【翻译】比较Pgpool-II和PgBouncer
凯文·马克沃特(Kevin Markwardt)
在我为PostgreSQL确定不同的HA解决方案的过程中,Pgpool和PgBouncer多次出现。因此,我决定对它们进行评估,并确定它们可以处理的性能。我这样做是因为我在互联网上看到的大多数博客都是在资源有限的笔记本电脑上进行测试的。在此评估中,我使用我的Google Cloud帐户启动了一些服务器,以用于测试现实世界中的更多场景,这些场景中服务器必须相互通信,并且每台服务器都具有更多专用的处理能力和内存。我配置了一个应用程序服务器,以使用pgbench将流量发送到Pgpool和PgBouncer,以查看我可以实现哪种性能,并分析了导致它们执行其行为方式的一些重要因素。
设定
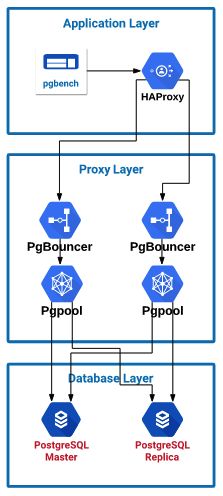
我设置了许多服务器来模拟具有不同基础结构层的典型环境。我仍然受限于我在Google Cloud环境中拥有的资源数量,所有实例之间总共有24个CPU。
- 具有HAProxy的应用程序服务器可将流量拆分到代理层:4个CPU / 3.6 GB内存(CentOS 7)
- 将安装两个用于Pgpool或PgBouncer的代理层服务器:4个CPU / 3.6 GB内存(CentOS 7)
- 两个具有PostgreSQL 10.6的数据库层服务器:4个CPU / 15 GB内存(PostgreSQL配置共享缓冲区增加到4GB)(CentOS 7)
PostgreSQL安装
为了构建PostgreSQL 10服务器,我使用了以前的方法通过此博客(https://blog.pythian.com/set-up-repmgr-witness-postgresql-10/)来设置和安装数据库服务器。它是一个由四台服务器组成的设置,其中包含一个主服务器,两个副本和一个使用Repmgr处理复制和故障转移的见证服务器。设置服务器后,由于我在Google Cloud中的CPU限制,我必须关闭第二个副本服务器和见证服务器的电源,以便为其他服务器提供足够的CPU。然后,我将shared_buffers增加到4096 MB,并将work_mem增加到64MB,以提高PostgreSQL服务器的性能。您可以在此处找到更多信息:https : //www.postgresql.org/docs/10/runtime-config-resource.html。现在,我有一个主服务器和一个副本服务器来处理传入的流量,并在PostgreSQL服务器之间进行读/写拆分,以扩展读取的流量。通过该博客中的配置,我还将代理层服务器添加到了pg_hba文件中,以允许数据库流量进入这些服务器。使用信任只能在测试解决方案中完成。您应该在生产环境中使用md5和密码
- 主机repmgr repmgr 10.128 0.0 0.12 / 32 的信任
- 主机repmgr repmgr 10.128 0.0 0.13 / 32 的信任
Pgpool-II-10设置
对于Pgpool,我首先安装了PostgreSQL yum存储库,然后从该存储库安装了Pgpool软件包。Pgpool带有一些预配置的配置文件,我使用主/从配置配置了Pgpool,并根据我的设置对其进行了自定义。这样,Pgpool可以检测到主服务器是谁,并相应地将写入流量路由到该主服务器。
1)为PostgreSQL 10安装PostgreSQL yum repo:
- yum install -y https ://下载.postgresql.org / pub / repos / yum / reporpms / EL -7-x86_64 / pgdg - redhat - repo - latest.noarch.rpm
