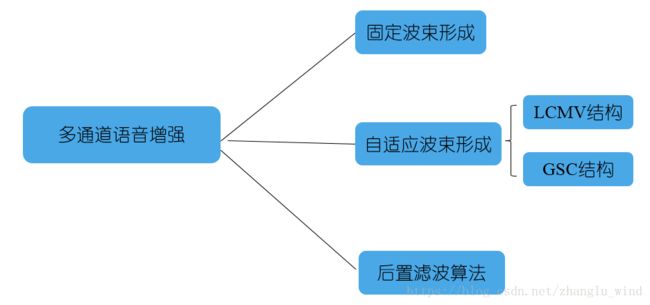
图 1-1 麦克风阵列波束形成算法分类
固定波束形成,适用于稳定不变的噪声干扰环境,可以对某一方向的声源进行抑制,抑制的强度不变,因此灵活性较低。当环境中的噪声信号发生变化时,固定波束形成的算法并不能跟随着作出调整,鲁棒性不好,但其运算复杂度低,算法的可实现性强。自适应波束形成的方法,可以利用信号的输出来自适应地调整滤波的权重系数,其抑制性能可以对环境信号的变化作出调整,鲁棒性更好,波束形成更加灵活。但是波束形成的方法不仅会残留一部分噪声,而且对有些噪声的抑制能力不强,所以就有了把单通道的方法和麦克风阵列相结合的方法,也就是图1-1中所示的后置滤波算法。下面将分别介绍一下三种不同类型的波束形成方法。
2. 固定波束形成
最早也是最经典的固定波束形成算法,是由Flanagan提出的。他借鉴了天线阵列信号处理中的思想,利用简单的延时-求和的方法,来实现对噪声的抑制。其基本的算法框图如下图1-2所示。
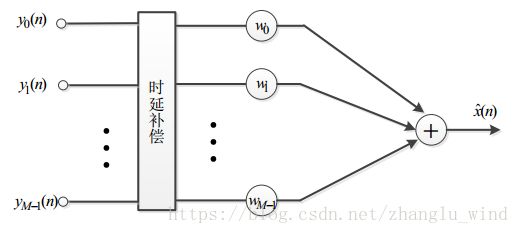
图1-2 Flanagan 提出的固定波束形成算法
首先,不同的麦克风由于位置不同,所以接收的语音信号必定存在着时间偏差。所以,所有的麦克风阵列算法要做的第一件事,就是信号对齐,也就是图1-2中的时延补偿部分所实现的。其次,在Flanagan的算法中,只采用了固定的单个权重来约束每一路麦克风通道的信号(最简单的情况是,所有的权重系数w都取![]() ),因此其消噪能力十分有限,只能实现对非相干噪声的抑制,对于相干噪声基本没有什么抑制能力,并且消噪能力的强弱主要取决于麦克风的数量M,输出的信噪比可提高
),因此其消噪能力十分有限,只能实现对非相干噪声的抑制,对于相干噪声基本没有什么抑制能力,并且消噪能力的强弱主要取决于麦克风的数量M,输出的信噪比可提高![]() ,所以局限性很大,成本也相对较高。那么,针对这些问题,固定波束形成的语音增强算法也有相应的改善措施,那就是利用抽头延迟线结构(TDLs,Tapped Delay-lines)来实现对宽带语音信号的波束形成,其具体结构如下图1-3所示。
,所以局限性很大,成本也相对较高。那么,针对这些问题,固定波束形成的语音增强算法也有相应的改善措施,那就是利用抽头延迟线结构(TDLs,Tapped Delay-lines)来实现对宽带语音信号的波束形成,其具体结构如下图1-3所示。
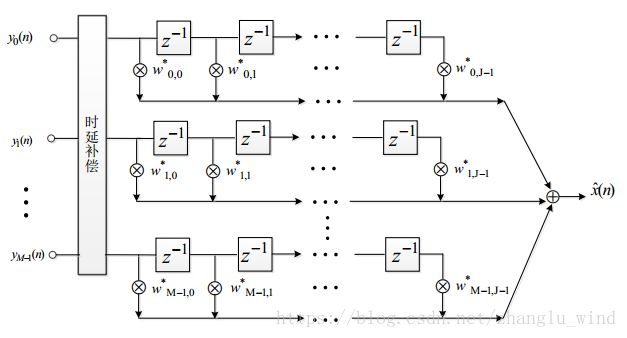
图 1-3 TDLs结构的固定波束形成
TDLs结构的固定波束形成算法,通过多抽头的延迟来产生不同频率的分量,然后通过滤波系数![]() 来约束各麦克风的输入信号,使得期望方向上的信号得到保留,并在非期望方向上形成零陷,从而实现对固定声源方向的波束形成。这种方法可以对固定噪声源方向的信号进行抑制,并且对相干和非相干噪声都能实现有效地抑制。TDLs的算法思想可以用下面的方程(2-1)进行描述:
来约束各麦克风的输入信号,使得期望方向上的信号得到保留,并在非期望方向上形成零陷,从而实现对固定声源方向的波束形成。这种方法可以对固定噪声源方向的信号进行抑制,并且对相干和非相干噪声都能实现有效地抑制。TDLs的算法思想可以用下面的方程(2-1)进行描述:
