ALI-本地生活-数据研发实习一面
记录一下 数据研发实习 技术面一面内容
先自我介绍,然后对着简历让我介绍了自己的做过的一个项目,我在其中的角色;
然后问一些算法原理问题:
1. 看你提到了VGG的网络结构,请描述CNN由哪些元件构成?他们分别有什么作用?
卷积神经网络(CNN)由输入层、卷积层、激活函数、池化层、全连接层组成
- 卷积层
- 激活函数
- 池化层
- 全联接层
2. 你了解的激活函数有哪些?他们分别有什么特点?
-
Sigmoid函数
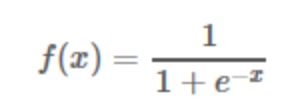
目前已被淘汰
缺点:
∙ 饱和时梯度值非常小。由于BP算法反向传播的时候后层的梯度是以乘性方式传递到前层,因此当层数比较多的时候,传到前层的梯度就会非常小,网络权值得不到有效的更新,即梯度耗散。如果该层的权值初始化使得f(x) 处于饱和状态时,网络基本上权值无法更新。
∙ 输出值不是以0为中心值。
-
Tanh函数
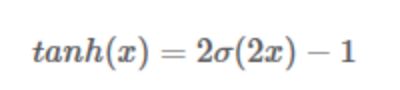
其中σ(x) 为sigmoid函数,仍然具有饱和的问题。
-
ReLU函数
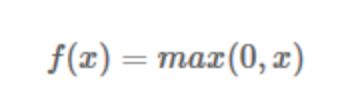
该函数的提出很大程度的解决了BP算法在优化深层神经网络时的梯度耗散问题
优点:
∙ x>0 时,梯度恒为1,无梯度耗散问题,收敛快;
∙ 增大了网络的稀疏性。当x<0 时,该层的输出为0,训练完成后为0的神经元越多,稀疏性越大,提取出来的特征就约具有代表性,泛化能力越强。即得到同样的效果,真正起作用的神经元越少,网络的泛化性能越好
∙ 运算量很小;
缺点:
如果后层的某一个梯度特别大,导致W更新以后变得特别大,导致该层的输入<0,输出为0,这时该层就会‘die’,没有更新。当学习率比较大时可能会有40%的神经元都会在训练开始就‘die’,因此需要对学习率进行一个好的设置。
由优缺点可知max(0,x) 函数为一个双刃剑,既可以形成网络的稀疏性,也可能造成有很多永远处于‘die’的神经元,需要tradeoff。
-
Leaky ReLU函数
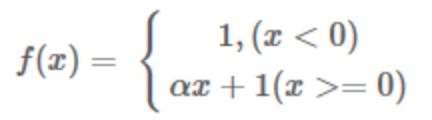
改善了ReLU的死亡特性,但是也同时损失了一部分稀疏性,且增加了一个超参数,目前来说其好处不太明确
-
Maxout函数
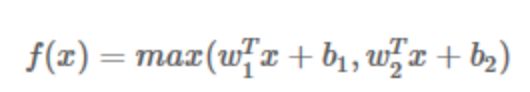
泛化了ReLU和Leaky ReLU,改善了死亡特性,但是同样损失了部分稀疏性,每个非线性函数增加了两倍的参数
真实使用的时候最常用的还是ReLU函数,注意学习率的设置以及死亡节点所占的比例即可
还有一个东西要注意,sigmoid 和 tanh作为激活函数的话,一定要注意一定要对 input 进行归一话,否则激活后的值都会进入平坦区,使隐层的输出全部趋同,但是 ReLU 并不需要输入归一化来防止它们达到饱和。
3. 描述一下贝叶斯概率的形式
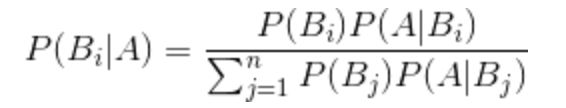
公式中,事件Bi的概率为P(Bi),事件Bi已发生条件下事件A的概率为P(A│Bi),事件A发生条件下事件Bi的概率为P(Bi│A)。
P(A)是A的先验概率或边缘概率。之所以称为"先验"是因为它不考虑任何B方面的因素。
P(A|B)是已知B发生后A的条件概率,也由于得自B的取值而被称作A的后验概率。
P(B|A)是已知A发生后B的条件概率,也由于得自A的取值而被称作B的后验概率。
4. 什么是ROC曲线?混淆矩阵是什么?
ROC曲线:接收者操作特征(receiveroperating characteristic), roc曲线上每个点反映着对同一信号刺激的感受性。
横轴:负正类率(false postive rate FPR)特异度,划分实例中所有负例占所有负例的比例;
纵轴:真正类率(true postive rate TPR)灵敏度,Sensitivity(正类覆盖率)
AUC(Area under Curve):Roc曲线下的面积,介于0.1和1之间。Auc作为数值可以直观的评价分类器的好坏,值越大越好。
首先AUC值是一个概率值,当你随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
5. SVM的两个关键参数是什么?他们分别是什么含义?如何调参?
SVM模型有两个非常重要的参数C与gamma。
其中 C是惩罚系数,即对误差的宽容度。c越高,说明越不能容忍出现误差,容易过拟合。C越小,容易欠拟合。C过大或过小,泛化能力变差
gamma是选择RBF函数作为kernel后,该函数自带的一个参数。隐含地决定了数据映射到新的特征空间后的分布,gamma越大,支持向量越少,gamma值越小,支持向量越多。支持向量的个数影响训练与预测的速度。
6. 你了解xgboost吗?xgboost和gbdt区别是什么?
详见xgboost介绍与实现。
7. 你了解Kmeans吗?他的k值如何确定?了解Kmeans++吗?
- k值的确定:
手肘法
- 核心指标:SSE(sum of the squared errors,误差平方和)
- Kmeans++
原始K-means算法最开始随机选取数据集中K个点作为聚类中心,而K-means++按照如下的思想选取K个聚类中心:
假设已经选取了n个初始聚类中心(0 可以说这也符合我们的直觉:聚类中心当然是互相离得越远越好。这个改进虽然直观简单,但是却非常得有效。 总体来说,面试内容聚焦于基础的算法原理,问的比较细,不关注你的网络的架构。 官网显示一面通过有一周多了,还没有后续,估计是进wait list了。 挺学长说ALI比鹅场难,ALi 坑太少
8. 然后对他们有什么问题