Flume的使用和配置、底层原理
 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
大数据组件使用 总文章
===========Apache Flume============
1.概述
1.Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的软件。
2.Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目的地(sink)。 为了保证输送的过程一定成功, 在送到目的地(sink)之前,
会先缓存数据(channel),待数据真正到达目的地(sink)后,flume 在删除自己缓存的数据。
3.Flume 支持定制各类数据发送方,用于收集各类型数据;同时,Flume 支持定制各种数据接收方,用于最终存储数据。
4.一般的采集需求,通过对 flume 的简单配置即可实现。针对特殊场景也具备良好的自定义扩展能力。因此,flume 可以适用于大部分的日常数据采集场景。
5.当前 Flume 有两个版本。Flume 0.9X 版本的统称 Flume OG(original generation) ,Flume1.X 版本的统称 Flume NG(next generation) 。
6.由于 Flume NG 经过核心组件、核心配置以及代码架构重构,与 Flume OG 有很大不同,使用时请注意区分。改动的另一原因是将 Flume 纳入 apache 旗下,
Cloudera Flume 改名为 Apache Flume。
2.运行机制
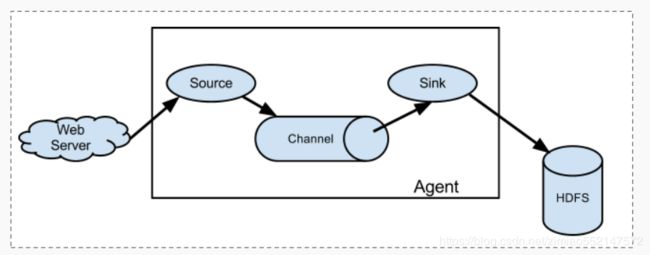
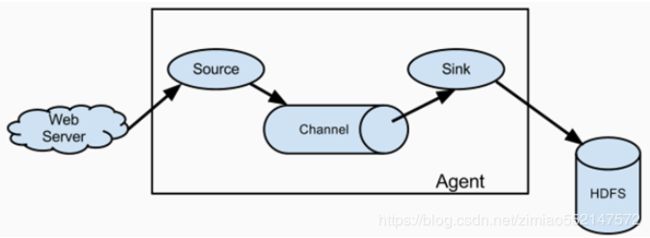
1.Flume 系统中核心的角色是 agent,agent 本身是一个 Java 进程,一般运行在日志收集节点。
2.每一个 agent 相当于一个数据传递员,内部有三个组件:
1.Source:采集源,用于跟数据源对接,以获取数据;
2.Sink:下沉地,采集数据的传送目的,用于往下一级 agent 传递数据 或者 往最终存储系统传递数据;
3.Channel:
agent 内部的数据传输通道,用于从 source 将数据传递到 sink;
在整个数据的传输的过程中,流动的是 event,它是 Flume 内部数据传输的最基本单元。
event 将传输的数据进行封装。 如果是文本文件, 通常是一行记录,event 也是事务的基本单位。
event 从 source,流向 channel,再到 sink,本身为一个字节数组,并可携带 headers(头信息)信息。
event 代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
一个完整的 event 包括:event headers、event body、event 信息,其中event 信息就是 flume 收集到的日记记录。
3.Flume 采集系统结构图
1.简单结构:单个 agent 采集数据
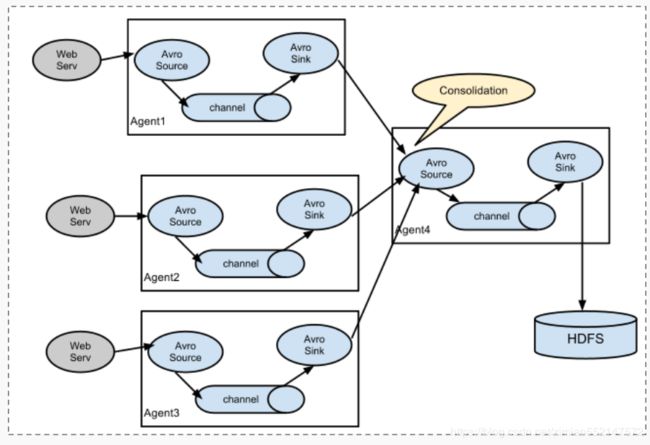
2.复杂结构:多级 agent 之间串联
==============Flume 简单案例===============
1.采集目录 到 HDFS
1.采集需求:服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到 HDFS 中去
2.根据需求,首先定义以下 3 大要素:
1.采集源:即 source — 监控文件目录 spooldir
2.下沉目标:即 sink — HDFS 文件系统 hdfs sink
3.source 和 sink 之间的传递通道 — channel,可用 file channel 也可以用内存 channel
3.配置文件编写:
# 定义这个 agent 中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置 source 组件:r1
##注意:不能往监控目录中重复丢同名文件
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/logs
a1.sources.r1.fileHeader = true
# 描述和配置 sink 组件:k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是 Sequencefile,可用 DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# 描述和配置 channels 组件c1 ,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 描述和配置 source、channel、sink 之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
4.Channel 参数解释:
capacity:默认该通道中最大的可以存储的 event 数量
trasactionCapacity:每次最大可以从 source 中拿到 或者 送到 sink 中的 event 数量
2.采集文件 到 HDFS
1.采集需求:比如业务系统使用 log4j 生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到 hdfs
2.根据需求,首先定义以下 3 大要素
1.采集源:即 source — 监控文件内容更新:exec ‘tail -F file’
2.下沉目标:即 sink — HDFS 文件系统:hdfs sink
3.Source 和 sink 之间的传递通道 — channel,可用 file channel 也可以用 内存 channel
3.配置文件编写:
# 定义这个 agent 中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置 source 组件:r1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/logs/test.log
a1.sources.r1.channels = c1