 (2-1)
(2-1)
在式(2-1)中,矩阵D为方向矩阵,用来对不同角度的语音信号进行频域对齐(也就是图1-3中的时延补偿部分),其中用虚线隔开的部分分别为不同入射角度的语音信号,![]() ,
,![]() ,…,
,…,![]() 分别代表了不同的频率分量,
分别代表了不同的频率分量,![]() ,
,![]() ,…,
,…,![]() 代表了不同的麦克风所对应是时间延迟。矩阵F是目标响应矩阵,同样地,用虚线隔开的部分分别对应着不同入射角度信号的目标响应。通过设置目标响应矩阵F,就可以决定固定波束形成结构对哪些方向的语音信号进行保留,又对哪些方向的语音信号进行抑制。矩阵W是权重系数矩阵,也是TDLs结构需要设计的部分,通过求解方程(2-1),得到的矩阵系数解
代表了不同的麦克风所对应是时间延迟。矩阵F是目标响应矩阵,同样地,用虚线隔开的部分分别对应着不同入射角度信号的目标响应。通过设置目标响应矩阵F,就可以决定固定波束形成结构对哪些方向的语音信号进行保留,又对哪些方向的语音信号进行抑制。矩阵W是权重系数矩阵,也是TDLs结构需要设计的部分,通过求解方程(2-1),得到的矩阵系数解![]() ,便是最终需要的设计的滤波器系数。
,便是最终需要的设计的滤波器系数。
3. 自适应波束形成
自适应波束形成的主要思想是利用信号的输出来自适应地调整类似TDLs结构中的权重系数![]() ,来达到对声学环境的变化具有一定鲁棒性的目的。在自适应的波束形成算法中,主要由两种典型的实现结构:LCMV结构和GSC结构,两种结构均有时域和频域的实现方法。由于时域的实现方法更加简单,且具有较好的实时性,所以下面重点介绍LCMV和GSC结构的经典时域实现方法。
,来达到对声学环境的变化具有一定鲁棒性的目的。在自适应的波束形成算法中,主要由两种典型的实现结构:LCMV结构和GSC结构,两种结构均有时域和频域的实现方法。由于时域的实现方法更加简单,且具有较好的实时性,所以下面重点介绍LCMV和GSC结构的经典时域实现方法。
Frost 最早提出了经典的时域LCMV自适应波束形成结构,如下图1-4所示。
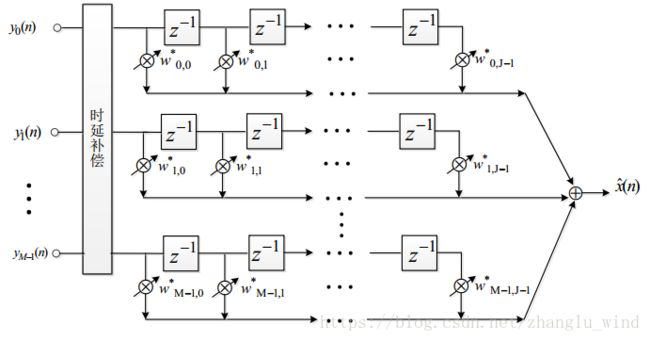
图 1-4 时域LCMV自适应波束形成结构
时域LCMV算法的基本思想可以用式(3-1)和(3-2)进行描述:
其实,LCMV的方法就是在TDLs固定波束形成的基础上,增加了式子(3-2)中的自适应系数调整部分。其中,![]() 为输入信号Y的自相关矩阵的期望(一般用
为输入信号Y的自相关矩阵的期望(一般用![]() 来进行估算),通过最小化输出功率来自适应地调整权重系数W。而这里式(3-1)的作用和TDLs结构的固定波束形成是一样的,可以保证目标方向的信号得到保留,干扰目标方向的信号得到抑制。求解方程(3-1)和(3-2),便可以得到系数矩阵W的值:
来进行估算),通过最小化输出功率来自适应地调整权重系数W。而这里式(3-1)的作用和TDLs结构的固定波束形成是一样的,可以保证目标方向的信号得到保留,干扰目标方向的信号得到抑制。求解方程(3-1)和(3-2),便可以得到系数矩阵W的值:
