(强化学习)DQN实战CartPole游戏
本文介绍强化学习中的一个经典算法——DQN(deep Q network),它于2013年在论文《Playing Atari with Deep Reinforcement Learning》中首次出现,2015年,一篇发表在Nature的论文《Human-level control through deep reinforcement learning》又一次向人们证实了它在游戏中超出人类的表现,下面是对它的简单介绍和代码实现。
算法
DQN是一种Value-Based的方法,即根据动作产生的价值来决定选择哪个动作。它是将深度神经网络和Q-learing相结合,克服Q-learing在面对状态空间很大时效率变得很低得问题,DQN其实是用一种近似的方式来求Q函数,即用神经网络来近似。
其算法如下图:

DQN与Q-learning的一个区别是采用了经验回放(Experience Replay),即从过去的经验中学习,就像人从记忆中学习那样。由于强化学习是序列决策问题,序列数据前一个状态直接影响后一个状态,因此其数据集并不服从独立同分布的特性,为解决这个问题。采用了经验回放的方法:引入经验池(replay-buffer),在游戏过程中,将探索环境得到的数据先存储起来,然后再随机采样,可以降低了这种序列数据之间的相关性,同时,经验回放还使得样本可重用,从而提高学习效率
Agent在每一步采取action的策略为ε-greedy,即每个状态有ε的概率进行探索,采取随机动作,1-ε的概率根据Q值采取最优动作(选取当前状态下获得Q值最大的那个动作)
上图算法中,γ为折扣因子(discount factor),取值在0到1之间,表明了未来的回报相对于当前回报的重要程度,γ取0时,相当于只考虑立即回报不考虑长期回报,γ为1时,将长期回报和立即回报看得同等重要。
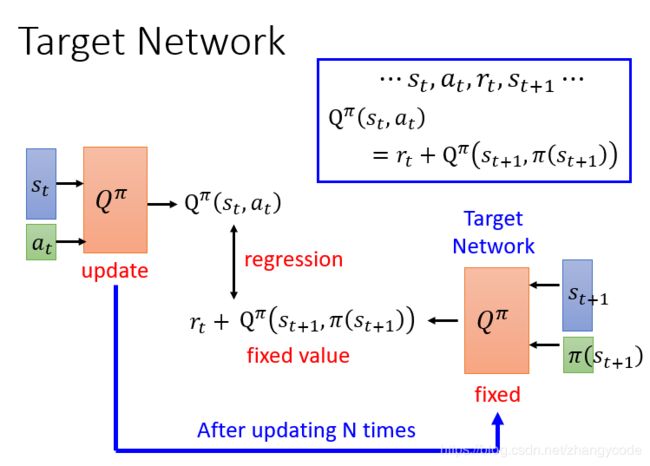
在训练的时候,DQN中有两个结构一样的Q网络,这里一个我们称它为Q,它是用来和环境做互动的网络,并且在互动中产生训练所需的数据,另一个叫Q_target,是我们最后想要学习到的目标网络,两个网络的区别在于参数更新频率不同,Q网络的参数在训练过程中不断在更新,而Q_target网络的参数在固定的时间用Q的参数来更新。其过程为:Q和环境做互动,产生经验数据,存入经验池(Replay-buffer)中,然后从经验池中随机抽样batch个经验,当前时刻的回报和下一状态的Q价值估计(选择所有action中得到的最大的那个Q价值)相加作为了目标价值,即为算法中的y,y类似于监督学习中的标签,通过y值来优化更新Q网络中的参数,每隔一定的步数,将Q中的参数复制到Q_target中,不断的这样循环直到训练结束。
之所以需要两个这样的网络是因为,两个网络可以实现将其中一个网络固定住,即Q_target,使得计算出的标签y是固定的,有利于对Q的优化,让Q去逼近y值;而如果只有一个Q网络,目标Q和评估用的Q是同一个,那么会导致标签的y值变化,导致训练不稳定。
实践
使用DQN玩一个OPENAI的gym中的CartPole游戏。
Cartpole游戏如下图所示,有一个一维方向的底座可以左右滑动,正中心有一个通过铰链链接的直杆,直杆可以左右摆动,agent通过左右移动底座使得杆子能够保持直立而不倒下。
代码如下:
导入gym库,没有安装的需要pip install gym来安装,设置模型超参数如下,可按自己需求更改。
# -*- coding: utf-8 -*-
import tensorflow as tf
import gym
import numpy as np
import random as ran
#设置实验的环境
env = gym.make('CartPole-v0')
#经验池
REPLAY_MEMORY = []
#批次大小
MINIBATCH = 50
#输入,即为某个时刻的环境状态
INPUT = env.observation_space.shape[0]
#输出,这个环境中即为左右两个动作
OUTPUT = env.action_space.n
#优化算法中的学习率
LEARNING_LATE = 0.001
#折扣因子
DISCOUNT = 0.99
#保存模型的路径
model_path= "./save/model.ckpt"
x = tf.placeholder(dtype=tf.float32, shape=(None, INPUT), name='x')
y = tf.placeholder(dtype=tf.float32, shape=(None, OUTPUT), name='y')
设置Q网络,网络为3层全连接神经网络。
