python解析真实网页
第一章:上次课回顾
第二章:解析真实世界中的网页
- 2.1 开始编程解析Trippadvisor
- 2.2 模仿用户登录
第一章:上次课回顾
https://blog.csdn.net/zhikanjiani/article/details/100148698
第二章:解析真实世界中的网页
技术:Requests库 + BeautifulSoup库 来爬取Trippadvisor
第1步:服务器与本地的交换控制
- 常识:平常我们在浏览网页的时候,都是向服务器发送一个Request请求,服务器接到请求后返回给我们一个Response,这被称作为HTTP协议。
Request:
- 在HTTP1.0中只有三种方法:get、 post、 head
- 在HTTP1.1中,又增加了几种方法:put、 options、 connect、 trace、 delete
get、post是最简单的两种方法。
- GET /page_one.html HTTP/1.1 Host: www.sample.com
比如我们使用电脑和手机去获取网页返回的样子是不一样的,这是一个简单的request中包含的信息。
Response:
是网站回应给我们的信息,我们之前爬取的本地网页;正常是我们向服务器发送请求,服务器以response的方式发送给我们。
更加清晰的认识Request和Response:
- 任意进入一个网址,右键检查 --> 刷新当前界面 --> 点击network --> 点击第一个网页信息 --> 点击Headers就能查看到Request和Response的信息。
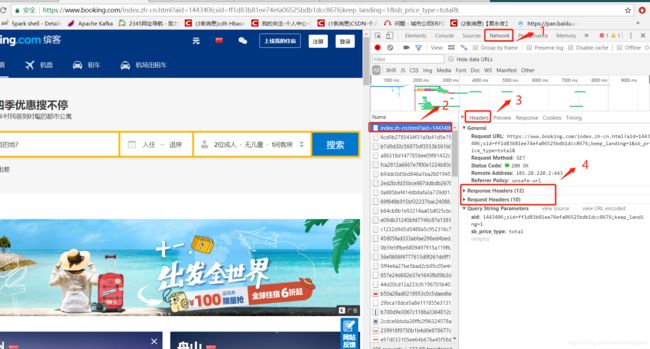
Request中包含以下信息:Cookie、Host、Refer、User-Agent
Response中包含信息:代理信息nginx
第2步:解析真实网页获取数据的一些办法
2.1 开始编程解析Trippadvisor
此时打印出来的只有一家酒店信息,真实网页中的CSS selector的元素比较复杂。
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
# 导入所需要的库
import requests
# 使用requests进行一次网页请求,把返回的response信息放在wb_data
url = 'https://www.tripadvisor.cn/Hotels-g297442-Suzhou_Jiangsu-Hotels.html'
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
# print(soup)
title = soup.select('#property_1773649')
print(title)
输出:
[苏哥利酒店]
第一次修改:
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
# 导入所需要的库
import requests
# 使用requests进行一次网页请求,把返回的response信息放在wb_data
url = 'https://www.tripadvisor.cn/Attractions-g60763-Activities-New_York_City_New_York.html#ATTRACTION_SORT_WRAPPER'
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
# print(soup)
# 标题:根据规则发现
titles = soup.select('div > div > div > div > div.listing_info > div.listing_title > a')
# 图片的规则是宽度为180的打印出来
images = soup.select('img[width="180"]')
# 获取它的分类
cates = soup.select('#taplc_attraction_coverpage_attraction_0 > div > div:nth-child(1) > div > div > div.shelf_item_container > div > div.poi > div > div:nth-child(4)')