- 百胜安装-y pgpool-II- 10 .x86_64
2)复制主从默认配置作为我们的主要配置:
- cd / etc / pgpool-II- 10
- cp pgpool.conf.sample-master-slave pgpool.conf
3)用我的设置修改了配置文件。我确保更新了pid文件路径,因为默认路径不起作用。在默认文件中找到设置,然后根据您的设置进行更新:
- listen_addresses = '*'
- pid_file_name = '/ var/run/pgpool-II-10/pgpool.pid '
- master_slave_sub_mode = '流'
- pool_passwd = ''
- sr_check_period = 1
- sr_check_user = 'repmgr'
- sr_check_password = 'repmgr'
- sr_check_database = 'repmgr'
- backend_hostname0 = 'psql-1'
- backend_port0 = 5432
- backend_weight0 = 1
- backend_data_directory0 = '/ var / lib / pgsql / 10 / data /'
- backend_flag0 = 'ALLOW_TO_FAILOVER'
- backend_hostname1 = 'psql-2'
- backend_port1 = 5432
- backend_weight1 = 1
- backend_data_directory1 = '/ var / lib / pgsql / 10 / data /'
- backend_flag1 = 'ALLOW_TO_FAILOVER'
4)复制用于Pgpool管理的默认PCP配置文件:
- cp pcp.conf.sample pcp.conf
5)创建管理员密码的MD5密钥:
- pg_md5 pgpool_pass
6)使用PCP管理员帐户的用户名和密码更新pcp.conf文件:
- pgpool_admin:af723b95947acb96f8690932fd2d8926
7)创建一个密码文件,以方便执行Pgpool admin命令:
- 触摸〜/ .pcppass
- CHMOD 600 〜/ .pcppass
- vim〜/ .pcppass
- *:*:pgpool_admin:pgpool_pass
8)启用并启动Pgpool服务:
- systemctl启用pgpool-II- 10
- systemctl启动pgpool-II- 10
- systemctl状态pgpool-II- 10
9)运行pcp命令并检查节点0的状态的示例:
- pcp_node_info -U pgpool_admin -w 0
- psql- 1 5432 1 0.333333 等待主0 1970年- 01 - 01 00 :00 :00
PgBouncer设置
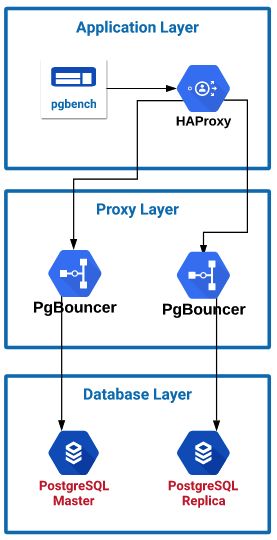
通过使用PostgreSQL 10存储库,我以与Pgpool相同的方式安装了PgBouncer。然后,我用两种不同的方式配置它。对于第一种配置,我将第一个PgBouncer服务器指向主节点,将第二个PgBouncer服务器指向从节点以在不涉及Pgpool的情况下对其进行测试。使用这种类型的设置,必须将应用程序配置为将流量发送到正确的位置。因为我只处理读流量,并且对性能测试更感兴趣,所以我不必担心读/写流量的路由,只会发送读流量。对于第二轮测试,我将PgBouncer配置为指向同一服务器上的Pgpool。然后,Pgpool将流量发送到数据库服务器。