# 与环境互动的Q网络
with tf.variable_scope('eval_net'):
W1 = tf.get_variable('W1', shape=[INPUT, 200], initializer=tf.contrib.layers.xavier_initializer())
W2 = tf.get_variable('W2', shape=[200, 200], initializer=tf.contrib.layers.xavier_initializer())
W3 = tf.get_variable('W3', shape=[200, OUTPUT], initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.Variable(tf.zeros([1], dtype=tf.float32))
b2 = tf.Variable(tf.zeros([1], dtype=tf.float32))
L1 = tf.nn.relu(tf.matmul(x, W1) + b1)
L2 = tf.nn.relu(tf.matmul(L1, W2) + b2)
Q_pre = tf.matmul(L2, W3)
# 目标Q网络,与评估用的Q网络结构一致
with tf.variable_scope('target_net'):
W1_r = tf.get_variable('W1_r', shape=[INPUT, 200])
W2_r = tf.get_variable('W2_r', shape=[200, 200])
W3_r = tf.get_variable('W3_r', shape=[200, OUTPUT])
b1_r = tf.Variable(tf.zeros([1], dtype=tf.float32))
b2_r = tf.Variable(tf.zeros([1], dtype=tf.float32))
L1_r = tf.nn.relu(tf.matmul(x, W1_r) + b1_r)
L2_r = tf.nn.relu(tf.matmul(L1_r, W2_r) + b2_r)
Q_pre_r = tf.matmul(L2_r, W3_r)
学习的过程,也是DQN算法的过程。
训练神经网络的参数直到最近200次的平均reward大于195停止循环,此时认为训练的agent已经在游戏上具备了较高的水平,因为每执行一个动作(向左或者向右移动小车或者保持不变)只要直杆没有倒下,将得到大小为1的reward,平均reward大于195说明训练的agent在此游戏上已经有了很高的水平。
在每次episode中收集经验并存入经验池,每个episode训练到小车的直杆倒下(倒下为终止状态)为止,如果小车的杆子一直没有倒下则训练到一个episode中允许的最大步数为止。
每隔10个episode按照实验原理给出的算法流程,从经验池中采样数据来计算y,并用y来训练更新深度Q网络的参数,并且每隔10个episode用深度Q网络目前的参数更新目标Q网络的参数。
训练完成后保存模型
recent_rlist = [0]
episode = 0
#损失函数和优化函数
cost = tf.reduce_sum(tf.square(y - Q_pre))
optimizer = tf.train.AdamOptimizer(LEARNING_LATE, epsilon=0.01)
train = optimizer.minimize(cost)
#更新目标Q网络的参数
t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='target_net')
e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='eval_net')
replace_target_para = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
#学习过程
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
sess.run(replace_target_para)
while np.mean(recent_rlist) < 195:
episode += 1
#每个episode都要将环境恢复初始状态
s = env.reset()
#超过200 episode时,用最新的reward更新列表
if len(recent_rlist) > 200:
del recent_rlist[0]
# e-greedy
e = 1. / ((episode / 25) + 1)
rall = 0 # reward_all