# 描述和配置 sink 组件:k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/tailout/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是 Sequencefile,可用 DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# 描述和配置 channels 组件c1,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 描述和配置 source、channel、sink 之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
4.参数解析:
1.rollInterval
默认值:30
hdfs sink 间隔多长将临时文件滚动成最终目标文件,单位:秒;
如果设置成 0,则表示不根据时间来滚动文件;
注:滚动(roll)指的是,hdfs sink 将临时文件重命名成最终目标文件,并新打开一个临时文件来写入数据;
2.rollSize
默认值:1024
当临时文件达到该大小(单位:bytes)时,滚动成目标文件;
如果设置成 0,则表示不根据临时文件大小来滚动文件;
3.rollCount
默认值:10
当 events 数据达到该数量时候,将临时文件滚动成目标文件;
如果设置成 0,则表示不根据 events 数据来滚动文件;
4.round
默认值:false
是否启用时间上的“舍弃”,这里的“舍弃”,类似于“四舍五入”。
5.roundValue
默认值:1
时间上进行“舍弃”的值;
6.roundUnit
默认值:seconds
时间上进行“舍弃”的单位,包含:second,minute,hour
示例:
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
当时间为 2015-10-16 17:38:59 时候,hdfs.path 依然会被解析为:
/flume/events/20151016/17:30/00
因为设置的是舍弃 10 分钟内的时间,因此,该目录每 10 分钟新生成一个。 =============Apache Flume--案例--采集 目录/文件 至 HDFS==============
----------采集目录 到 HDFS------------
采集目录 到 HDFS
1.采集需求:服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到 HDFS 中去
2.根据需求,首先定义以下 3 大要素:
1.采集源:即 source — 监控某文件所在的目录,配置“spoolDir = 要监控的文件所在的目录”
2.下沉目标:即 sink — HDFS 文件系统 hdfs sink
3.source 和 sink 之间的传递通道 — channel,可用 file channel 也可以用内存 channel
实现步骤:
1.mkdir -p /root/logs
2.cd /root/flume/conf
3.vim spooldir-hdfs.conf内容如下:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
##注意:不能往监控目中重复丢同名文件
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/logs
a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
4.启动flume:
1.cd /root/flume
2.chmod 777 flume-ng
3.启动命令:bin/flume-ng agent -c conf/ -f conf/spooldir-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
-c conf 或 --conf conf:指定 flume 框架自带的配置文件所在目录名
-f conf/xxx.conf 或 --conf-file conf/xxx.conf:指定我们所自定义创建的采集方案为conf目录下的xxx.conf
-name agent的名字:指定我们这个agent 的名字
启动的最后会显示:Component type: SOURCE, name: r1 started
表示 r1 已经启动
4.注意:
此处之所以只执行“cd /root/flume”,而不是执行“cd /root/flume/bin”,是因为启动命令中要指定的是以当前路径为开始找配置文件,
比如 “--conf conf/” 表示以 “/root/flume”的当前路径找到“conf/”。
比如“--conf-file conf/netcat-logger.conf”表示以 “/root/flume”的当前路径找到“conf目录下的netcat-logger.conf”。
5.测试是否成功:
往/root/logs 放文件(比如 mv xx.log /root/logs 或 cp xx.log /root/logs)
然后flume打印的信息最后显示:Writer callback called
访问http://node1:50070/ 便能查看到如下信息,自动创建多了一个/flume/events/目录用于存储数据
-------------采集文件 到 HDFS------------------
采集文件 到 HDFS
1.采集需求:比如业务系统使用 log4j 生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到 hdfs
2.根据需求,首先定义以下 3 大要素
1.采集源:即 source — 监控文件内容更新:exec ‘tail -F file’
2.下沉目标:即 sink — HDFS 文件系统:hdfs sink
3.Source 和 sink 之间的传递通道 — channel,可用 file channel 也可以用 内存 channel

实现步骤:
1.vim /root/logs/test.log 中保存任意数据保存退出
2.cd /root/flume/conf
3.vim tail-hdfs.conf 内容如下:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/logs/test.log
a1.sources.r1.channels = c1
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/tailout/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