# print(titles,images,cates,sep='\n')
# 把获取到的内容放进一个字典中方便做查询
for title, image, cate in zip(titles,images,cates):
data = {
'title':title.get_text(),
'image':image.get('src'),
'cate':list(cate.stripped_strings)
}
print(data)
# 运行代码后发现如下问题:图片链接都是相同的,此处网站设置了反爬机制
问题:点击进入更多界面后,发现图片都是懒加载的,那怎么获取到这个链接呢,待解决…
- 直接检查网页源代码:可以看到图片是有一个地址的,在网页源码中去搜索图片地址,我们可以看到它是lazyload的,实际上爬取图片地址有点复杂的;
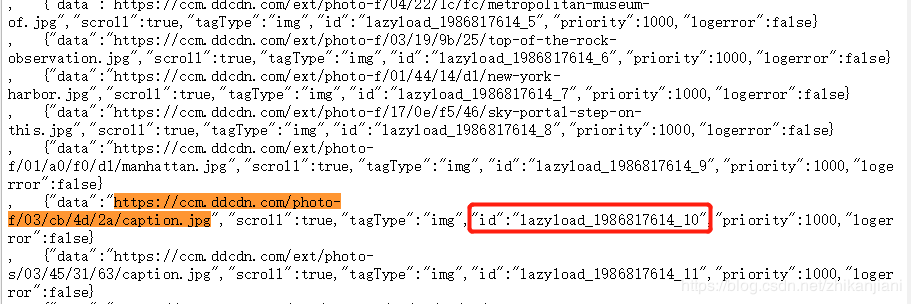
- 我们发现lazyload和图片链接地址是一一对应的,在js代码中找到真实链接去解析出来,可以通过正则表达式来匹配找到真实地址,因为获取时的id会发生变化,接下来会补充。

2.2 模仿用户登录
需求:进入到猫途鹰官网中后,把一些地点加入我的喜欢,前提是我们需要登陆;然后进行爬取加入到喜欢中的那些信息。
-
我们注册登录之后,对这个页面收藏;有一种方法可以让我们跳过登录环节,比如使用request的方式添加一些参数。
-
还是右键检查,添加cookie信息来表向服务器表示我们已经登录。
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
# 导入所需要的库
import requests
'''
# 使用requests进行一次网页请求,把返回的response信息放在wb_data
url = 'https://www.tripadvisor.cn/Attractions-g60763-Activities-New_York_City_New_York.html#ATTRACTION_SORT_WRAPPER'
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
# print(soup)
# 标题:根据规则发现
titles = soup.select('div > div > div > div > div.listing_info > div.listing_title > a')
# 图片的规则是宽度为180的打印出来
images = soup.select('img[width="180"]')
# 获取它的分类
cates = soup.select('#taplc_attraction_coverpage_attraction_0 > div > div:nth-child(1) > div > div > div.shelf_item_container > div > div.poi > div > div:nth-child(4)')
# print(titles,images,cates,sep='\n')
# 把获取到的内容放进一个字典中方便做查询
for title, image, cate in zip(titles,images,cates):
data = {
'title':title.get_text(),
'image':image.get('src'),
'cate':list(cate.stripped_strings)
}
print(data)
# 运行代码后发现如下问题:图片链接都是相同的,此处网站设置了反爬机制
'''
headers = {
'user_agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