为了进一步避免矩阵求逆,可以采用LMS的方法进行迭代求解,如下所示:
其中,I为单位矩阵,D是设计的方向矩阵,F是目标响应矩阵,![]() 为迭代步长。当然为了进一步简化方向矩阵D的设计,Frost 在最小方差无畸变准则(MVDR)的基础上,提出了如下所示的方向矩阵D和目标响应矩阵F设计形式:
为迭代步长。当然为了进一步简化方向矩阵D的设计,Frost 在最小方差无畸变准则(MVDR)的基础上,提出了如下所示的方向矩阵D和目标响应矩阵F设计形式:
 (3-5)
(3-5)
除了上述的时域LCMV自适应波束形成结构,Griffiths 在LCMV结构的基础上进行改进,得到了一种无约束的时域GSC结构,如下图1-5所示。
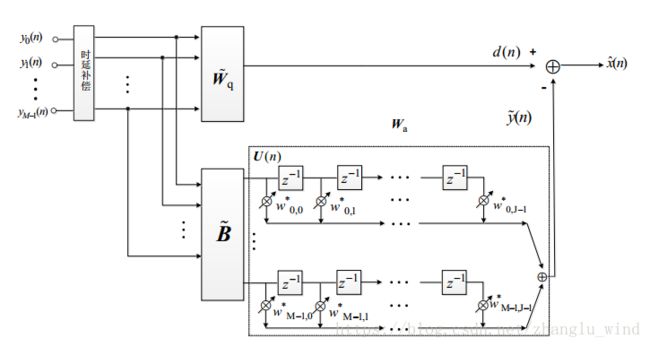
图 1-5 时域GSC自适应波束形成结构
上图所示的GSC算法主要由三部分构成:固定波束形成部分(![]() )、阻塞矩阵部分(
)、阻塞矩阵部分(![]() )和自适应波束形成部分(
)和自适应波束形成部分(![]() )。其中,固定波束形成部分只能让特定方向的信号通过,而阻塞矩阵部分可以阻止特定方向的信号通过,让其他方向的信号通过。这么设计的原因是,固定波束形成部分的输出中肯定会残留一部分其他方向的信号,那么可以通过对阻塞矩阵(
)。其中,固定波束形成部分只能让特定方向的信号通过,而阻塞矩阵部分可以阻止特定方向的信号通过,让其他方向的信号通过。这么设计的原因是,固定波束形成部分的输出中肯定会残留一部分其他方向的信号,那么可以通过对阻塞矩阵(![]() )的输出进行权重调整(
)的输出进行权重调整(![]() )来估计出固定波束形成部分(
)来估计出固定波束形成部分(![]() )残留的噪声,最后进行减法操作,便可以得到最终的纯净语音信号的估计。那么,对于自适应矩阵
)残留的噪声,最后进行减法操作,便可以得到最终的纯净语音信号的估计。那么,对于自适应矩阵![]() 的求解就转化成了如下所示的无约束求解问题:
的求解就转化成了如下所示的无约束求解问题:
 (3-6)
(3-6)
同样地,为了避免矩阵求逆运算,采用LMS自适应迭代的方法进行求解,得到如下表达式:
其中,![]() ,
,![]() 是阻塞矩阵
是阻塞矩阵![]() 的输出,满足:
的输出,满足:![]() 。此外,Griffiths采用级联差分方法(CCD)和MVDR准则来对阻塞矩阵和固定波束形成部分进行了简化,得到了如下的设计形式:
。此外,Griffiths采用级联差分方法(CCD)和MVDR准则来对阻塞矩阵和固定波束形成部分进行了简化,得到了如下的设计形式:
 (3-8)
(3-8)
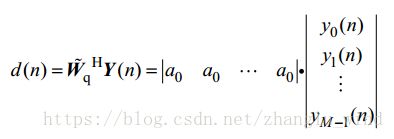 (3-9)
(3-9)
通常情况下,![]() 取
取![]() ,那么就得到了类似Flanagan形式的固定波束形成结构。此外,Griffiths提出的时域GSC算法,可以有效地抑制相干噪声的影响,但是对非相干噪声的抑制能力有限,因为非相干噪声的抑制只能依靠类似Flanagan的固定波束形成部分,所以抑制能力不强。但是,相较于固定波束形成的算法,GSC的方法使用较少的麦克风就能取得十分不错的噪声抑制效果,并且算法运算复杂度也不高,所以在工程中的应用较广泛,在麦克风阵列语音增强专题(二)中将详细介绍这种算法的优缺点。