1)安装PgBouncer:
- 百胜安装-y pgbouncer
2)在/etc/pgbouncer/pgbouncer.ini中编辑pgbouncer配置,以添加数据库以将流量发送到:
- [ 数据库]
- repmgr = host = psql- 1 dbname = repmgr #在不使用Pgpool 进行测试时使用
- repmgr =主机= 127.0 .0 .1 端口= 9999 dbname = repmgr #与Pgpool一起 测试时使用
- [ pgbouncer ]
- listen_addr = *
3)在/etc/pgbouncer/userlist.txt中创建一个新的用户列表,其中将包含允许使用PgBouncer的用户列表。由于我使用的是信任关系,因此没有配置密码:
- “ repmgr” “”
4)启用并启动服务:
- systemctl启用pgbouncer
- systemctl启动pgbouncer
应用服务器设置
为了在应用服务器上安装pgbench,我从PostgreSQL yum存储库安装了PostgreSQL 10客户端。接下来,为了在代理层之间分配流量,我安装了HAProxy并将其配置为在两个服务器之间发送流量。要重定向来自Pgpool和PgBouncer的流量,我只需要更新HAProxy配置中的端口并重新加载配置即可。
1)安装PostgreSQL客户端和HAProxy:
- yum install -y https ://下载.postgresql.org / pub / repos / yum / reporpms / EL -7-x86_64 / pgdg - redhat - repo - latest.noarch.rpm
- 百胜安装-y postgresql10 haproxy
2)在/etc/haproxy/haproxy.cfg中配置HAProxy :
- 前端pg_pool_cluster
- 绑定*:54321
- acl d1 dst_port 54321
- use_backend pgpool如果是d1
- default_backend pgpool
- 后端pgpool
- 模式tcp
- 平衡轮循
- 选项tcp-check
- 选项日志运行状况检查
- 服务器pgpool- 1 1 10.128 .0 .13 :9999 inter 1000 下降2 上升1 检查端口9999
- 服务器pgpool- 2 10.128 .0 .14 :9999 内部1000 下降5 上升1 检查端口9999
3)启用并启动HAProxy:
- systemctl启用haproxy
- systemctl启动代理
然后,我将以下命令与pgbench一起使用,以在主PostgreSQL服务器上初始化测试数据库:
- pgbench repmgr -h psql- 1 -U repmgr -i -s 50 pgpooltest
这些是我用来命中本地HAProxy服务器并更改进入连接数的pgbench命令:
- pgbench repmgr -U repmgr -h 127.0 .0 .1 -p54321 -P 5 -S -T 30 -c 100 pgpooltest
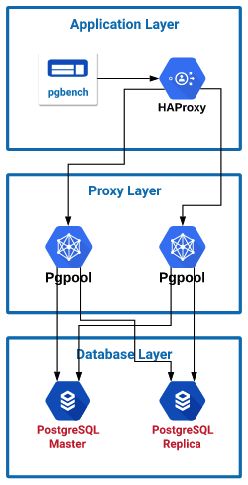
Pgpool测试
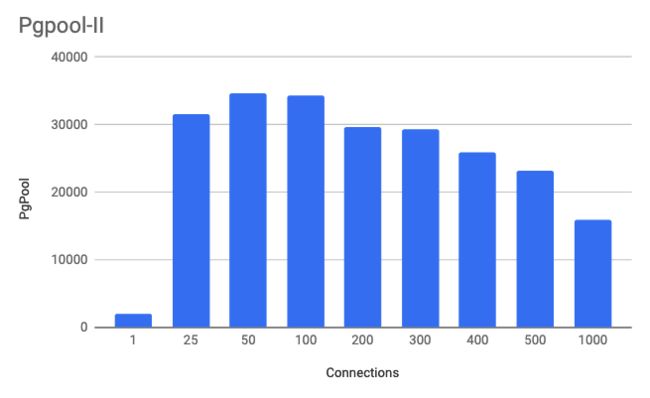
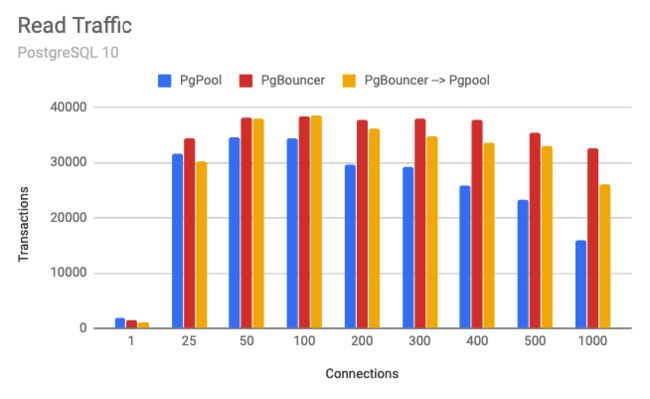