'Cookie': 'ServerPool=X; TAUnique=%1%enc%3A2Zo7PUJFZJV8ERLZcdI%2FWN7QH4IUQBAki1AmAGDdrvM%3D; TASSK=enc%3AADPPdtG6ZnA9qwyDt7c7x6VVzuw8MDv06pP1bNqaQhTxxqgEq5lbifzx%2BTHb9XYPKm3XeKPefhlQ8lpHdx703ONylC2elZ84XU16GQs5JeVg02srpvEaM3a0008gNFAF9Q%3D%3D; VRMCID=%1%V1*id.11879*llp.%2F-m11879-a_supai%5C.986220653-a_supap%5C.1cl2-a_supbc%5C.0-a_supbl%5C.%257BlocalInfo%257D-a_supbt%5C.-a_supci%5C.20350801-a_supkw%5C.541753154-a_suppm%5C.-a_supsc%5C.1*e.1567861924273; _gcl_au=1.1.1257335162.1567257126; _ga=GA1.2.1426689833.1567257126; _gid=GA1.2.848668119.1567257126; TART=%1%enc%3AM9viLRD8DtIk0so%2BNlYcmwVwU8JGltVavhVzlNr%2B16bB8paBDrga7zeiH%2Fahgxj89dQTmgAI0Nc%3D; __gads=ID=ddebbff84c3d2b5c:T=1567257146:S=ALNI_MbOxpuU5Jl0RbRCq9EuAjA3-xKQ5g; CM=%1%PremiumMobSess%2C%2C-1%7Ct4b-pc%2C%2C-1%7CRestAds%2FRPers%2C%2C-1%7CRCPers%2C%2C-1%7CWShadeSeen%2C%2C-1%7CTheForkMCCPers%2C%2C-1%7CHomeASess%2C3%2C-1%7CPremiumSURPers%2C%2C-1%7CPremiumMCSess%2C%2C-1%7CUVOwnersSess%2C%2C-1%7CRestPremRSess%2C%2C-1%7CCCSess%2C%2C-1%7CCYLSess%2C%2C-1%7CPremRetPers%2C%2C-1%7CViatorMCPers%2C%2C-1%7Csesssticker%2C%2C-1%7CPremiumORSess%2C%2C-1%7Ct4b-sc%2C%2C-1%7CRestAdsPers%2C%2C-1%7CMC_IB_UPSELL_IB_LOGOS2%2C%2C-1%7Cb2bmcpers%2C%2C-1%7CRestWiFiPers%2C%2C-1%7CPremMCBtmSess%2C%2C-1%7CPremiumSURSess%2C%2C-1%7CMC_IB_UPSELL_IB_LOGOS%2C%2C-1%7CLaFourchette+Banners%2C%2C-1%7Csess_rev%2C%2C-1%7Csessamex%2C%2C-1%7CPremiumRRSess%2C%2C-1%7CTADORSess%2C%2C-1%7CAdsRetPers%2C%2C-1%7CTARSWBPers%2C%2C-1%7CSPMCSess%2C%2C-1%7CTheForkORSess%2C%2C-1%7CTheForkRRSess%2C%2C-1%7Cpers_rev%2C%2C-1%7CRestWiFiREXPers%2C%2C-1%7CSPMCWBPers%2C%2C-1%7CRBAPers%2C%2C-1%7CRestAds%2FRSess%2C%2C-1%7CHomeAPers%2C%2C-1%7CPremiumMobPers%2C%2C-1%7CRCSess%2C%2C-1%7CWiFiORSess%2C%2C-1%7CLaFourchette+MC+Banners%2C%2C-1%7CRestAdsCCSess%2C%2C-1%7CRestPremRPers%2C%2C-1%7CUVOwnersPers%2C%2C-1%7Csh%2C%2C-1%7Cpssamex%2C%2C-1%7CTheForkMCCSess%2C%2C-1%7CCYLPers%2C%2C-1%7CCCPers%2C%2C-1%7Cb2bmcsess%2C%2C-1%7CRestWiFiSess%2C%2C-1%7CRestWiFiREXSess%2C%2C-1%7CSPMCPers%2C%2C-1%7CPremRetSess%2C%2C-1%7CViatorMCSess%2C%2C-1%7CPremiumMCPers%2C%2C-1%7CAdsRetSess%2C%2C-1%7CPremiumRRPers%2C%2C-1%7CRestAdsCCPers%2C%2C-1%7CTADORPers%2C%2C-1%7CTheForkORPers%2C%2C-1%7CWiFiORPers%2C%2C-1%7CPremMCBtmPers%2C%2C-1%7CTheForkRRPers%2C%2C-1%7CTARSWBSess%2C%2C-1%7CPremiumORPers%2C%2C-1%7CRestAdsSess%2C%2C-1%7CRBASess%2C%2C-1%7CSPORPers%2C%2C-1%7Cperssticker%2C%2C-1%7CSPMCWBSess%2C%2C-1%7C; TATravelInfo=V2*AY.2019*AM.9*AD.8*DY.2019*DM.9*DD.9*A.2*MG.-1*HP.2*FL.3*DSM.1567259311363*RS.1; BEPIN=%1%16ce7ef6e67%3Bweb08c.daodao.com%3A10023%3B; TAAuth3=3%3A7fed4b760d6c1d47d0ab18e1e4c3a3b2%3AAKoZ7chM1eewKKTvLk4mI18tB4rHoxpNxqchQpElxXmuKsWnWVWFbgutYDT7WK8%2F5%2BGHHiCZetcDsly3Ohy0%2BxknUTjc0HRvSzySfaGFjW5iTkNVAy7PMkqceHmtYhJoYpaEWsS9YM16H%2Fnah%2B8yRMgfaJI1LxVxFFSLy3YRV%2F2a6bH8NJRc%2Bv4hGxSrG62Nhg%3D%3D; TAReturnTo=%1%%2FProfile%2FSightseer22091698247; roybatty=TNI1625!AHQRCPsXSxX5gOijycnpg10vY4BhwNABjR38nWXiLRvSsAy7PqBDuauAwhJNvhHR2RaDd1w9ghGqu18ElwtAVbY4enSO318lQBHMgF0fy3BhPCes4LJHNGDrh8lKR%2BppDjarTNNU9WSZs3LfW8o3H7ZRZp4E9zydybN3pZWJHl0Z%2C1; TASession=%1%V2ID.F0FAEAC7C79C367686814CBCA65EBF3D*SQ.131*MC.11879*LR.https%3A%2F%2Fwww%5C.baidu%5C.com%2Fbaidu%5C.php%3Fsc%5C.060000ae5skSL9u_FEQhzeCjpwFROdcwMfpWTjcKO3HOExx_tO5eWBUFbEra3uzJsY80KZDhqFeXelLElbIh7DXS3fNorbQsik_61kWFuW4L4CPMWGa8xW46ci4RciTEPQdMaJE2a1vgOHkIICmw9KpNxo65hEyeEwMsBDs-c1fJXd6nyCuiH-72Ob5MuCl71IQOP9GqQyorHoFhbf%5C.DY_a9nOA1I*LP.%2F%3Fm%3D11879%26supci%3D20350801%26supsc%3D1%26supai%3D986220653%26suppm%3D%26supap%3D1cl2%26supbl%3D%257BlocalInfo%257D%26supbt%3D%26supbc%3D0%26supkw%3D541753154*LS.DemandLoadAjax*PD1.1*GR.56*TCPAR.17*TBR.87*EXEX.77*ABTR.99*PHTB.60*FS.20*CPU.59*HS.recommended*ES.popularity*DS.5*SAS.popularity*FPS.oldFirst*TS.F0D42E55C8BA40499ADDA05EC97B5EF0*LF.zhCN*FA.1*DF.0*FLO.60763*TRA.false*LD.102741; TAUD=LA-1567257124222-1*RDD-1-2019_08_31*HC-2176335*HDD-2199779-2019_09_08.2019_09_09.1*LD-53219470-2019.9.8.2019.9.9*LG-53219472-2.1.F.'
