自然语言处理学习8:python使用standford CoreNLP进行中文分词、标注和命名实体识别
jieba分词可以进行中文分词和标注,但是无法进行命名实体识别。
1. 环境配置
(1) 下载安装JDK 1.8及以上版本
(2)下载Stanford CoreNLP文件,解压。
(3)处理中文还需要下载中文的模型jar文件,然后放到stanford-corenlp-full-2016-10-31根目录下即可(注意一定要下载这个文件哦,否则它默认是按英文来处理的)。
(4)pip安装standford CoreNLP:pip install stanfordcorenlp
2. 使用standford CoreNLP进行中文分词:并和结巴分词进行对比
import logging
from stanfordcorenlp import StanfordCoreNLP #导入StandfordCoreNLP模块
nlp = StanfordCoreNLP('C:/myLearning/stanford-corenlp-full-2016-10-31',port=9011, lang='zh',logging_level=logging.DEBUG)
sentence = '合肥工业大学在屯溪路193号,李勇在这里上大学'
['合肥', '工业', '大学', '在', '屯溪路', '193', '号', ',', '李勇', '在', '这里', '上', '大学']import jieba
print(jieba.lcut(sentence))
['合肥工业大学', '在', '屯溪路', '193', '号', ',', '李勇', '在', '这里', '上', '大学']print(jieba.lcut(sentence,cut_all=True))
['合肥', '合肥工业大学', '工业', '业大', '大学', '在', '屯溪', '屯溪路', '193', '号', '', '', '李', '勇', '在', '这里', '上', '大学']
3. 使用standford CoreNLP进行词性标注: 和jieba分词进行对比
standford词性标注中词性对应的符号可参考文章:https://www.cnblogs.com/tonglin0325/p/6850901.html
print(nlp.pos_tag(sentence))
[('合肥', 'NR'), ('工业', 'NN'), ('大学', 'NN'), ('在', 'P'), ('屯溪路', 'NR'), ('193', 'OD'), ('号', 'NN'), (',', 'PU'), ('李勇', 'NR'), ('在', 'P'), ('这里', 'PN'), ('上', 'VV'), ('大学', 'NN')]
import jieba.posseg as pseg
print(pseg.lcut(sentence))
[pair('合肥工业大学', 'nt'), pair('在', 'p'), pair('屯溪路', 'ns'), pair('193', 'm'), pair('号', 'm'), pair(',', 'x'), pair('李勇', 'nr'), pair('在', 'p'), pair('这里', 'r'), pair('上', 'f'), pair('大学', 'n')]
4. 使用standford CoreNLP进行命名实体识别:jieba模块没有此功能
命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。通常包括两部分:(1)实体边界识别;(2) 确定实体类别(人名、地名、机构名或其他)。
print(nlp.ner(sentence))
[('合肥', 'ORGANIZATION'), ('工业', 'ORGANIZATION'), ('大学', 'ORGANIZATION'), ('在', 'O'), ('屯溪路', 'FACILITY'), ('193', 'FACILITY'), ('号', 'FACILITY'), (',', 'O'), ('李勇', 'PERSON'), ('在', 'O'), ('这里', 'O'), ('上', 'O'), ('大学', 'O')]
5. 相关错误及解决
出现"waiting until the server is avaible"错误,一直运行不出来。
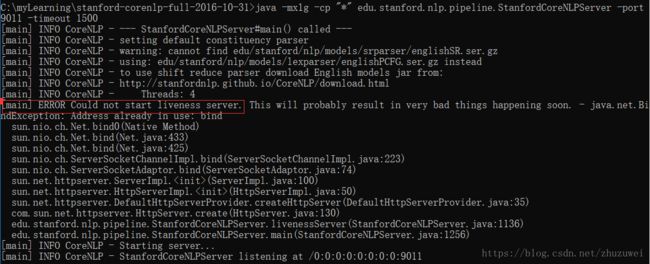
以管理员身份打开cmd,切换到Stanford CoreNLP文件解压后的文件夹路径,执行以下命令打开StanfordCoreNLPServer。
java -mx1g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9011 -timeout 1500
红框中的错误"ERROR Could not start liveness server"不知道是什么意思,待补充,欢迎交流学习。但是可以顺利执行以上分词、词性标注和命名实体识别的功能了。