ELK日志分析系统
ELK日志分析系统
介绍:
顾名思义ELK是由Elasticsearch Logstash Kibana三大组件构成的一个基于web页面的日志分析工具。
日志分析是运维工程师解决系统故障,发现问题的主要手段。日志包含多种类型,包括程序日志,系统日志以及安全日志等。通过对日志分析,预发故障的发生,又可以在故障发生时,寻找到蛛丝马迹,快速定位故障点。及时解决。
组件结构:
Elasticsearch:是一个开源分布式时实分析搜索引擎,建立在全文搜索引擎库Apache Lucene基础上,同时隐藏了Apache Lucene的复杂性。Elasticsearch将所有的功能打包成一个独立的动画片,索引副本机制,RESTful风格接口,多数据源。自动搜索等特点。
Logstash :是一个完全开源的工具,主要用于日志收集,同时可以对数据处理,并输出给Elasticarch
Kibana:也是一个完全开源的工具,kibana可以为Logstash和Elasticsearch提供图形化的日志分析。Web界面,可以汇总,分析和搜索重要数据日志。
组件介绍:
Elasticsearch介绍
Elasticsearch:是基于Lucene的搜索服务器,它稳定、可靠、快速,而且具有比较好的水平扩展能力,为分布式环境设计,在云计算应用很广泛。
Elasticsearch的基础核心概念。
接近实时(NRT):Elasticsearch是一个搜索速度接近实时的搜索平台,响应速度非常的快,从索引一个文档直到能够被搜索到只有一个轻微的延迟(通常是1s)
群集(cluster):群集就是由一个或多个节点组织在一起,在所有的节点上存放用户数据,并一起提供索引和搜索功能。通过选举产生节点,并提供跨节点的联合索引和搜索的功能。每个群集都有一个唯一的表示名称,默认是Elasticsearch,每个节点是基于群集名字加入到其群集中的。一个群集可以只有一台节点,为了具备更好的容错性,通常配置多个节点,在配置群集时,建议配置成群集模式。
节点(node):是指一台单一的服务器,多个节点组织为一个群集,每个节点都存储数据并参与群集的索引和搜索功能。和群集一样,节点也是通过名字来标识的。默认情况下,节点名字是随机的,也可以自定义。
索引(index):类似于关系型数据库中的“库”,当索引一个文档后,就可以使用elasticsearch搜索到该文档,也可以简单地将索引理解为存储数据库的地方,可以方便地进行全文索引。
分片和副本(shards&replicas):elasticsearch将索引分成若干个部分,每个部分称为一个分片,每个分片就是一个功能的独立索引。分片的数量一般在索引创建前指定,且创建索引后不能更改。
Logstash介绍:
Logstash由JRuby语言编写,运行在Java虚拟机上,是一款强大的数据库处理工具,可以实施数据传输,格式处理,格式化输出。Logstash具有强大的插件功能,常用于日志处理。Logstash可配置单一的代理端,与其他开源软件结合,以实现不同的功能。
Logstash的理念很简单,它只做三件事:数据输入;数据输出;数据加工(如加工、更改等)。
Logstash的主要组件都有:
Shipper:日志收集者。负责监控本地日志文件的变化,及时收集最新的日志文件内容。
Indexer:日志存储者。负责接收日志并写入到本地文件。
Broker:日志Hub。负责连接多个Shipper和多个Indexer。
Search and Storage:允许对事件进行搜索和存储。
Web Interface:基于Web的展示界面。
注:标红色字体的是用于远程代理端时,需要的组件。
正是由于组件在Logstash架构中可独立部署,才能提供更好的群集扩展性。
在Logstash中包含三个阶段,分别是输入(Input)、处理(Filter非必要)和输出(Output)
Kibana介绍:
Kibana是一个针对Elasticsearch的开源分析及可视化平台,主要设计用来和Elasticsearch一起工作,可以搜索,查看存储在Elasticsearch搜索中的数据,并通过各种表进行高级数据分析及展示。
Kibana可以让数据看起来一目了然。他操作简单,基于浏览器的用户界面管理方式,用户可以在任何地点任何时间都可以实时监控。
Kibana的主要功能:
Elasticsearch无缝之集成,kibana架构是为Elasticsearch定制的,可以将任何(结构化和非结构化)数据加入Elasticsearch索引。
整合数据:Kibana可以让海量数据变得更容易理解,根据数据内容可以创建形象的柱形图,折线图、散点图、直方图等以便用户查看。
复杂数据分析:Kibana提升了Elasticsearch的分析能力,能够更加智能地分析数据,执行数学转换并根据要求对数据切割分块。
接口灵活:使用Kibana可以更加方便地创建、保存、分享数据,并将可视化数据快速交流。
配置简单、可视化多数据源等…
实施案列:
准备环境:
准备三台虚拟机,关闭selinux和防火墙。其中nide1节点和nide2节点内存条需要4G(>2G)以上内存。内存小了怕运行不起节点。
配置主机名并配置host文件以便DNS解析:

![]()

注:node2节点上的配置也和上面一样。
检查本机是否存在Java环境:

注:两台节点上都需要检查。
- 部署Elasticsearch软件。
在node1和node2节点上都需要部署Elasticsearch软件。Elasticsearch软件可以通过rpm安装、YUM安装或源码安装。生产环境中,根据实际需要,选择安装方式。这里我使用的是rpm
![]()
加载系统服务并设置开机自启动:
![]()
![]()
修改配置文件:
![]()

群集发现通过单薄实
![]()
创建数据存放路径并授权:
![]()
![]()
启动服务并检查端口号:
![]()

通过以上的方式产看群集的状态并不友好。可以通过安装Elasticsearch插件,可以更方便的管理群集:
- 安装Elasticsearch-head插件:
Elasticsearch在5.0版本过后,Elasticsearch-head插件需要做独立服务进行安装,需要npm命令。安装Elasticsearch-head需要提前把node和phantomjs软件包安装好。Node是一个基于Chrome V8引擎的JavaScript运行环境,而phantomjs是一个基于webkit的JavaScriptAPI。可以理解为一个隐形的浏览器,任何基于webkit浏览器做的事情,它都可以做到。
编译安装node耗时比较长,一般在50分钟左右。

安装phantomjs:

安装Elasticsearch-head插件:

修改Elasticsearch主配置文件
![]()
启动服务:必须在解压后的Elasticsearch-head目录下启动服务。进程会读取该目录下的gruntfile.js文件,否则可能启动失败

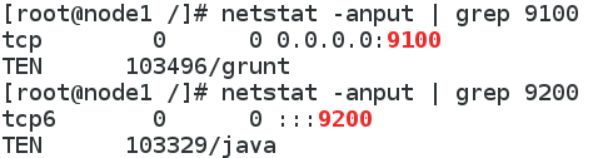
检查端口:
最后打开网页浏览Elasticsearch信息:(健康值为绿色)

安装Logstash:
Logstash一般部署在需要监控其他日志的服务器中,在部署之前,先在node1节点上部署一遍,已熟悉Logstash的使用方法。![]()
启动服务并做优化链接:

Logstash的配置文件:主要由三部分组成:input、output以及filter。根据需要进行配置。配置文件格式为:

下面配置通过修改Logstash配置文件,让收集系统日志/var/log/messages,并将其输出到Elasticsearch中。


安装Kibana:
在node1节点上安装部署。

修改配置Kibana文件:
![]()

重启服务打开浏览器访问:
![]()
