转载_关于AEC算法的几点思考
一年前我剖析过开源的AEC算法,文章链接是语音增强和语音识别;时隔这么长时间,再过来看这个算法,略有体会,以下有几点个人思考:
AEC算法的主要目的是自身音源消除,对于手机或者pc这类的通话场景,这类场景和音响场景稍有差异,两者遇到的主要问题会有些差异;
对于视频通话这类场景,两个通信终端的时钟偏斜和漂移是不定的,而音箱场景这个是可以在硬件上加以解决的,但是音箱场景的非线性失真却比通信场景严重的,功率放大模块非线性器件带来的谐波失真,在室内四个方向都发声,是得卷积失真,多次反射回声,声音突变等会加剧问题处理的复杂性;
当前绝大部分的AEC算法基本都基于频域分块处理方法,基于LMS/NLMS、RLS(recursive least square), APA(Affine Projection Algorithm)自适应处理方法。
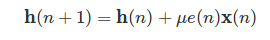
LMS算法主要的作用消除线性回声部分,也就是参考信号x中可以经过线性叠加的方式获得麦克风采集到的回声信号的估计值,上述公式中的h是滤波器系数,
mumu
是步长因子;e是误差信号;
LMS算法对输入信号的频谱和功率敏感,步长因子的选取直接影响收敛速度和稳定性,对于稳定性要求步长因子小于输入信号协方差矩阵的迹导数(实际中很少计算,采用定长步长),
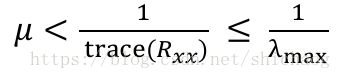
对于要求高的场景会选择根输入信号的功率对步长进行归一化,即NLMS算法,

β是归一化的步长因子, 。为了防止分母为零,加小数a,得如下:
。为了防止分母为零,加小数a,得如下:

这样收敛速度和输入信号的功率绝对值无关。但是这两种算法在输入信号相关性很高时,收敛速度都会较慢。RLS算法准则是最小均分误差。其收敛速度块,是用于非稳态信号。其算法实现如下:
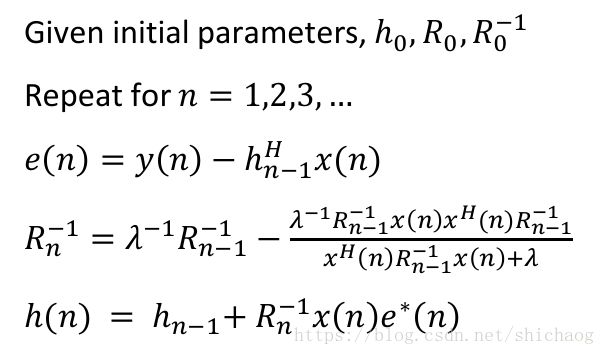
思考1:
1.步长因子$mu$如何选择?理想的步长因子是:

但是实际上
h^h^
是未知的,这也意味这步长因子是无法直接求出的,有些算法直接选择了定长的步长因子(针对场景调节一个因子),但如果步长因子过大,则收敛的速度相应变快,直观的感受是当音乐突然变化(鼓声起)等时,能够快速压制,这也容易造成过冲,使得失调反而变大,这是因为误差信号的估计并不是每时每刻都很准,尤其在double-talk出现时更是如此;在音箱场景中不宜采用固定步长因子的,音箱场景涵盖的过于复杂,不像通信场景可以得到一个收敛延迟和压制效果较为满意的均衡点。这个步长因子应该根据采集到的参考信号x以及误差信号e之间关系变化,当然为了防止抖动,对其自身的平滑还是需要。可以从x的时间序列得到输入信号的变化,这个变化是源头上可以反映参考信号变动的,另外误差信号e是另一个指标来反映,尽管e能够加速收敛过程,当e失调时也该适当的增加mu,这样mu可以看成是一个和x序列以及e序列相关的变量;以下是通过算法来跟新步长因子$\mu$(\$lambda$)的方法。
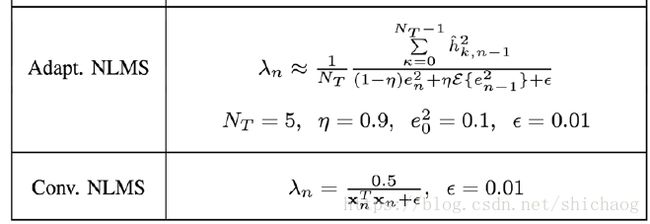
由于观测信号和滤波器系数都是分块(重叠相加法或重叠保留法均可实现)方法,这就为实时性提供了保障。在LMS方法做或许的非线性滤波时系步长的更新也可以采用这里的方法。
此外还有基于贝叶斯网络的理论计算LMS方法中步长的选择的。
2.关于误差信号,LMS消除的是线性部分,得到的是残余线性部分和非线性部分之和,非线性部分来源于外接的噪声,参考源的卷积响应以及喇叭或者传输路径带来的非线性,对于从四面八方接收信号场景而言,非线性还是比较明显,所以必须引入非线性处理方法,有最小均放误差方法,但是这一方法并不好,实际上webrtc就是采用这个准则,尤其是在double-talk发生时更是如此。这个方法认为,如果能够消除噪声,则得到的最终能量值将最小,这在同一时刻只有一方说话时是成立的,但是当双方都在说话时,使用误差能量最小这一准则显然不适用,这就是很多人会提到的吞字(英文文献里称之为clipping)现象。只有把字吞掉,能量才会小,这样这个没有double-talk检测算法必然的结果。
3.所以针对非线性信号(NL-processing),非线性问题在有些文献中又被称为REC(residual echo control),这些
,需要一个方法把非线性部分消掉而不损伤double-talk时发生“误杀现象”,首先谈如何消掉非线性部分,可以将原始信号x通入滤波器中,使用滤波器来近似非线性响应函数,这样也会得到非线性估计,实际上最早开始部分提到的误差信号e是减去了线性和非线性部分得到的误差信号,滤波器系数可以通过最小能量均分来做为准则进行平滑。非线性部分目前来说算是各个AEC最大的差异体现吧,通常希望滤波器阶数较高,能够处理较长的时间长度(即信号经过多次反射到达的场景)。比较有名的处理的滤波器是volterra 滤波器,使用一阶,二阶和三阶滤波器来去除非线性部分,但随着阶数的增加,计算量也呈现指数方式增加,其一阶的表示式如下:
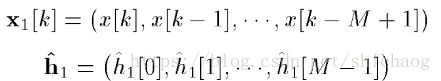
二阶的表示如下:

则误差信号可以表示为:
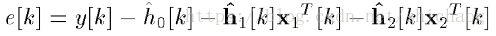
则滤波器的系数跟新方式如下:

这里就涉及到三个步长跟新的速率了,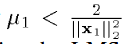 ,
, ,当0<$\alpha$<2时,是收敛的。
,当0<$\alpha$<2时,是收敛的。
4.自适应算法的迭代跟新,这要通过DTD(double-talk detection)来区别对待,实际中发现确实是有用的,可以降低对语音的损伤,但是还不够,最好是一个比较调节而不是检测到DTD条件时当即停止相关系数的跟新。DTD检测算法有能量算法,还有基于几个信号综合的互功率谱估计,也有直接通过信号的互相关性估计。
5.端到端的处理
对于ASR而言,AEC是为了获得近端的人声特征(MFCC或者FBANK),传统的AEC(场景电话,VOIP之类)得到近端信号给人耳听的,它们主要是使用频域特征做自适应滤波,如果我们的AEC目的是给机器听的(ASR),可不可以直接在多维的MFCC、FBANK特征域里做自适应滤波处理,直接得到近端信号的MFCC或者FBANK特征?