4.启动flume:
1.cd /root/flume
2.chmod 777 flume-ng
3.启动命令: bin/flume-ng agent -c conf/ -f conf/tail-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
-c conf 或 --conf conf:指定 flume 框架自带的配置文件所在目录名
-f conf/xxx.conf 或 --conf-file conf/xxx.conf:指定我们所自定义创建的采集方案为conf目录下的xxx.conf
-name agent的名字:指定我们这个agent 的名字
启动的最后会显示:Writer callback called
4.注意:
此处之所以只执行“cd /root/flume”,而不是执行“cd /root/flume/bin”,是因为启动命令中要指定的是以当前路径为开始找配置文件,
比如 “--conf conf/” 表示以 “/root/flume”的当前路径找到“conf/”。
比如“--conf-file conf/netcat-logger.conf”表示以 “/root/flume”的当前路径找到“conf目录下的netcat-logger.conf”。
5.测试是否成功:
在第一台Linux下 执行 while true ; do echo 'access access....' >>/root/logs/test.log;sleep 0.5;done 便可不断往 /root/logs/目录下的test.log存储数据,
那么flume便能监听到“tail -F /root/logs/test.log”动态打印的信息,然后把该些信息写入到/flume/tailout/目录下的文件中。
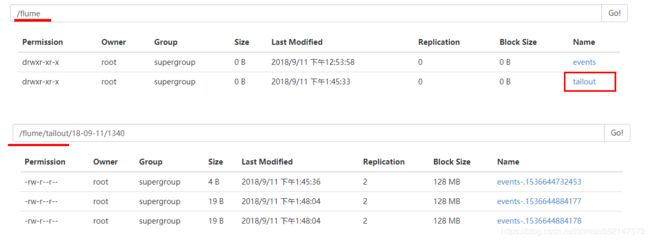
访问http://node1:50070/ 便能查看到如下信息,自动创建多了一个/flume/tailout/目录用于存储数据

=============== Flume 的 load balance 负责负载均衡============
Flume 的 load balance(负责负载均衡:负载均衡机制下的每台Flume 可通过轮询或随机的方式 接收Event信息)
Flume 的 failover(负责容错:在容错机制下,负载均衡集群中只有一台Flume在接收Event信息,只有当这一台Flume挂掉之后,才会继续由其他下一个Flume接收Event信息)
负载均衡是用于解决一台机器(一个进程)无法解决所有请求而产生的一种算法。
1.load balance(负责负载均衡:负载均衡机制下的每台Flume 可通过轮询或随机的方式 接收Event信息)
1.Load balancing Sink Processor 能够实现 load balance 功能,如下图 Agent1 是一个路由节点,
负责将 Channel 暂存的 Event 均衡到对应的多个 Sink组件上,而每个 Sink 组件分别连接到一个独立的 Agent 上。
2.示例配置如下所示:
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2 k3
a1.sinkgroups.g1.processor.type = load_balance # 表示采用的是负载均衡
a1.sinkgroups.g1.processor.backoff = true # 如果开启,则将失败的 sink 放入黑名单
a1.sinkgroups.g1.processor.selector = round_robin # round_robin 表示轮询访问负载均衡的其中一台Agent。
# 另外还支持 random,表示随机 访问负载均衡的其中一台Agent
a1.sinkgroups.g1.processor.selector.maxTimeOut=10000 # 在黑名单放置的超时时间,超时结束时,若仍然无法接收,则超时时间呈指数增长 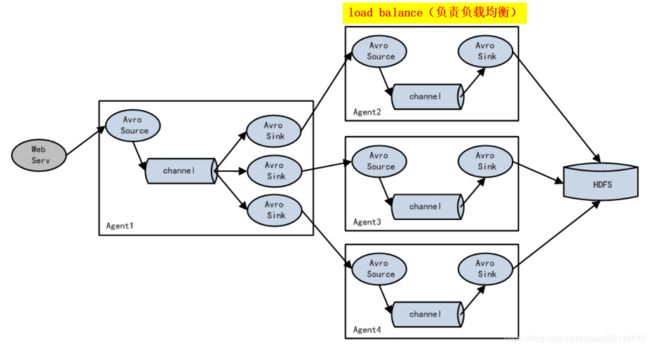
2.Failover Sink Processor:
(负责容错:在容错机制下,负载均衡集群中只有一台Flume在接收Event信息,只有当这一台Flume挂掉之后,才会继续由其他下一个Flume接收Event信息)
1.Failover Sink Processor 能够实现 failover 功能,具体流程类似 load balance,但是内部处理机制与 load balance 完全不同。
2.Failover Sink Processor 维护一个优先级 Sink 组件列表, 只要有一个 Sink组件可用, Event 就被传递到下一个组件。
3.故障转移机制的作用是将失败的 Sink降级到一个池,在这些池中它们被分配一个冷却时间,随着故障的连续,在重试之前冷却时间增加。
4.一旦 Sink 成功发送一个事件,它将恢复到活动池。Sink 具有与之相关的优先级,数量越大,优先级越高。
5.例如,具有优先级为 100 的 sink 在优先级为 80 的 Sink 之前被激活。如果在发送事件时汇聚失败,
则接下来将尝试下一个具有最高优先级的 Sink 发送事件。如果没有指定优先级,则根据在配置中指定 Sink 的顺序来确定优先级。
6.示例配置如下所示:
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2 k3
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5 #优先级值, 绝对值越大表示优先级越高
a1.sinkgroups.g1.processor.priority.k2 = 7
a1.sinkgroups.g1.processor.priority.k3 = 6
a1.sinkgroups.g1.processor.maxpenalty = 20000 #失败的 Sink 的最大回退期(millis)
============ Flume 的 load balance(负责负载均衡) =============
load balance:负责负载均衡,在负载均衡机制下的每台Flume 可通过轮询或随机的方式 接收Event信息
搭建 Flume 的 load balance负载均衡 的步骤:
1.3台linux部署 Flume:
把第一台Linux下的Flume推送到第二台、第三台的Linux下