在第一个设置中,我将pgbench配置为将流量发送到本地HAProxy服务器,然后将流量分配给两个Pgpool服务器。然后,将Pgpool配置为在两个PostgreSQL服务器之间实现流量负载平衡。由于Pgpool可以检测到主服务器和从服务器,因此它可以自动将流量写入主机和从两个服务器读取流量。随着连接开始增加,拥有多台Pgpool服务器有助于提高吞吐量。启动Pgpool服务器时,我在进程列表中注意到它为可能出现的每个潜在连接创建了一个新进程。我相信这可能是随着连接数增加而性能下降的部分原因。该图上要注意的关键是,我达到了约50到100个连接的峰值性能。我将在最终设置中使用此信息。平均而言,由于Pgpool的代理部分分析了查询,因此我发现CPU利用率约为30-40%。我尝试在Pgpool中打开本地内存查询缓存,而我的工作量只会损害性能而不是提高性能。
- 连接是两台服务器之间的总连接。
- 事务仅每秒读取一次。
。 
PgBouncer测试
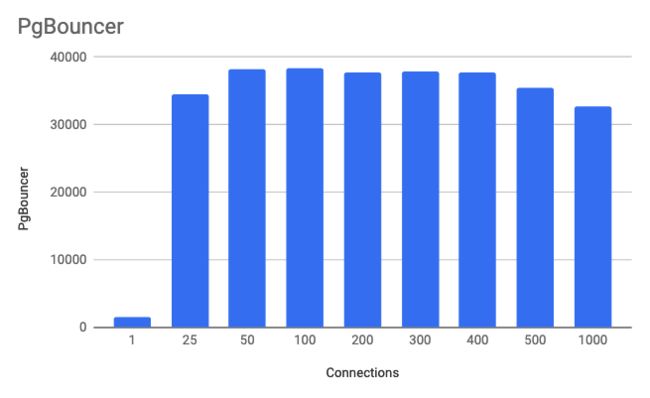
在第二种设置中,我将pgbench配置为将流量发送到本地HAProxy服务器,然后将流量分配给两个PgBouncer服务器。如前所述,PgBouncer不是代理。严格来说,它是一个连接池管理器。因此,我们必须将每个PgBouncer服务器配置为指向单个PostgreSQL实例。HAProxy允许我在两个PgBouncer服务器之间分配读取流量,然后将流量发送到两个PostgreSQL服务器。PgBouncer服务器1将流量发送到PostgreSQL主服务器,而PgBouncer服务器将流量发送到PosgreSQL副本。在生产设置中,您的应用程序必须具有将读取流量发送到一个位置并将写入流量发送到另一个位置的能力,以便利用PgBouncer拆分读取和写入流量。一般,仅使用的PgBouncer服务器的CPU使用率为3%。这是因为PgBouncer没有代理,也没有分析通过它的查询。
- 连接是两台服务器之间的总连接。
- 事务仅每秒读取一次。
 转存失败重新上传取消
转存失败重新上传取消
PgBouncer –> Pgpool测试
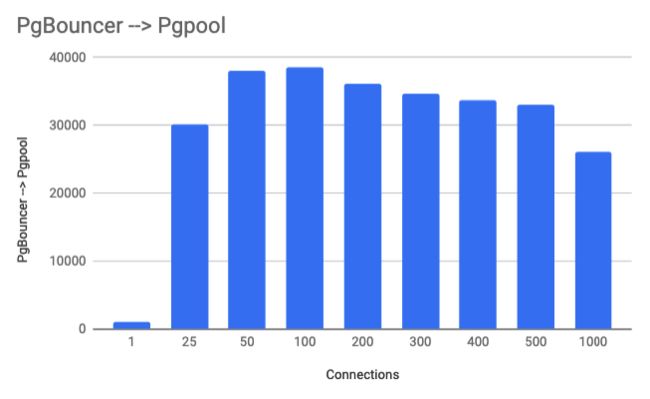
在我的最终设置中,我注意到Pgpool不能很好地处理连接,当您超过100个连接后,性能开始受到影响。因此,我将PGpool中的连接限制设置为100。这样,连接数超过100时,Pgpool的性能不会降低。然后,我将PGBouncer放在Pgpool的前面,并将PgBouncer内的连接限制设置为大约2000个连接,以便将连接倒入PgBouncer,然后PgBouncer将根据需要管理连接和队列查询。这样,随着大量连接的进入,PgBouncer会将进入Pgpool的流量级别保持在最佳的100个连接级别。我看到代理层服务器上的平均利用率约为30%。
- 连接是两台服务器之间的总连接。
- 事务仅每秒读取一次。
比较结果
通过使用PgBouncer来确保Pgpool获得最佳连接数,我们可以看到,随着连接数量的增加,我们已经显着提高了Pgpool的性能。只需将PgBouncer放在前面并确保只有最佳数量的连接进入Pgpool,就可以在1000个总连接数(每个服务器500个)时从每秒约1.5万个事务/秒,到连接数相同时约〜2.5万个事务/秒。
重要要点
- PgBouncer不会检查查询,并且在管理连接方面做得很出色,从而保持了非常低的CPU利用率。
- 如果不使用Pgpool,则应用程序需要完成读写拆分。无需Pgpool检查流量即可达到最高性能,但是需要进行更多工作才能在应用程序处拆分流量,然后设置其他方法来路由流量。
- Pgpool不能很好地管理连接,因为它会在服务启动时为每个连接生成一个新的进程。但是与PgBouncer结合使用,可以保持更好的性能。