}
url_saves = 'https://www.tripadvisor.cn/Trips/1748237'
wb_data = requests.get(url_saves,headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
titles = soup.select('#component_1 > div > div > div > div > div > div > div > div > div.trips-trip-view-page-TripSections-common-CardBody__padded_body--2GGZl > div.trips-trip-view-page-TripSections-common-CardHeader-BaseRow__title_line--ysGYQ > a > div')
images = soup.select('#component_1 > div > div > div > div > div > div > div > div > div.trips-trip-view-page-TripSections-common-CardPhoto__card_photo--3M8H7 > a > div')
metas = soup.select('#component_1 > div > div > div > div > div > div > div > div > div.trips-trip-view-page-TripSections-common-CardBody__padded_body--2GGZl > a > div.trips-trip-view-page-TripSections-common-ParentName__location_name--3NE7t')
# 进行统一的结构
for title,image,meta in zip(titles,images,metas):
data = {
'title': title.get_text(),
'image':image.get('url'),
'meta':list(meta.stripped_strings)
}
print(data)
输出如下:
{'title': '布鲁克林大桥', 'image': None, 'meta': ['纽约州纽约市']}
{'title': '中央公园', 'image': None, 'meta': ['纽约州纽约市']}
{'title': '曼哈顿天际线', 'image': None, 'meta': ['纽约州纽约市']}
此时遇到的问题:使用copy CSS selector时获取不到image的位置。
问题待解决?

越是复杂的网页样式就越多,需要多次尝试,有些网站的样式和结构还会定期做变动。
2.3 爬取浏览列表中的30页信息
思路:把之前的获取列表的两个方法定义成函数,直接调用即可;获取信息列表改成每四秒获取一次;发现url的规律是oa(30,60,90)这样刷的
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
# 导入所需要的库
import requests
import time
url_saves = 'https://www.tripadvisor.cn/Trips/1748237'
url = 'https://www.tripadvisor.cn/Attractions-g60763-Activities-New_York_City_New_York.html#ATTRACTION_SORT_WRAPPER'
urls = ['https://www.tripadvisor.cn/Attractions-g60763-Activities-oa{i}-New_York_City_New_York.html#FILTERED_LIST'.format(str(i)) for i in range(30,930,30)]
headers = {
'user_agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
'Cookie': 'ServerPool=X; TAUnique=%1%enc%3A2Zo7PUJFZJV8ERLZcdI%2FWN7QH4IUQBAki1AmAGDdrvM%3D; TASSK=enc%3AADPPdtG6ZnA9qwyDt7c7x6VVzuw8MDv06pP1bNqaQhTxxqgEq5lbifzx%2BTHb9XYPKm3XeKPefhlQ8lpHdx703ONylC2elZ84XU16GQs5JeVg02srpvEaM3a0008gNFAF9Q%3D%3D; VRMCID=%1%V1*id.11879*llp.%2F-m11879-a_supai%5C.986220653-a_supap%5C.1cl2-a_supbc%5C.0-a_supbl%5C.%257BlocalInfo%257D-a_supbt%5C.-a_supci%5C.20350801-a_supkw%5C.541753154-a_suppm%5C.