scp -r /root/flume root@NODE2:/root
scp -r /root/flume root@NODE3:/root
2.在/root/flume/conf目录下 创建“第一台Linux下的Flume的”配置采集方案 exec-avro.conf
cd /root/flume/conf
vim exec-avro.conf:
#agent1 name
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2 # 由其他两个Flume 建立负载均衡
#set gruop
agent1.sinkgroups = g1
#set channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
agent1.sources.r1.channels = c1
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /root/logs/test.log # 监控的文件是 /root/logs/test.log
# 配置连接 负载均衡中的 第一台Flume
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = NODE2 # 负载均衡中的 第一台Flume 所在的Linux的主机名
agent1.sinks.k1.port = 52020
# 配置连接 负载均衡中的 第二台Flume
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = NODE3 # 负载均衡中的 第二台Flume 所在的Linux的主机名
agent1.sinks.k2.port = 52020
#set sink group
agent1.sinkgroups.g1.sinks = k1 k2
#set failover
agent1.sinkgroups.g1.processor.type = load_balance # 表示采用的是负载均衡
agent1.sinkgroups.g1.processor.backoff = true
agent1.sinkgroups.g1.processor.selector = round_robin # round_robin 表示轮询访问负载均衡的其中一台Agent。
agent1.sinkgroups.g1.processor.selector.maxTimeOut=10000
3.在第二台Linux下的 /root/flume/conf目录下 创建“负载均衡中的第一台Flume的”配置采集方案 avro-logger.conf
cd /root/flume/conf
vim avro-logger.conf:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0 # 可以绑定具体的本机地址 或 0.0.0.0,但不能使用 localhost
a1.sources.r1.port = 52020 # 监听的52020端口上是否有数据传输
# 描述和配置 sink 组件:k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/tailout/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是 Sequencefile,可用 DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
4.在第三台Linux下的 /root/flume/conf目录下 创建“负载均衡中的第二台Flume的”配置采集方案 avro-logger.conf
cd /root/flume/conf
vim avro-logger.conf:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0 # 可以绑定具体的本机地址 或 0.0.0.0,但不能使用 localhost
a1.sources.r1.port = 52020 # 监听的52020端口上是否有数据传输
# 描述和配置 sink 组件:k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/tailout/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是 Sequencefile,可用 DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
5.首先启动负载均衡中的每台Flume,然后最后才启动第一台Linux下的Flume。
第一台Linux下的Flume 负责监听/root/logs/test.log文件是否有新数据,test.log文件出现新数据的话,
Flume便通过通过轮询的方式 负责把 test.log文件出现新数据 分发给负载均衡中的各台Flume。
6.启动 负载均衡中的 每台Flume:
1.cd /root/flume
2.chmod 777 flume-ng
3.启动命令: bin/flume-ng agent -c conf/ -f conf/avro-logger.conf -n a1 -Dflume.root.logger=INFO,console
-c conf 或 --conf conf:指定 flume 框架自带的配置文件所在目录名
-f conf/xxx.conf 或 --conf-file conf/xxx.conf:指定我们所自定义创建的采集方案为conf目录下的xxx.conf
-name agent的名字:指定我们这个agent 的名字
启动的最后会显示:Avro source r1 started
4.注意:
此处之所以只执行“cd /root/flume”,而不是执行“cd /root/flume/bin”,是因为启动命令中要指定的是以当前路径为开始找配置文件,
比如 “--conf conf/” 表示以 “/root/flume”的当前路径找到“conf/”。
比如“--conf-file conf/netcat-logger.conf”表示以 “/root/flume”的当前路径找到“conf目录下的netcat-logger.conf”。
7.启动 第一台Linux下的Flume:
1.cd /root/flume
2.chmod 777 flume-ng