- Pgpool是一个代理,可以分析查询,并可以相应地路由流量。它还可以检测复制设置中的主服务器,并自动重定向写流量。这项工作导致更高的CPU使用率在服务器上。
- 随着连接数量的增加,Pgpool的性能会下降。在具有四个CPU的情况下,性能开始下降之前,每个服务器的最大连接数约为100。
- 具有25个以上连接的Pgpool通过在其前面添加PgBouncer来提高性能。如果每个PgPool服务器上需要100个以上的连接,则PgBouncer是“必备”。
- 如果您使用的是Pgpool,则仅将PgBouncer与它一起使用才有意义。
原文链接:https://blog.pythian.com/comparing-pgpool-ii-and-pgbouncer/
比较文章2,来自EDB:https://www.enterprisedb.com/blog/pgpool-vs-pgbouncer
数据库连接池是有用的工具,使组织能够通过有效利用Postgres来交付高性能的应用程序。实施高质量的连接池是使用Postgres的客户经常提出的要求,尽管可能只有少数解决方案可以满足他们的需求,但确定最佳选择并不总是那么容易。Pgpool -II和PgBouncer是两个最著名的数据库连接池。每个选项都为可以本地使用的数据库连接功能添加了功能,但是每个工具都有其自身的优点和缺点。
汇集解决方案的期望
在典型情况下,PgBouncer可以“开箱即用”地正确执行池化,而Pgpool-II需要对某些参数进行微调以实现理想的性能和功能。PgBouncer和Pgpool-II都可以断开与Postgres的连接和重新连接。对于本地缺乏此功能的应用程序平台,连接池将这些功能直接添加到应用程序层中以实现有效的数据库连接。为了说明连接池的正确实现,请设想一个具有一个主数据库和五个备用数据库的客户端。对于此示例,工作负载大部分是只读的,并且需要大量资源。PgBouncer和Pgpool-II具有管理成千上万个连接的功能,即使使用的连接数少于100个,它也可以跟踪其他900个连接,同时保持高性能。
合适工作的合适工具
在理想的PgBouncer方案中,考虑一个应用程序环境,其中许多小应用程序与Postgres建立连接。在任何给定时间仅使用少量应用程序,并且应用程序打开的连接并不总是处于活动状态或正在使用中。PgBouncer非常适合这种情况,因为它擅长将数据库连接数从1,000个减少到100个,这可以节省Postgres中的大量资源。Pgpool-II通常由于其附加功能而由组织实施,但这不一定使Pgpool-II成为所有用例的理想选择。许多人认为Pgpool-II是最终解决方案,但实际上,对于断开数据库连接是关键的情况,PgBouncer通常是更好的解决方案。
部署解决方案
Pgpool-II的错误实现可能导致数据库出现性能问题的情况。在这种情况下,Pgpool-II的“解决方案”通常比最初的问题要糟糕。同样,PgBouncer可能是高效的,剥离的连接池,但缺少一些可能对典型情况具有吸引力的功能,例如能够在待机状态下运行只读查询。
在着手实现连接池之前,请先遍历数据库连接情况和只读查询方案,以确定您是否需要只读功能,或者将从缓冲连接中获得更大的好处。
对于降低数据库连接,PgBouncer是最强大的解决方案-以利用备用资源为代价。如果您同时需要这两种情况,则Pgpool-II可能是更好的选择,但是将需要适当的配置,调整和测试。
选择连接池时,没有灵丹妙药:在Pgpool-II和PgBouncer之间进行选择完全取决于您的组织正在尝试做什么。尽管Pgpool-II和PgBouncer可以结合使用,但同时堆叠这两种解决方案会增加额外的延迟,从而造成一种情况,与仅实施两种方法之一相比,情况可能更糟。企业最终必须选择最全面的解决方案。