YARN的入门介绍
YARN
目录
1.YARN生产背景
2.YARN概述
3.YARN架构(重点,需复述)
4.YARN执行流程
5.YARN环境搭建
6.提交作业到YARN上执行
本文是慕课网大数据学习笔记与总结
1.YARN生产背景
MapReduce1.x存在的问题:
1.单点故障&节点压力大不易扩展&不支持mapreduce以外的计算框架(spark,storm)
在MapReduce1.x下的架构:MapReduce:Master/Slave架构,1个JobTracker带多个 TaskTracker
JobTracker:负责资源管理和作业调度
TaskTracker:定期向JT汇报本节点的健康状况、资源使用情况、作业执行情况
接收来自JT的命令:启动任务/杀死任务
单点故障:整个集群中只有一个JobTracker如果JT挂掉了全部TT都完蛋了
2.资源利用率&运维成本
由于在MapReduce1.x的架构加只能跑MapReduce,所以想要用其他的计算框架就必须在搭建支持其他计算框架的集群,
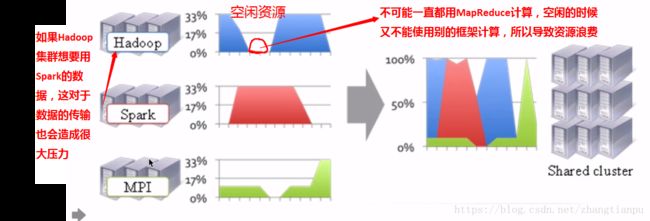
所以由上面的图产生了共享集群的意愿,同时催生了YARN:不同的计算框架可以共享同一个HDFS集群上的数据,

2.YARN概述
3.YARN架构(重点,需复述)
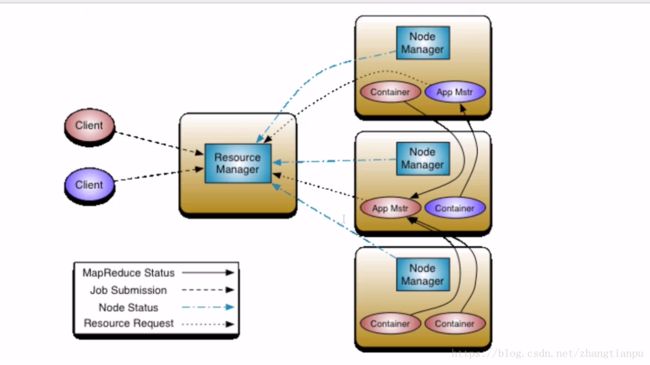
1.REsourceManager:RM
整个集群同一时间提供服务的RM只有一个,负责集群资源的统一管理和调度
处理客户端的请求:提交一个作业、杀死一个作业
监控我们的NM,一旦某个NM挂了,那么该NM上运行的任务需要告诉我们的AM来如何处理
2.NodeManager:NM
整个集群中有多个,负责自己本身节点资源管理和使用
定时向RM汇报本节点的资源使用情况
接受并处理来自RM的各种命令:启动Container
处理来自AM的命令
单个节点的资源管理是由它自己管理,通过心跳机制告诉RM
3.ApplicationMaster:AM
每个应用程序对应一个:MR、Spark,负责应用程序的管理
为应用程序向RM申请资源(core、memory),分配给内部task
需要与NM进行通信:启动/停止task的运行,task试运行在container里面,AM也是运行在Container里面
4.Container
封装了CPU、Memory等资源的一个容器
是一个任务运行环境的抽象
5.Client
提交作业
查询作业的运行进度
杀死作业
4.YARN执行流程

5.YARN环境搭建
1.使用版本:hadoop-2.6.0-cdh5.7.0
2.修改配置文件
cd /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
vim yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
修改mapred-site.xml
cd /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
#如果没有mapred-site.xml需要拷贝一份 mapred-site.xml.template
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
mapreduce.framework.name
yarn
3.启动ResourceManager和NodeManager进程
cd /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/sbin
./start-yarn.sh 4.验证
jps
应当出现:ResourceManager和NodeManager
浏览器:http://hadoop000:8088
5.停止YARN相关的进程
cd /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/sbin
./stop-yarn.sh
6.提交作业到YARN上执行
#1 进入到该目录下:
cd /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce
#2 通过命令提交mapReduce作业到YARN上运行:
hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar pi 2 3