Python数据挖掘实战——贝叶斯分类算法
1.1贝叶斯定理(Bayes Theorem)
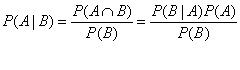
eg.判断一个人品质的好坏是根据一个人过往的行为进行判断的,但是对于陌生人一开始初始化为50%好人、50%坏人,如果之后他做了一件好事,这个事会增加我们判断他为好人的根据。如果发现他做了一件坏事,会增加他是坏人的概率。
1.2朴素贝叶斯分类(Naive Bayes Classifier)
贝叶斯分类算法,是统计学的一种分类方法,它是利用贝叶斯定理的概率统计知识,对离散型数据进行分类的算法。
案例:

问题:现在来了第七个病人,是一个打喷嚏的建筑工人,他患上哪种疾病的概率最大?
解答:


从上表中可以看出,
感冒有3例,其中打喷嚏为两例,所以打喷嚏的概率为2/3 = 0.66;
感冒有3例,建筑工人感冒为1例,所以建筑工人感冒的概率为:1/3 = 0.33
疾病一共6例,感冒有3例,所以得感冒的概率为:1/2 = 0.5 ,同理打喷嚏的概率也为:1/2 = 0.5
一共6个职业,建筑工人为2人,所以建筑工人的概率为:2/6 = 0.33
P(感冒|打喷嚏 × 建筑工人)=P(打喷嚏|感冒) × P(建筑工人|感冒) × P(感冒) / P(打喷嚏) × P(建筑工人)
=0.66 × 0.33 × 0.5 / 0.5 × 0.33
0.66
同理:
P(过敏|打喷嚏 × 建筑工人)
=P(打喷嚏|过敏) × P(建筑工人|过敏) × P(过敏) / P(打喷嚏) × P(建筑工人)
=1 × 0 × 0.17 / 0.5 × 0.33
= 0
P(脑震荡|打喷嚏 × 建筑工人)
=P(打喷嚏|脑震荡) × P(建筑工人|脑震荡) × P(脑震荡) / P(打喷嚏) × P(建筑工人)
=0 × 0.5 × 0.5 / 0.5 × 0.33
= 0
综上所述:
这个病人最有可能患病的是感冒了。
二、贝叶斯分类算法的类型
2.1sklearn包naive_bayes模块
1)GaussianNB 高斯贝叶斯算法
适用于数据正太分部,具体求解释可以不用知道每个样本的数值,只需要知道均值和方差,就可以计算。
适用于特征值伯努利分部的数据。0和1,是和否这样的数据。
3)MultinomiaLNB 多项式贝叶斯算法(用的最多,文本分类场景)特征值不知道属于哪种分部,统计每个特征的分部。需要知道每个特征值的数值大小。
三、多项式贝叶斯算法进行文本分类
# -*- coding: utf-8 -*-
import os
import codecs
import os.path
#1.先给每个类别标注一个名称,不能简单用文本名了。
classDict = {
'C000007': '汽车',
'C000008': '财经',
'C000010': 'IT',
'C000013': '健康',
'C000014': '体育',
'C000016': '旅游',
'C000020': '教育',
'C000022': '招聘',
'C000023': '文化',
'C000024': '军事'
}
#2.搭建语料库
rootDir = "C:\\Python_DM\\5.2\\SogouC.mini\\Sample"
classes = [];
filePaths = [];
fileContents = [];
for c in classDict.keys():
fileDir = os.path.join(rootDir, c)
for root, dirs, files in os.walk(fileDir):
for name in files:
filePath = os.path.join(fileDir, name);
classes.append(classDict[c]);
filePaths.append(filePath);
f = codecs.open(filePath, 'r', 'utf-8')
fileContent = f.read()
f.close()
fileContents.append(fileContent)
import pandas;
corpos = pandas.DataFrame({
'class': classes,
'filePath': filePaths,
'fileContent': fileContents
});
#3.分词建立文本向量,有了文本向量就有了分类的特征值了。
#文本向量=文本的特征值
#不同的文章,每个词出现的频率都是不一样的。
import re
#匹配中文的分词
zhPattern = re.compile(u'[\u4e00-\u9fa5]+')
import jieba
segments = []
filePaths = []
for index, row in corpos.iterrows():
segments = []
filePath = row['filePath']
fileContent = row['fileContent']
segs = jieba.cut(fileContent)
for seg in segs:
if zhPattern.search(seg):
segments.append(seg)
filePaths.append(filePath)
row['fileContent'] = " ".join(segments);
from sklearn.feature_extraction.text import CountVectorizer
stopwords = pandas.read_csv(
"C:\\Python_DM\\5.2\\StopwordsCN.txt",
encoding='utf8',
index_col=False,
quoting=3,
sep="\t"
)
countVectorizer = CountVectorizer(
stop_words=list(stopwords['stopword'].values),
min_df=0, token_pattern=r"\b\w+\b"
)
textVector = countVectorizer.fit_transform(corpos['fileContent'])
#多项式贝叶斯算法
from sklearn.naive_bayes import MultinomialNB
MNBModel = MultinomialNB()
#fit方法进行模型训练。
#把文本向量作为特征值传入,
#把文本对应的序列作为目标序列传入。
MNBModel.fit(textVector, corpos['class'])
#不进行交叉验证
#调用score进行评分
MNBModel.score(textVector, corpos['class'])
#网上找一篇文章,赋值给新的文本变量。
#对这篇文章的所属分类进行预测
newTexts = ["""
据介绍,EliteBook 840 G4是一款采用14英寸1080p屏幕的商务笔记本,
硬件配置方面,入门级的EliteBook 840 G4搭载Intel Core i3-7100处理器,
配备4GB内存和500GB机械硬盘,预装Windows 10操作系统。
高端机型可选择更大容量的内存和SSD固态硬盘。
机身四周提供了USB 3.0、USB-C、DisplayPort、15针迷你D-Sub,
支持蓝牙4.2和802.11ac Wi-Fi。
整机重1.48千克。
"""]
for i in range(len(newTexts)):
newTexts[i] = " ".join(jieba.cut(newTexts[i]));
#countVectorizer生成这篇文章的文本向量
newTextVector = countVectorizer.transform(newTexts)
#调用贝叶斯模型的predict进行预测
MNBModel.predict(newTextVector)
"""
Out[16]:
array(['IT'],
dtype='