,那么就得到了类似Flanagan形式的固定波束形成结构。此外,Griffiths提出的时域GSC算法,可以有效地抑制相干噪声的影响,但是对非相干噪声的抑制能力有限,因为非相干噪声的抑制只能依靠类似Flanagan的固定波束形成部分,所以抑制能力不强。但是,相较于固定波束形成的算法,GSC的方法使用较少的麦克风就能取得十分不错的噪声抑制效果,并且算法运算复杂度也不高,所以在工程中的应用较广泛,在麦克风阵列语音增强专题(二)中将详细介绍这种算法的优缺点。
4. 后置滤波算法
后置滤波算法是为了进一步对固定波束形成和自适应波束形成结构的残余噪声进行处理所设计的算法,它可以有效地弥补之前结构存在的不足,去除残留的相干和非相干噪声。最早利用后置滤波思想的是,Zelinski提出的一种对延时-求和波束形成进行改进的后置滤波算法,如下图1-6所示。
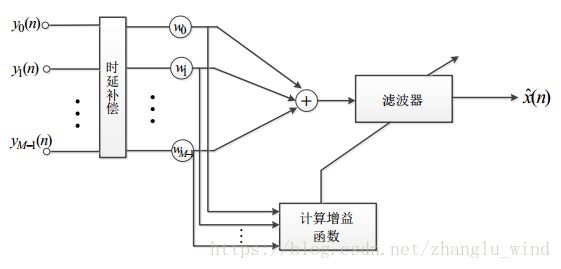
图 1-6 Zelinski 提出的后置滤波算法结构
如上图1-6所示,Zelinski提出的后置滤波算法以维纳滤波算法为基础,利用多通道的信息,求解Wiener-Hopf方程得到如下所示的增益函数表达式:
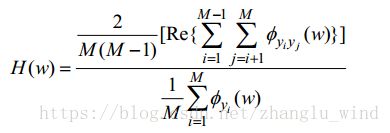 (4-1)
(4-1)
其中,![]() 是第 i 个和第 j 个麦克风信号之间的互功率谱,
是第 i 个和第 j 个麦克风信号之间的互功率谱,![]() 是第 i 个麦克风信号的自功率谱。这样,就得到了多通道维纳滤波的频域增益函数表达形式,再利用IFFT将其变化到时域来实现最后的滤波。虽然Zelinski的这种多通道后置滤波的方法可以有效地去除延时-求和的固定波束形成算法中残留的非相干噪声,但是并不能消除环境中的相干噪声。所以,就有了将GSC自适应结构和后置滤波器相结合的方法(Cohen 和 Gannot 于2004年提出的),如下图1-7所示。
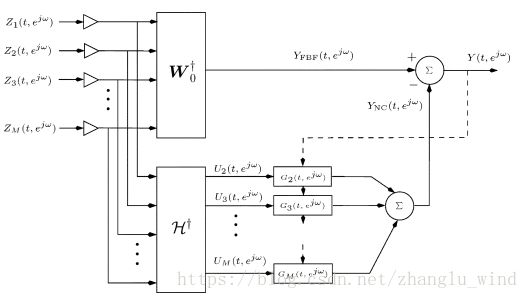
是第 i 个麦克风信号的自功率谱。这样,就得到了多通道维纳滤波的频域增益函数表达形式,再利用IFFT将其变化到时域来实现最后的滤波。虽然Zelinski的这种多通道后置滤波的方法可以有效地去除延时-求和的固定波束形成算法中残留的非相干噪声,但是并不能消除环境中的相干噪声。所以,就有了将GSC自适应结构和后置滤波器相结合的方法(Cohen 和 Gannot 于2004年提出的),如下图1-7所示。
(a)
(b)
图 1-7 (a) 为频域的GSC自适应算法实现方法,(b)是其后置滤波的改善方法
Gannot 和 Cohen 提出的这种后置滤波结构,将频域GSC算法和Log-MMSE的单通道算法相结合。不同的是,这里后置的log-MMSE估计器,利用了GSC算法中阻塞矩阵输出的多通道信息来进行log-MMSE增益函数的估计。这种结构的后置滤波算法,不仅仅可以有效地去除具有明确方向性的相干和非相干噪声残留,甚至对于无方向性的散漫噪声也具有很好的抑制作用。
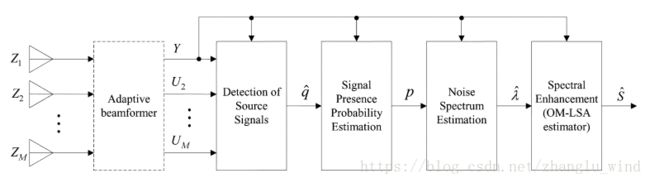
