App项目实战之路(六):数据库篇
转载自Keegan小钢
原文链接:http://keeganlee.me/post/practice/20161016
App项目实战之路(一):概述篇
App项目实战之路(二):API篇
App项目实战之路(三):原型篇
App项目实战之路(四):UI篇
App项目实战之路(五):服务端篇
App项目实战之路(六):数据库篇
上一篇文章[服务端篇]提到本项目的数据库采用了关系型的 MySQL,那么,本文将基于 MySQL 聊聊本项目的数据库设计。
设计结果
下图是我为本项目设计的数据库ER图,这只是初步的数据模型,可能还会有遗漏,后续在实现具体细节时可能会有所改动。
我总共只建了10张表,分别如下:
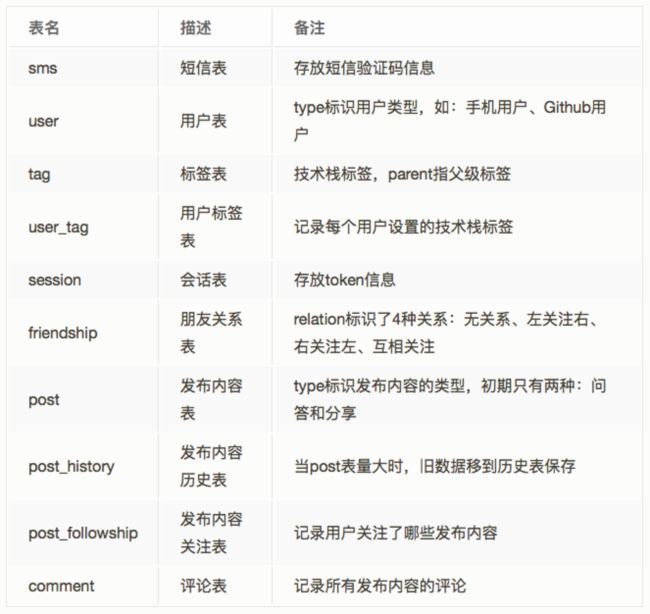
后面,我会挑一些关键的点,再详细阐述我的观点。如果你有不同看法,欢迎提出来一起讨论。
主键
首先,主键应该用业务主键好还是逻辑主键好?我是推崇尽量使用与业务无关的逻辑主键的,因为业务的东西谁也无法保证一定不会变。另外,近几年来,我好像也很少见到使用业务主键的数据库了。还发现关于这方面的讨论也少了。可能是大部分人已经倾向于使用逻辑主键了吧。
其次,逻辑主键的生成策略有很多种,MySQL 的 AUTO_INCREMENT,Oracle 和 PostgreSQL 的 SEQUENCE,MongoDB 的 ObjectId,还有与数据库无关的 UUID。各种生成策略各有利弊。
我目前是使用了MySQL的 AUTO_INCREMENT 自增长策略,优点就是方便简单,而缺点主要有两个:一是数据库移植问题,当需要将 MySQL 数据库移植到 Oracle/PostgreSQL/MongoDB 数据库时,因为这些数据库不支持 AUTO_INCREMENT,改动就会比较麻烦;二是高并发性能问题,因为 AUTO_INCREMENT 在某些情况下会锁表,锁表时其他 INSERT 操作就会被阻塞,当并发量很高时性能就会明显低下了。这里需要再补充下,MySQL 的 InnoDB AUTO_INCREMENT 有三种锁模式,设置参数为 innodb_autoinc_lock_mode,取值可以为0、1、2。
innodb_autoinc_lock_mode = 0(”traditonal“ lock mode)
对任何插入语句都会表锁,直到语句执行结束后才会解锁。
innodb_autoinc_lock_mode = 1(”consecutive“ lock mode)
对“bulk inserts”采用表锁方式,而对“Simple inserts”和“mixed-mode inserts”则采用轻量级的 mutex 方式,只锁定增长量的分配过程,而无需等待语句执行结束。这是默认的锁模式。在此种模式下,对每条“simple insert”语句会预先分配该语句所需的增长量,因此,自增值列的增长还是连续的。
innodb_autoinc_lock_mode = 2(”interleaved“ lock mode)
对任何插入语句都采用 mutex 方式,而不表锁,性能最高。不过,与”consecutive“ lock mode不同的是,并不是对每条语句预先分配该语句所需的增长量,而是所有语句并发插入,因此,自增长值可能不是连续的。也因此,使用 statement-based 的主从复制时就会出现问题。所以,使用此模式,应该用 row-base 的主从复制,才能保证高并发性能和主从复制时的数据一致。
关于 AUTO_INCREMENT 的锁模式需要了解更多的可查看官方文档:http://dev.mysql.com/doc/refman/5.7/en/innodb-auto-increment-handling.html
另外,在分布式环境下,还得调整方案满足全局唯一id的问题。最简单的方案就是设置每个集群的自增id起始点(auto_increment_offset)和自增步长(auto_increment_increment),让每个集群的起始点错开1,而步长选择将来不太可能达到的集群数,比如10000。另一种简单方案就是使用 UUID,但因为 UUID 是字符串,而且128比特太长且无序,既占空间且查询效率也低,所以这种方案一般不建议使用。也可以采用类似于 Oracle 和 PostgreSQL 的 SEQUENCE 序列对象,就是实现起来有点复杂。采用类似 MongoDB 的 ObjectId 方案也是个不错的选择,ObjectID 只有12字节,按顺序分别为:4字节的时间戳 + 3字节的机器ID + 2字节的PID + 3字节的计数器。Twitter 的 Snowflake 也和 MongoDB 的 ObjectID 类似,不过它只有64比特,1比特的保留位 + 41比特的时间戳 + 10比特的机器ID + 12比特的序列号。
TOKEN
我在本项目的设计中,是有两个 token 的,一个 accessToken,一个 refreshToken。为什么要用两个 token 呢?回答这个问题之前,先看看只用一个 token 的使用场景。用户登录后获得 token,token 过期后如何更新呢?要么让用户重新登录,但这明显不是一种好的用户体验方式;要么手机缓存用户密码自动登录,但在客户端保存用户密码明显不是一种安全的解决方案;要么服务端根据用户最后一次请求的时间自动延长 token 有效期,但这也明显不是一种安全的解决方案,如果 token 一旦被拦截,攻击者只要在 token 有效期内不断发起请求就可以一直使用了。所以,只有一个 token 并不能很好地解决 token 更新的问题,这才需要引入两个 token。所有需要用户鉴权的请求都用 accessToken,accessToken 过期后再用 refreshToken 去请求一个新的 accessToken。accessToken 的有效期比较短,我只设了24小时,而 refreshToken 的有效期则比较长,我是设了30天。refreshToken 过期的话,则需要用户重新登录了。
