用python数据分析了北京积分落户名单,发现……
↑ 关注 + 置顶 ~ 有趣的不像个技术号


北京积分落户制度已经实行两年了,2018年申报积分落户的124657名申请人中6019位落户人员取得落户资格。
而去年2019年,申报积分落户人数为106403名,实际公示名单共6007人。
准备打开官方网站下载数据分析一下,结果发现过了公示期网页就打不开了。
经过一番努力,在网上收集到了2018年的6019位落户人员名单和信息(均为公开展示信息)。
01
数据分析
我们本次用到的分析工具包有:pandas 、seaborn 和Matplotlib。
落户数据是csv文档(文末可下载),内部记录了6019条落户信息。
所以先利用pandas读取数据csv文档,并看看有哪些列,可以看到这个表有4列构成,人名、生日、公司、积分
luohu_data = pd.read_csv('./bj_luohu.csv', index_col = 'id')
luohu_data.head(5)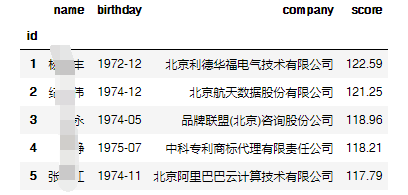
此时有一个疑问这些人来自哪些公司呢?公司有没有重复的? 这些公司都是哪些行业的?
所以按照公司分组查看一下:
company_data = luohu_data.groupby('company', as_index=False).count()[['company', 'name']]
company_data.rename(columns={'name':'人数'}, inplace=True) # 替换 1
company_data.rename(columns={'company':'公司名'},inplace=True) # 替换 2
company_data.head(20)
这么直接看的话人数没有顺序的,所以我们再对人数进行降序排列,看看落户最多的哪几家!
company_sorted_data = company_data.sort_values('人数', ascending=False)
company_sorted_data.head(15) # 前15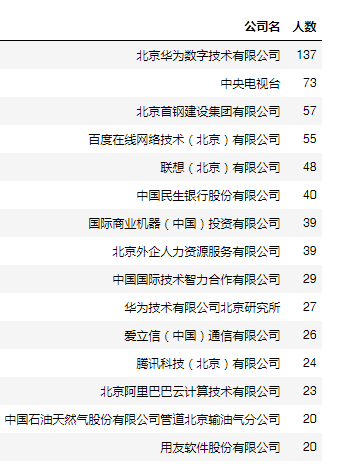
emmmm。。。。满眼科技公司,华为、百度、联想、爱立信、腾讯均在前15名,其次是一些国企央之类的。
2
数据可视化
积分数socre是连续数值,因此这里进行分段分析,经过describe初步了解,得分最小90,最大122.6 所以这么划分:90-130分,5分一段
cut_bins = np.arange(90, 130, 5) #分段设置
bins = pd.cut(luohu_data['score'], cut_bins) # 将落户数据,按照cutbins来切一下
bin_counts = luohu_data['score'].groupby(bins).count()
bin_counts.head(10)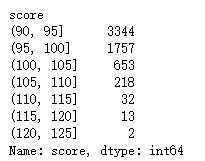
直接出来的话是数据,那么我在直接画个图更直观的看一下
plt.figure(figsize=(15,8))
plt.rcParams['font.family']='Arial Unicode MS'
plt.rcParams['axes.unicode_minus']=False
plt.rcParams['font.size']=12
x_name=['90-95','95-100','100-105','105-110','110-115','115-120','120-125']
sns.barplot(x_name,bin_counts)
plt.ylabel('人数')
plt.xlabel('分数区间')
for x, y in zip(range(7), bin_counts):
plt.text(x, y+20 , y, ha='center', va='bottom')
plt.show()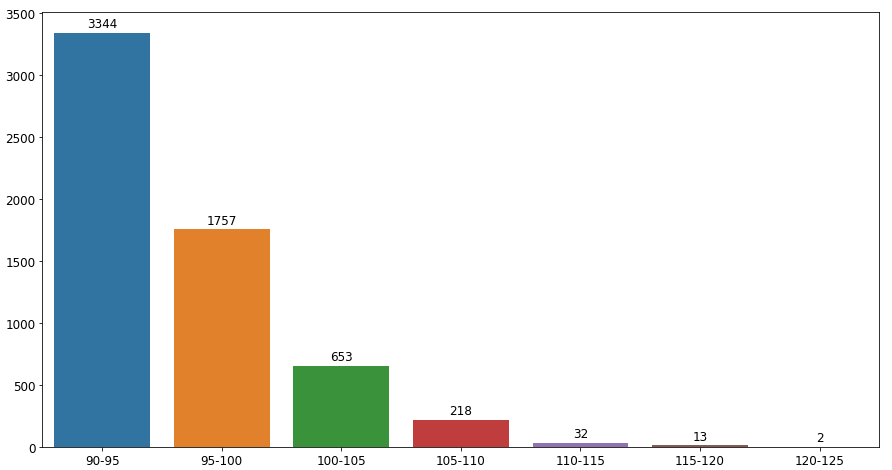
可以看到,落户人数主要集中在90-100分之间,合计5101人,如果想落户,达到95分就没什么问题了。
那么现在又有个问题,比如达到90分以上我都60了也没啥意义了,那么这些落户的主要集中在什么年龄段呢?年龄与积分有相关性吗?来看看。
首先需要根据生日算一下落户年龄
luohu_data['age'] = (pd.to_datetime('2018-07') - pd.to_datetime(luohu_data['birthday'])) / pd.Timedelta('365 days')
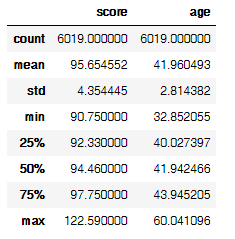
luohu_data.describe()
mean=luohu_data['age'].mean()
std =luohu_data['age'].std()
# 得到上下限
lower , upper =mean -3*std , mean+3*std
print('均值',mean)
print('标准差',std)
print('下限',lower)
print('上限',upper)得到:

作图看一下分布
#fig.set_size_inches(15,5) # 设置画布大小
sns.distplot(luohu_data['age']) 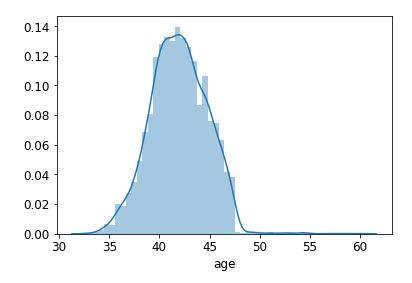
可以看到,最小的年龄也32岁了最大年龄60岁,75%分位数在43岁左右。年龄均值42岁。
3
总结
根据本篇简单的数据分析我们发现:
通过积分获得北京户口的年龄段集中在35岁到46岁之间,主要为42±2岁之间;积分集中在90分左右,行业集中在IT和国企央企及金融行业。
据有关媒体统计,在北京当前的积分落户政策下,本科生需要15左右年才能拿到100分,研究生也需要12年以上才能拿到100分。
大家想一下:虽然现在100分可以落户,但12/15年后跟你同批的毕业生就全都100分了......
而其他城市的落户政策是上海七年,香港七年,深圳一年,北京落户还真是真是不容易啊。
相关分析源码和北京积分落户数据已上传github:https://github.com/zpw1995/aotodata/tree/master/bj_luohu
作者:董汇标MINUS,关注知乎点击左下角原文链接。
微信首发于公众号【凹凸玩数据】,有趣的不像个技术号
End
想了解更多更好玩的数据分析知识,
扫描下方二维码关注我们吧!

读者交流群已建立,后台回复「微信群」即可
加入与作者一起讨论交流