d = False #杆子是否倒下,即回合结束
count = 0 #一个episode里训练的步数
while not d and count < env.spec.max_episode_steps:
# env.render()
count += 1
# 环境状态塑形为一行,
s = np.reshape(s, [1, INPUT])
Q = sess.run(Q_pre, feed_dict={x: s})
if e > np.random.rand(1):
a = env.action_space.sample()
else:
a = np.argmax(Q)
s1, r, d, _ = env.step(a)
#填充经验池
REPLAY_MEMORY.append([s, a, r, s1, d])
#经验池数量超过50000则更新
if len(REPLAY_MEMORY) > 50000:
del REPLAY_MEMORY[0]
rall += r
s = s1
#每10个episode更新目标Q函数的参数
if episode % 10 == 1 and len(REPLAY_MEMORY) > 50:
for sample in ran.sample(REPLAY_MEMORY, MINIBATCH):
s_r, a_r, r_r, s1_r, d_r = sample
Q = sess.run(Q_pre, feed_dict={x: s_r})
if d_r:
Q[0, a_r] = r_r
else:
s1_r = np.reshape(s1_r, [1, INPUT])
Q1 = sess.run(Q_pre_r, feed_dict={x: s1_r})
Q[0, a_r] = r_r + DISCOUNT * np.max(Q1)
_, loss = sess.run([train, cost], feed_dict={x: s_r, y: Q})
sess.run(replace_target_para)
print('loss:{} '.format(loss))
recent_rlist.append(rall)
print("Episode%d: reward:%.2f recent reward:%.4f" %(episode, rall,np.mean(recent_rlist)))
#保存模型
saver = tf.train.Saver()
save_path = saver.save(sess, model_path)
print("Model saved in file: ", save_path)
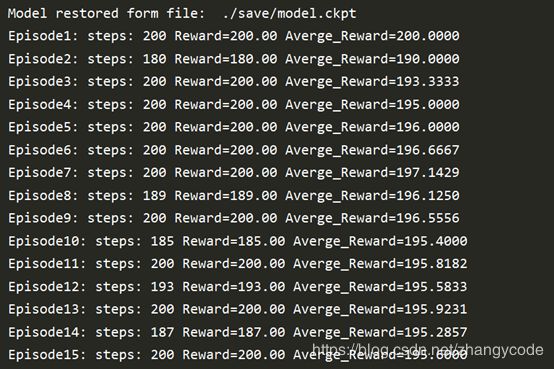
训练好了之后,对训练好的模型进行测试,这里让agent玩100个episode,从刚才保存参数的地址恢复神经网络的参数,运行Q网络,并输出Q网络获得的reward值。
rlist = []
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state('./save/') #检查是否有预训练的模型
if ckpt:
#恢复模型
sess.run(tf.global_variables_initializer())
saver = tf.train.import_meta_graph('./save/model.ckpt.meta')
saver.restore(sess, './save/model.ckpt')
graph = tf.get_default_graph()
x = graph.get_tensor_by_name('x:0')
print("Model restored form file: ", model_path)
for episode in range(100):
s = env.reset()
rall = 0
d = False
count = 0
while not d:
env.render()
count += 1
s_t = np.reshape(s, [1, INPUT])
Q = sess.run(Q_pre, feed_dict={x: s_t})
a = np.argmax(Q)
s, r, d, _ = env.step(a)
rall += r
rlist.append(rall)
print("Episode%d: steps: %d Reward=%.2f Averge_Reward=%.4f"%(episode+1, count, rall,
np.mean(rlist)))
else:
print('No checkpoint file found.')
可以看到结果基本达到得分的预期。