-a_supsc%5C.1*e.1567861924273; _gcl_au=1.1.1257335162.1567257126; _ga=GA1.2.1426689833.1567257126; _gid=GA1.2.848668119.1567257126; TART=%1%enc%3AM9viLRD8DtIk0so%2BNlYcmwVwU8JGltVavhVzlNr%2B16bB8paBDrga7zeiH%2Fahgxj89dQTmgAI0Nc%3D; __gads=ID=ddebbff84c3d2b5c:T=1567257146:S=ALNI_MbOxpuU5Jl0RbRCq9EuAjA3-xKQ5g; CM=%1%PremiumMobSess%2C%2C-1%7Ct4b-pc%2C%2C-1%7CRestAds%2FRPers%2C%2C-1%7CRCPers%2C%2C-1%7CWShadeSeen%2C%2C-1%7CTheForkMCCPers%2C%2C-1%7CHomeASess%2C3%2C-1%7CPremiumSURPers%2C%2C-1%7CPremiumMCSess%2C%2C-1%7CUVOwnersSess%2C%2C-1%7CRestPremRSess%2C%2C-1%7CCCSess%2C%2C-1%7CCYLSess%2C%2C-1%7CPremRetPers%2C%2C-1%7CViatorMCPers%2C%2C-1%7Csesssticker%2C%2C-1%7CPremiumORSess%2C%2C-1%7Ct4b-sc%2C%2C-1%7CRestAdsPers%2C%2C-1%7CMC_IB_UPSELL_IB_LOGOS2%2C%2C-1%7Cb2bmcpers%2C%2C-1%7CRestWiFiPers%2C%2C-1%7CPremMCBtmSess%2C%2C-1%7CPremiumSURSess%2C%2C-1%7CMC_IB_UPSELL_IB_LOGOS%2C%2C-1%7CLaFourchette+Banners%2C%2C-1%7Csess_rev%2C%2C-1%7Csessamex%2C%2C-1%7CPremiumRRSess%2C%2C-1%7CTADORSess%2C%2C-1%7CAdsRetPers%2C%2C-1%7CTARSWBPers%2C%2C-1%7CSPMCSess%2C%2C-1%7CTheForkORSess%2C%2C-1%7CTheForkRRSess%2C%2C-1%7Cpers_rev%2C%2C-1%7CRestWiFiREXPers%2C%2C-1%7CSPMCWBPers%2C%2C-1%7CRBAPers%2C%2C-1%7CRestAds%2FRSess%2C%2C-1%7CHomeAPers%2C%2C-1%7CPremiumMobPers%2C%2C-1%7CRCSess%2C%2C-1%7CWiFiORSess%2C%2C-1%7CLaFourchette+MC+Banners%2C%2C-1%7CRestAdsCCSess%2C%2C-1%7CRestPremRPers%2C%2C-1%7CUVOwnersPers%2C%2C-1%7Csh%2C%2C-1%7Cpssamex%2C%2C-1%7CTheForkMCCSess%2C%2C-1%7CCYLPers%2C%2C-1%7CCCPers%2C%2C-1%7Cb2bmcsess%2C%2C-1%7CRestWiFiSess%2C%2C-1%7CRestWiFiREXSess%2C%2C-1%7CSPMCPers%2C%2C-1%7CPremRetSess%2C%2C-1%7CViatorMCSess%2C%2C-1%7CPremiumMCPers%2C%2C-1%7CAdsRetSess%2C%2C-1%7CPremiumRRPers%2C%2C-1%7CRestAdsCCPers%2C%2C-1%7CTADORPers%2C%2C-1%7CTheForkORPers%2C%2C-1%7CWiFiORPers%2C%2C-1%7CPremMCBtmPers%2C%2C-1%7CTheForkRRPers%2C%2C-1%7CTARSWBSess%2C%2C-1%7CPremiumORPers%2C%2C-1%7CRestAdsSess%2C%2C-1%7CRBASess%2C%2C-1%7CSPORPers%2C%2C-1%7Cperssticker%2C%2C-1%7CSPMCWBSess%2C%2C-1%7C; TATravelInfo=V2*AY.2019*AM.9*AD.8*DY.2019*DM.9*DD.9*A.2*MG.-1*HP.2*FL.3*DSM.1567259311363*RS.1; BEPIN=%1%16ce7ef6e67%3Bweb08c.daodao.com%3A10023%3B; TAAuth3=3%3A7fed4b760d6c1d47d0ab18e1e4c3a3b2%3AAKoZ7chM1eewKKTvLk4mI18tB4rHoxpNxqchQpElxXmuKsWnWVWFbgutYDT7WK8%2F5%2BGHHiCZetcDsly3Ohy0%2BxknUTjc0HRvSzySfaGFjW5iTkNVAy7PMkqceHmtYhJoYpaEWsS9YM16H%2Fnah%2B8yRMgfaJI1LxVxFFSLy3YRV%2F2a6bH8NJRc%2Bv4hGxSrG62Nhg%3D%3D; TAReturnTo=%1%%2FProfile%2FSightseer22091698247; roybatty=TNI1625!AHQRCPsXSxX5gOijycnpg10vY4BhwNABjR38nWXiLRvSsAy7PqBDuauAwhJNvhHR2RaDd1w9ghGqu18ElwtAVbY4enSO318lQBHMgF0fy3BhPCes4LJHNGDrh8lKR%2BppDjarTNNU9WSZs3LfW8o3H7ZRZp4E9zydybN3pZWJHl0Z%2C1; TASession=%1%V2ID.F0FAEAC7C79C367686814CBCA65EBF3D*SQ.131*MC.11879*LR.https%3A%2F%2Fwww%5C.baidu%5C.com%2Fbaidu%5C.php%3Fsc%5C.060000ae5skSL9u_FEQhzeCjpwFROdcwMfpWTjcKO3HOExx_tO5eWBUFbEra3uzJsY80KZDhqFeXelLElbIh7DXS3fNorbQsik_61kWFuW4L4CPMWGa8xW46ci4RciTEPQdMaJE2a1vgOHkIICmw9KpNxo65hEyeEwMsBDs-c1fJXd6nyCuiH-72Ob5MuCl71IQOP9GqQyorHoFhbf%5C.DY_a9nOA1I*LP.