3.启动命令: bin/flume-ng agent -c conf/ -f conf/exec-avro.conf -n agent1 -Dflume.root.logger=INFO,console
-c conf 或 --conf conf:指定 flume 框架自带的配置文件所在目录名
-f conf/xxx.conf 或 --conf-file conf/xxx.conf:指定我们所自定义创建的采集方案为conf目录下的xxx.conf
-name agent的名字:指定我们这个agent 的名字
第一台Linux下的Flume 启动的最后会显示:Rpc sink k1 started 和 Rpc sink k2 started
负载均衡中的 每台Flume 接着会显示:CONNECTED: /192.168.25.100:59705
4.注意:
此处之所以只执行“cd /root/flume”,而不是执行“cd /root/flume/bin”,是因为启动命令中要指定的是以当前路径为开始找配置文件,
比如 “--conf conf/” 表示以 “/root/flume”的当前路径找到“conf/”。
比如“--conf-file conf/netcat-logger.conf”表示以 “/root/flume”的当前路径找到“conf目录下的netcat-logger.conf”。
8.测试是否成功:
在第一台Linux下 执行 while true ; do echo 'access access....' >>/root/logs/test.log;sleep 0.5;done 便可不断往 /root/logs/目录下的test.log存储数据,
那么flume便能监听到“tail -F /root/logs/test.log”动态打印的信息,然后通过轮询的方式 负责把 test.log文件出现新数据 分发给负载均衡中的各台Flume。
访问http://node1:50070/ 便能查看到如下信息,自动创建多了一个/flume/tailout/目录用于存储数据

================failover(负责容错) ==================
failover:负责容错,在容错机制下,负载均衡集群中只有一台Flume在接收Event信息,只有当这一台Flume挂掉之后,才会继续由其他下一个Flume接收Event信息)
搭建 Flume 的 load balance负载均衡 的步骤:
1.3台linux部署 Flume:
把第一台Linux下的Flume推送到第二台、第三台的Linux下
scp -r /root/flume root@NODE2:/root
scp -r /root/flume root@NODE3:/root
2.在/root/flume/conf目录下 创建“第一台Linux下的Flume的”配置采集方案 exec-avro1.conf
cd /root/flume/conf
vim exec-avro1.conf:
#agent1 name
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2 # 由其他两个Flume 建立负载均衡
#set gruop
agent1.sinkgroups = g1
#set channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
agent1.sources.r1.channels = c1
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /root/logs/test.log # 监控的文件是 /root/logs/test.log
# 配置连接 负载均衡中的 第一台Flume
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = NODE2 # 负载均衡中的 第一台Flume 所在的Linux的主机名
agent1.sinks.k1.port = 52020
# 配置连接 负载均衡中的 第二台Flume
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = NODE3 # 负载均衡中的 第二台Flume 所在的Linux的主机名
agent1.sinks.k2.port = 52020
#set sink group
agent1.sinkgroups.g1.sinks = k1 k2
#set failover
agent1.sinkgroups.g1.processor.type = failover # 表示 容错机制
agent1.sinkgroups.g1.processor.priority.k1 = 10 # 优先级值, 绝对值越大表示优先级越高
agent1.sinkgroups.g1.processor.priority.k2 = 1
agent1.sinkgroups.g1.processor.maxpenalty = 10000
3.在第二台Linux下的 /root/flume/conf目录下 创建“负载均衡中的第一台Flume的”配置采集方案 avro-logger1.conf
cd /root/flume/conf
vim avro-logger1.conf:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0 # 可以绑定具体的本机地址 或 0.0.0.0,但不能使用 localhost
a1.sources.r1.port = 52020 # 监听的52020端口上是否有数据传输
# 描述和配置 sink 组件:k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/tailout/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是 Sequencefile,可用 DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
4.在第三台Linux下的 /root/flume/conf目录下 创建“负载均衡中的第二台Flume的”配置采集方案 avro-logger1.conf
cd /root/flume/conf
vim avro-logger1.conf:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0 # 可以绑定具体的本机地址 或 0.0.0.0,但不能使用 localhost