accessToken 和 refreshToken 是在用户登录的时候生成的,用户退出登录时则会删除该条记录。数据表里有两个字段:createTime 和 updateTime,其中,createTime 作为 refreshToken 有效期的起始时间,而 updateTime 则是 accessToken 有效期的起始时间。
至于 token 如何生成,有些人会使用 {userid + 时间戳 + 随机数} 的组合方式生成,其实这种方式反而减低了 token 的安全性。安全性高的 token 应该具备不可预测性,所以最好是一个完全的随机数。所以,使用 UUID 比前面的组合方式更安全。当然,在某些场景下也可以使用 {userid + 时间戳 + 随机数} 的组合方式生成。比如,token 不在服务端直接存储,而只是需要鉴权时才根据规则自动生成。也比如,嫌 UUID 太长,想用短一些的 token,或者想直接在 token 上与 userid 绑定,而不想另外再用一个字段保存 userid 建立绑定关系。不过,安全性始终还是不如直接使用 UUID。
关注关系
我用了三个字段来表示用户之间的关注关系,关注关系是从左到右,即左用户关注右用户:

接下来,再看看如何查询用户的关注关系列表。
查询 A 所关注的人:
SELECT userRight,relation FROM friendship WHERE userLeft = A.id
查询关注 A 的人:
SELECT userLeft,relation FROM friendship WHERE userRight = A.id
查询和 A 相互关注的人,下面两个语句随便哪个都可以:
SELECT userRight FROM friendship WHERE userLeft = A.id AND relation = 2
SELECT userLeft FROM friendship WHERE userRight = A.id AND relation = 2
查询发布内容
为了简单,发布内容我统一放在了 post 表,其中,定义了一个 type 字段用来定义不同类型的发布内容,比如问答和分享。另外,我还预留了一个 post_history 表,以应对后期 post 表的数据量太大之后将旧数据转移到这个历史表。
不过,我们的重点在于查询。在本项目中,初期主要有三类查询:
查询 A 所发布的内容列表,查询语句就很简单了:
SELECT * FROM post WHERE userid = A.id ORDER BY createTime DESC查询 A 所关注的人的内容列表,需要先查出 A 所关注的人,查询语句可以这
SELECT * FROM post WHERE userid IN (SELECT userRight FROM friendship WHERE userLeft = A.id) ORDER BY createTime DESC有技术栈标签 T 的人的内容列表,查询语句则可以这么写:
SELECT * FROM post WHERE userid IN (SELECT userid FROM user_tag WHERE tagID = T.id) ORDER BY createTime DESC然而,实际上,只用上面的查询语句是不可行的。当内容越来越多之后,查询结果会越来越大,所以,必须引入分页查询。分页查询就要用到 LIMIT 子句了。
加入分页查询之后,查询 A 所发布的内容列表的SQL语句就变成了这样:
SELECT * FROM post WHERE userid = A.id AND createTime < lastTime ORDER BY createTime DESC LIMIT 20查询 A 所关注的人的内容列表则如下:
SELECT * FROM post WHERE userid IN (SELECT userRight FROM friendship WHERE userLeft = A.id) AND createTime < lastTime ORDER BY createTime DESC LIMIT 20查询拥有技术栈标签 T 的人的内容列表如下:
SELECT * FROM post WHERE userid IN (SELECT userid FROM user_tag WHERE tagID = T.id) AND createTime < lastTime ORDER BY createTime DESC LIMIT 20其中,lastTime是上一页最后一项的 createTime。另外,为了优化查询效率,还可以添加联合索引 (userid, createTime DESC)。关于索引的原理和如何正确使用的姿势,我觉得美团点评技术团队的这篇文章总结得不错:[MySQL索引原理及慢查询优化]http://tech.meituan.com/mysql-index.html。
写在最后
本项目的数据库设计相对也比较简单,还没有考虑很多复杂的场景,如双机热备、负载均衡、分布式集群等。在这些复杂场景下应该如何设计,目前也还没有好好思考过,所以暂时也不打算展开。接下来就要进入API服务端的实现阶段了。