%2F%3Fm%3D11879%26supci%3D20350801%26supsc%3D1%26supai%3D986220653%26suppm%3D%26supap%3D1cl2%26supbl%3D%257BlocalInfo%257D%26supbt%3D%26supbc%3D0%26supkw%3D541753154*LS.DemandLoadAjax*PD1.1*GR.56*TCPAR.17*TBR.87*EXEX.77*ABTR.99*PHTB.60*FS.20*CPU.59*HS.recommended*ES.popularity*DS.5*SAS.popularity*FPS.oldFirst*TS.F0D42E55C8BA40499ADDA05EC97B5EF0*LF.zhCN*FA.1*DF.0*FLO.60763*TRA.false*LD.102741; TAUD=LA-1567257124222-1*RDD-1-2019_08_31*HC-2176335*HDD-2199779-2019_09_08.2019_09_09.1*LD-53219470-2019.9.8.2019.9.9*LG-53219472-2.1.F.'
}
# 使用requests进行一次网页请求,把返回的response信息放在wb_data
def get_attractions(url,data=None):
wb_data = requests.get(url)
time.sleep(5)
soup = BeautifulSoup(wb_data.text,'lxml')
# 标题:根据规则发现
titles = soup.select('div > div > div > div > div.listing_info > div.listing_title > a')
# 图片的规则是宽度为180的打印出来
images = soup.select('img[width="180"]')
# 获取它的分类
cates = soup.select('#taplc_attraction_coverpage_attraction_0 > div > div:nth-child(1) > div > div > div.shelf_item_container > div > div.poi > div > div:nth-child(4)')
# print(titles,images,cates,sep='\n')
#把获取到的内容放进一个字典中方便做查询
for title, image, cate in zip(titles,images,cates):
data = {
'title':title.get_text(),
'image':image.get('src'),
'cate':list(cate.stripped_strings)
}
print(data)
# 运行代码后发现如下问题:图片链接都是相同的,此处网站设置了反爬机制
def get_favs(url,data=None):
wb_data = requests.get(url_saves,headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
titles = soup.select('#component_1 > div > div > div > div > div > div > div > div > div.trips-trip-view-page-TripSections-common-CardBody__padded_body--2GGZl > div.trips-trip-view-page-TripSections-common-CardHeader-BaseRow__title_line--ysGYQ > a > div')
images = soup.select('#component_1 > div > div > div > div > div > div > div > div > div.trips-trip-view-page-TripSections-common-CardPhoto__card_photo--3M8H7 > a > div')
metas = soup.select('#component_1 > div > div > div > div > div > div > div > div > div.trips-trip-view-page-TripSections-common-CardBody__padded_body--2GGZl > a > div.trips-trip-view-page-TripSections-common-ParentName__location_name--3NE7t')
# 进行统一的结构
for title,image,meta in zip(titles,images,metas):
data = {
'title': title.get_text(),
'image':image.get('url'),
'meta':list(meta.stripped_strings)
}
print(data)
for single_url in urls:
get_attractions(single_url)