除了上述两种利用多通道信息去计算单通道增益函数的方法,在后置滤波的研究中,还有一类直接级联单通道语音增强算法的方法(也就是,在麦克风阵列算法处理后得到的单通道输出基础上,直接级联第二级单通道后置滤波器的方法),通常级联的是维纳滤波器,除此之外,还有一些直接级联谱减法、MMSE估计器的方法,如下图1-8所示(王冬霞,级联谱减法的后置滤波方法)。
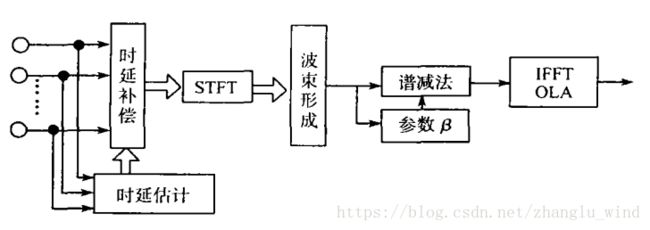
图 1-8 王冬霞提出的基于固定波束形成的后置谱减算法
这类直接级联后置滤波器的方法,最大的好处是:单通道的降噪算法对所有的噪声(无论是相干噪声还是非相干噪声,有方向性的还是无方向性的噪声)都有抑制有用。也就意味着,无论前面的麦克风阵列部分残留的是哪种噪声,直接级联的单通道算法都可以进行抑制。虽然这种后置滤波方法的思想比较简单,但效果比较显著,因此在实际工程中也很有用武之地。
参考文献:
- Liu W, Weiss S. Wideband Beamforming: Concepts and Techniques[M]. Wiley Publishing, 2010:26-29.
- Flanagan J L, Johnston J D, Zahn R, et al. Computer-steered microphone arrays for sound transduction in large rooms[J]. Acoustical Society of America Journal, 1985, 78(5):S52-S52.
- Frost, O. An Algorithm For Linearly Constrained Adaptive Array Processing[J]. IEEE, 1972, 60(8):926–935.
- Griffiths L J, Jim C W. An alternative approach to linear constrained adaptive beamforming[J]. IEEE Trans Antennas & Propag, 1982, 30(1):27-34.
- Zelinski R. A microphone array with adaptive post-filtering for noise reduction in reverberant rooms[C]. IEEE International Conference on Acoustics, Speech, and Signal Processing, 1988(5):2578-2581.
- Gannot S, Cohen I. Speech enhancement based on the general transfer function GSC and postfiltering[J]. IEEE Transactions on Speech & Audio Processing, 2004, 12(6):561-571.
- 王冬霞, 殷福亮. 联合波束形成与谱减法的麦克风阵列语音增强算法[J]. 大连理工大学学报, 2006, 46(1):121-126.