a1.sources.r1.port = 52020 # 监听的52020端口上是否有数据传输
# 描述和配置 sink 组件:k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/tailout/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是 Sequencefile,可用 DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
5.首先启动负载均衡中的每台Flume,然后最后才启动第一台Linux下的Flume。
第一台Linux下的Flume 负责监听/root/logs/test.log文件是否有新数据,test.log文件出现新数据的话,
Flume便通过通过轮询的方式 负责把 test.log文件出现新数据 分发给负载均衡中的各台Flume。
6.启动 负载均衡中的 每台Flume:
1.cd /root/flume
2.chmod 777 flume-ng
3.启动命令: bin/flume-ng agent -c conf/ -f conf/avro-logger1.conf -n a1 -Dflume.root.logger=INFO,console
-c conf 或 --conf conf:指定 flume 框架自带的配置文件所在目录名
-f conf/xxx.conf 或 --conf-file conf/xxx.conf:指定我们所自定义创建的采集方案为conf目录下的xxx.conf
-name agent的名字:指定我们这个agent 的名字
启动的最后会显示:Avro source r1 started
4.注意:
此处之所以只执行“cd /root/flume”,而不是执行“cd /root/flume/bin”,是因为启动命令中要指定的是以当前路径为开始找配置文件,
比如 “--conf conf/” 表示以 “/root/flume”的当前路径找到“conf/”。
比如“--conf-file conf/netcat-logger.conf”表示以 “/root/flume”的当前路径找到“conf目录下的netcat-logger.conf”。
7.启动 第一台Linux下的Flume:
1.cd /root/flume
2.chmod 777 flume-ng
3.启动命令: bin/flume-ng agent -c conf/ -f conf/exec-avro1.conf -n agent1 -Dflume.root.logger=INFO,console
-c conf 或 --conf conf:指定 flume 框架自带的配置文件所在目录名
-f conf/xxx.conf 或 --conf-file conf/xxx.conf:指定我们所自定义创建的采集方案为conf目录下的xxx.conf
-name agent的名字:指定我们这个agent 的名字
第一台Linux下的Flume 启动的最后会显示:Rpc sink k1 started 和 Rpc sink k2 started
负载均衡中的 每台Flume 接着会显示:CONNECTED: /192.168.25.100:59705
4.注意:
此处之所以只执行“cd /root/flume”,而不是执行“cd /root/flume/bin”,是因为启动命令中要指定的是以当前路径为开始找配置文件,
比如 “--conf conf/” 表示以 “/root/flume”的当前路径找到“conf/”。
比如“--conf-file conf/netcat-logger.conf”表示以 “/root/flume”的当前路径找到“conf目录下的netcat-logger.conf”。
8.测试是否成功:
在第一台Linux下 执行 while true ; do echo 'access access....' >>/root/logs/test.log;sleep 0.5;done 便可不断往 /root/logs/目录下的test.log存储数据,
那么flume便能监听到“tail -F /root/logs/test.log”动态打印的信息,然后通过轮询的方式 负责把 test.log文件出现新数据 分发给负载均衡中的各台Flume。
访问http://node1:50070/ 便能查看到如下信息,自动创建多了一个/flume/tailout/目录用于存储数据
=============== Flume 实战案例 ====================
1.日志的采集和汇总
1.案例场景
1.A、B 两台日志服务机器实时生产日志主要类型为 access.log、nginx.log、web.log
2.现在要求:
把 A、B 机器中的 access.log、nginx.log、web.log 采集汇总到 C 机器上 然后统一收集到 hdfs 中。
但是在 hdfs 中要求的目录为:
/source/logs/access/20160101/**
/source/logs/nginx/20160101/**
/source/logs/web/20160101/** 2.场景分析
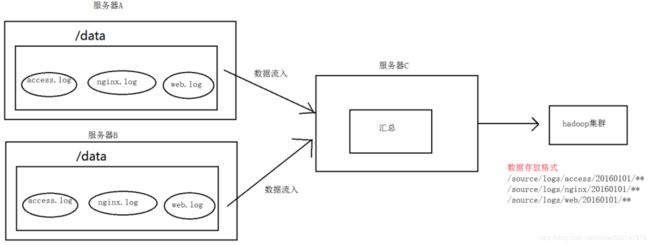
3.数据流程处理分析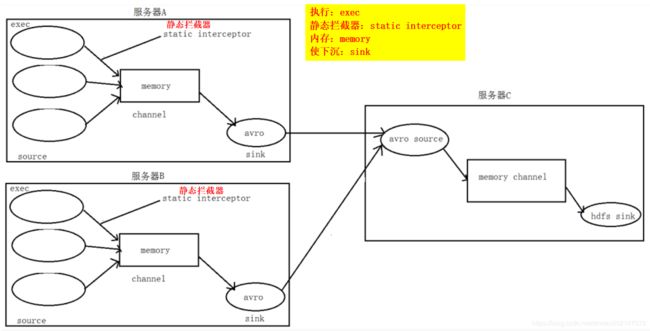
4.功能实现
1.在服务器 A 和服务器 B 上 创建配置文件 exec_source_avro_sink.conf
# 定义这个 agent 中各组件的名字
a1.sources = r1 r2 r3
a1.sinks = k1
a1.channels = c1
# 描述和配置 source 组件:r1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/logs/access.log # 监控的文件是 /root/logs/access.log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static # 表示配置 静态拦截器 static interceptor
# 静态拦截器 static interceptor的功能就是往采集到的数据中 添加header头信息:插入自己定义的 key-value对信息到header头信息
# 可以使用 %{key属性的值} 获取出 value属性的值
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = access
