潜在狄利克雷分配(LDA)基础
文章目录
- 狄利克雷分布
- LDA模型
- 基本想法
- 模型定义
- LDA 与 PLSA 异同
潜在狄利克雷分配(latnet Dirichlet allocation, LDA)模型是文本集合的生成概率模型。假设每个文本由话题的一个多项分布表示,每个话题由单词的一个多项分布表示,特别假设文本的话题分布的先验分布是狄利克雷分布,话题的单词分布的先验分布也是狄利克雷分布。
狄利克雷分布
1、多项分布
假设重复进行 n n n次独立随机试验,每次试验可能出现的结果有 k k k种,第 i i i种结果出现的概率为 p i p_i pi,第 i i i种结果出现的次数为 n i n_i ni,随机变量 X = ( X 1 , X 2 , … , X k ) X=(X_1,X_2,\ldots,X_k) X=(X1,X2,…,Xk) 表示试验所有可能的结果的次数, X i X_i Xi表示第 i i i种结果出现的次数。那么随机变量X服从多项分布:
P ( X 1 = n 1 , X 2 = n 2 , … , X k = n k ) = n ! n 1 ! n 2 ! … n k ! p 1 n 1 p 2 n 2 … p k n k P(X_1=n_1,X_2=n_2,\ldots,X_k = n_k) = \frac{n!}{n_1!n_2!\ldots n_k!} p_1^{n_1} p_2^{n_2}\ldots p_k^{n_k} P(X1=n1,X2=n2,…,Xk=nk)=n1!n2!…nk!n!p1n1p2n2…pknk
记作: X ∼ M u l t ( n , p ) X \sim Mult(n,p) X∼Mult(n,p)。
其中: ∑ i = 1 k p i = 1 , ∑ i = 1 k n i = n \sum_{i=1}^k p_i =1, \sum_{i=1}^k n_i =n ∑i=1kpi=1,∑i=1kni=n ,
2、狄利克雷分布
多元连续随机变量 θ = ( θ 1 , θ 2 , … , θ k ) \theta = (\theta_1,\theta_2,\ldots,\theta_k) θ=(θ1,θ2,…,θk)的概率密度为:
P ( θ ∣ α ) = Γ ( ∑ i = 1 K α i ) ∏ i = 1 K Γ ( α i ) ∏ i = 1 K p k α i − 1 P(\theta| \alpha) = \frac{\Gamma(\sum\limits_{i=1}^K\alpha_i)}{\prod_{i=1}^K\Gamma(\alpha_i)}\prod_{i=1}^Kp_k^{\alpha_i-1} P(θ∣α)=∏i=1KΓ(αi)Γ(i=1∑Kαi)i=1∏Kpkαi−1
其中 ∑ i = 1 k θ i = 1 , θ i ≥ 0 , α = ( α 1 , α 2 , … , α k ) , α i ≥ 0 \sum_{i=1}^k \theta_i =1,\theta_i \geq 0, \alpha=(\alpha_1,\alpha_2,\ldots,\alpha_k), \alpha_i \geq 0 ∑i=1kθi=1,θi≥0,α=(α1,α2,…,αk),αi≥0。则称随机变量 θ \theta θ 服从参数为 α \alpha α的狄利克雷分布,记作 θ ∼ D i r ( α ) \theta \sim Dir(\alpha) θ∼Dir(α)。
其中:
Γ ( s ) = ∫ 0 ∞ x s − 1 e − x d x s > 0 \Gamma(s) = \int_{0}^\infty x^{s-1}e^{-x}dx \qquad s>0 Γ(s)=∫0∞xs−1e−xdxs>0
性质:(1)狄利克雷分布属于指数分布族;(2)狄利克雷分布是多项分布的共轭先验。
共轭先验的定义:如果后验 P ( y ∣ x ) P(y|x) P(y∣x)与先验 P ( y ) P(y) P(y)分布属于同类,则先验分布与后验分布称为共轭分布,先验分布称为共轭先验。
李航统计学习方法(第二版)P389页证明了如下结论:
多项分布的先验分布和后验分布都是狄利克雷分布,所以,狄利克雷分布是多项分布的共轭先验;但二者参数不同,狄利克雷后验分布的参数等于狄利克雷先验分布参数 α = ( α 1 , α 2 , … , α k ) \alpha=(\alpha_1,\alpha_2,\ldots,\alpha_k) α=(α1,α2,…,αk) 加上多项分布的观测计数 n = ( n 1 , n 2 , … , n k ) n=(n_1,n_2,\ldots,n_k) n=(n1,n2,…,nk)。
LDA模型
基本想法
LDA文本生成过程如下图所示:
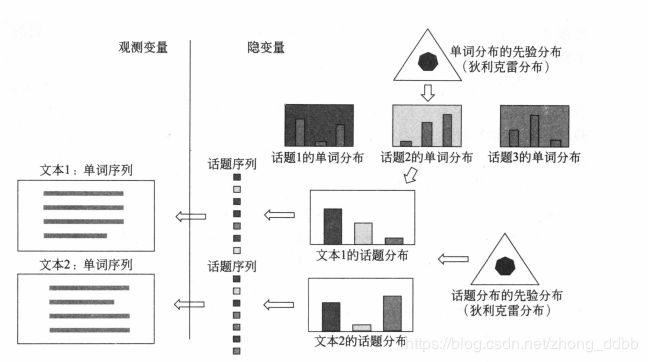
(1)生成每一个话题的单词分布:基于单词分布的先验分布(狄利克雷分布)生成多个单词分布,即决定多个话题内容;
(2)生成每一个文本的话题分布:基于话题分布的先验分布(狄利克雷分布)生成多个话题分布,即决定多个文本内容;
(3)基于每一个话题分布生成话题序列,针对每一个话题,基于话题的单词分布生成单词,整体构成一个单词序列,即生成文本,重复这个过程生成所有文本。
这个过程中,文本的单词序列是观测变量,文本的话题序列,文本的话题分布和话题的单词分布都是隐变量。利用LDA进行话题分析,就是对给定文本集合,学习到每个文本的话题分布,以及每个话题的单词分布。
模型定义
设 V V V个单词集合 W = { w 1 , … , w v , … , w V } W=\{w_1,\ldots,w_v,\ldots,w_V\} W={w1,…,wv,…,wV}, M M M个文本的集合 D = { w 1 , … , w m , … , w M } D=\{\mathbf w_1,\ldots,\mathbf w_m,\ldots, \mathbf w_M \} D={w1,…,wm,…,wM},文本 w m \mathbf w_m wm 的单词(共 N m N_m Nm个单词)序列 w m = ( w m 1 , … , w m n , … , w m N m ) \mathbf w_m = (w_{m1},\ldots,w_{mn},\ldots,w_{mN_m}) wm=(wm1,…,wmn,…,wmNm) , k k k个话题的集合 Z = { z 1 , … , z k , … , z K } Z=\{z_1,\ldots,z_k,\ldots,z_K\} Z={z1,…,zk,…,zK}。
生成过程如下:
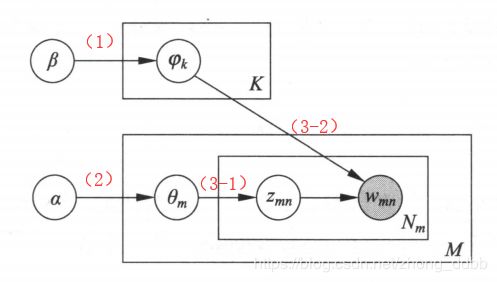
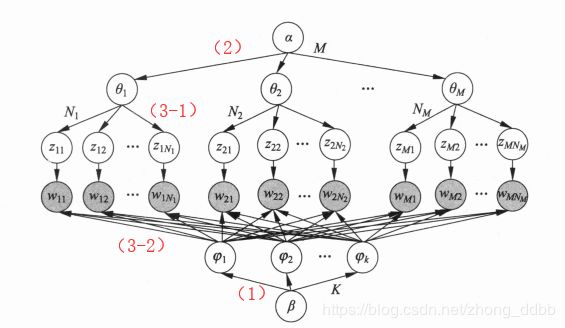
(1)生成话题的单词分布
随机生成K个话题的单词分布:按照狄利克雷分布 D i r ( β ) Dir(\beta) Dir(β) 随机生成一个参数向量 φ k = ( φ k 1 , φ k 2 , … , φ k V ) , φ k ∼ D i r ( β ) \varphi_k = (\varphi_{k1},\varphi_{k2},\ldots,\varphi_{kV}), \varphi_k \sim Dir(\beta) φk=(φk1,φk2,…,φkV),φk∼Dir(β), φ k V \varphi_{kV} φkV表示话题 z k z_k zk 生成单词 w v w_v wv的概率, φ k \varphi_{k} φk作为话题 z k z_k zk的单词分布 P ( w ∣ z k ) P(w|z_k) P(w∣zk)。