a1.sources.r2.type = exec
a1.sources.r2.command = tail -F /root/logs/nginx.log # 监控的文件是 /root/logs/nginx.log
a1.sources.r2.interceptors = i2
a1.sources.r2.interceptors.i2.type = static # 表示配置 静态拦截器 static interceptor
# 静态拦截器 static interceptor的功能就是往采集到的数据中 添加header头信息:插入自己定义的 key-value对信息到header头信息
# 可以使用 %{key属性的值} 获取出 value属性的值
a1.sources.r2.interceptors.i2.key = type
a1.sources.r2.interceptors.i2.value = nginx
a1.sources.r3.type = exec
a1.sources.r3.command = tail -F /root/logs/web.log # 监控的文件是 /root/logs/web.log
a1.sources.r3.interceptors = i3
a1.sources.r3.interceptors.i3.type = static # 表示配置 静态拦截器 static interceptor
# 静态拦截器 static interceptor的功能就是往采集到的数据中 添加header头信息:插入自己定义的 key-value对信息到header头信息
# 可以使用 %{key属性的值} 获取出 value属性的值
a1.sources.r3.interceptors.i3.key = type
a1.sources.r3.interceptors.i3.value = web
# 描述和配置 sinks 组件:k1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 负责汇总数据的服务器C的IP地址或主机名
a1.sinks.k1.port = 41414
# 描述和配置 channels 组件c1,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity = 10000
# 描述和配置 source、channel、sink 之间的连接关系
a1.sources.r1.channels = c1
a1.sources.r2.channels = c1
a1.sources.r3.channels = c1
a1.sinks.k1.channel = c1
2.在服务器 C 上创建配置文件 avro_source_hdfs_sink.conf 文件内容为
#定义 agent 名, source、channel、sink 的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置 source 组件:r1
a1.sources.r1.type = avro
a1.sources.r1.bind = 绑定当前“负责汇总数据的服务器C的”IP地址或主机名
a1.sources.r1.port =41414
#添加时间拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
# 描述和配置 channels 组件c1,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity = 10000
# 描述和配置 sinks 组件:k1
a1.sinks.k1.type = hdfs
# 可以使用 %{key属性的值} 获取出 value属性的值
# NODE1:9000 表示hdfs集群所在Linux的IP地址和端口。/source/logs/%{type} 为存储目录,%Y%m%d为文件名
a1.sinks.k1.hdfs.path=hdfs://NODE1:9000/source/logs/%{type}/%Y%m%d
a1.sinks.k1.hdfs.filePrefix =events
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
#时间类型
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件不按条数生成
a1.sinks.k1.hdfs.rollCount = 0
#生成的文件按时间生成
a1.sinks.k1.hdfs.rollInterval = 30
#生成的文件按大小生成
a1.sinks.k1.hdfs.rollSize = 10485760
#批量写入 hdfs 的个数
a1.sinks.k1.hdfs.batchSize = 10000
#flume 操作 hdfs 的线程数(包括新建,写入等)
a1.sinks.k1.hdfs.threadsPoolSize=10
#操作 hdfs 超时时间
a1.sinks.k1.hdfs.callTimeout=30000
#组装 source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channels = c1
3.配置完成之后,在服务器 A 和 B 上的/root/data 有数据文件 access.log、nginx.log、web.log。
1.先启动服务器 C 上的 flume,启动命令 在 flume 安装目录下执行:
bin/flume-ng agent -c conf -f conf/avro_source_hdfs_sink.conf -name a1 -Dflume.root.logger=DEBUG,console
2.然后在启动服务器上的 A 和 B,启动命令 在 flume 安装目录下执行:
bin/flume-ng agent -c conf -f conf/exec_source_avro_sink.conf -name a1 -Dflume.root.logger=DEBUG,console
3.参数:
-c conf:指定 flume 自身的配置文件所在目录
-f conf/avro_source_hdfs_sink.conf、-f conf/exec_source_avro_sink.conf:指定我们所描述的采集方案
-name a1:指定我们这个agent 的名字
===============Flume 自定义拦截器==============