(2)生成文本的话题分布
随机生成 M M M个文本的话题分布:按照狄利克雷分布 D i r ( α ) Dir(\alpha) Dir(α) 随机生成一个参数向量 θ m = ( θ m 1 , θ m 2 , … , θ m k ) , θ m ∼ D i r ( α ) \theta_m = (\theta_{m1},\theta_{m2},\ldots,\theta_{mk}), \theta_m \sim Dir(\alpha) θm=(θm1,θm2,…,θmk),θm∼Dir(α), θ m k \theta_{mk} θmk表示文本 w m \mathbf w_m wm 生成话题 z k z_k zk的概率, θ m \theta_m θm作为文本 w m \mathbf w_m wm的话题分布 P ( z ∣ w m ) P(z|\mathbf w_m) P(z∣wm)。
(3)生成文本的单词序列
随机生成 M M M个文本的 N m N_m Nm个单词。文本 w m , ( m = 1 , 2 , . . . , M ) \mathbf w_m,(m= 1,2,... ,M) wm,(m=1,2,...,M) 的单词 w m n ( n = 1 , 2 , . . , N m ) w_{mn} (n=1,2,.. ,Nm) wmn(n=1,2,..,Nm)的生成过程如下:
(3-1)首先按照多项分布 M u l t ( θ m ) Mult(\theta_m) Mult(θm)随机生成-一个话题 z m n z_{mn} zmn, z m n ∼ M u l t ( θ m ) z_{mn} \sim Mult(\theta_m) zmn∼Mult(θm)。
(3-2)然后按照多项分布 M u l t ( φ z m n ) Mult(\varphi_{z_{mn}}) Mult(φzmn)随机生成-一个单词 w m n , w m n ∼ M u l t ( φ z m n ) w_{mn}, w_{mn} \sim Mult(\varphi_{z_{mn}}) wmn,wmn∼Mult(φzmn),文本 w m \mathbf w_m wm本身是单词序列 w m = ( w m 1 , … , w m n , … , w m N m ) \mathbf w_m = (w_{m1},\ldots,w_{mn},\ldots,w_{mN_m}) wm=(wm1,…,wmn,…,wmNm),对应着隐式的话题序列 Z = { z m 1 , z m 2 , … , z m N m } Z=\{z_{m1},z_{m2},\ldots,z_{mN_m}\} Z={zm1,zm2,…,zmNm}。
上述过程对应的概率图模型如下:
展开图模型如下:
注:LDA的文本生成过程中,假定话题个数 K K K给定,实际通常通过实验选定。狄利克雷分布的超参数 a 和 β a和β a和β通常也是事先给定的。在没有其他先验知识的情况下,可以假设向量a和β的所有分量均为1,下图是参数 α \alpha α对狄利克雷分布的影响:

可以看出当 α = 1 \alpha =1 α=1 时,狄利克雷分布退化为均匀分布。
LDA 与 PLSA 异同
同:两者都假设话题是单词的多项分布,文本是话题的多项分布。
异:(1)在文本生成过程中,LDA使用狄利克雷分布作为先验分布,而PLSA不使用先验分布(或者说假设先验分布是均匀分布);使用先验概率分布,可以防止学习过程中产生的过拟合 。
(2)学习过程LDA基于贝叶斯学习,而PLSA基于极大似然估计。