1.案例背景介绍
1.Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据;
2.同时,Flume 提供对数据进行简单处理,并写到各种数据接收方(可定制)的能力。
3.Flume 有各种自带的拦截器,比如:TimestampInterceptor、HostInterceptor、RegexExtractorInterceptor 等,通过使用不同的拦截器,
实现不同的功能。但是以上的这些拦截器,不能改变原有日志数据的内容或者对日志信息添加一定的处理逻辑,
当一条日志信息有几十个甚至上百个字段的时候,在传统的 Flume 处理下,收集到的日志还是会有对应这么多的字段,也不能对你想要的字段进行对应的处理。
2.自定义拦截器
根据实际业务的需求,为了更好的满足数据在应用层的处理,通过自定义 Flume 拦截器,过滤掉不需要的字段,并对指定字段加密处理,
将源数据进行预处理。减少了数据的传输量,降低了存储的开销。
3.功能实现
本技术方案核心包括二部分:
1.编写 java 代码,自定义拦截器 内容包括:
1.定义一个类 CustomParameterInterceptor 实现 Interceptor 接口。
2.在 CustomParameterInterceptor 类中定义变量,这些变量是需要到 Flume 的配置文件中进行配置使用的。
每一行字段间的分隔符(fields_separator)、通过分隔符分隔后,所需要列字段的下标(indexs) 、多个下标使用的分隔符(indexs_separator)、
多个下标使用的分隔符(indexs_separator)。
3.添加 CustomParameterInterceptor 的有参构造方法。并对相应的变量进行处理。将配置文件中传过来的 unicode 编码进行转换为字符串。
4.写具体的要处理的逻辑 intercept()方法,一个是单个处理的,一个是批量处理。
5.接口中定义了一个内部接口 Builder,在 configure 方法中,进行一些参数配置。
并给出,在 flume 的 conf 中没配置一些参数时,给出其默认值。通过其 builder 方法,返回一个 CustomParameterInterceptor 对象。
6.定义一个静态类,类中封装 MD5 加密方法
7.通过以上步骤,自定义拦截器的代码开发已完成,然后打包成 jar, 放到 Flume 的根目录下的 lib 中
2.修改 Flume 的配置信息
新增配置文件 spool-interceptor-hdfs.conf,内容为:
a1.channels = c1
a1.sources = r1
a1.sinks = s1
#channel
a1.channels.c1.type = memory
a1.channels.c1.capacity=100000
a1.channels.c1.transactionCapacity=50000
#source
a1.sources.r1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/data/
a1.sources.r1.batchSize= 50
a1.sources.r1.inputCharset = UTF-8
# 定义了 i1 和 i2 两个 静态拦截器
a1.sources.r1.interceptors =i1 i2
# i1静态拦截器:会执行CustomParameterInterceptor自定义类中的静态内部类Builder
a1.sources.r1.interceptors.i1.type = cn.itcast.interceptor.CustomParameterInterceptor$Builder
a1.sources.r1.interceptors.i1.fields_separator=\\u0009 # 字段的分隔符,指明每一行字段的分隔符
a1.sources.r1.interceptors.i1.indexs =0,1,3,5,6 # 索引,通过分隔符分割后,指明需要那列的字段的下标
a1.sources.r1.interceptors.i1.indexs_separator =\\u002c # 索引的分隔符,多个下标的分隔符
a1.sources.r1.interceptors.i1.encrypted_field_index =0 # 加密的字段,需要加密的字段下标
# i2静态拦截器:会执行TimestampInterceptor自定义类中的静态内部类Builder
a1.sources.r1.interceptors.i2.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#sink
a1.sinks.s1.channel = c1
a1.sinks.s1.type = hdfs
a1.sinks.s1.hdfs.path =hdfs://192.168.200.101:9000/flume/%Y%m%d
a1.sinks.s1.hdfs.filePrefix = event
a1.sinks.s1.hdfs.fileSuffix = .log
a1.sinks.s1.hdfs.rollSize = 10485760
a1.sinks.s1.hdfs.rollInterval =20
a1.sinks.s1.hdfs.rollCount = 0
a1.sinks.s1.hdfs.batchSize = 1500
a1.sinks.s1.hdfs.round = true
a1.sinks.s1.hdfs.roundUnit = minute
a1.sinks.s1.hdfs.threadsPoolSize = 25
a1.sinks.s1.hdfs.useLocalTimeStamp = true
a1.sinks.s1.hdfs.minBlockReplicas = 1
a1.sinks.s1.hdfs.fileType =DataStream
a1.sinks.s1.hdfs.writeFormat = Text
a1.sinks.s1.hdfs.callTimeout = 60000
a1.sinks.s1.hdfs.idleTimeout =60
启动:bin/flume-ng agent -c conf -f conf/spool-interceptor-hdfs.conf -name a1 -Dflume.root.logger=DEBUG,console
======= Apache Flume--实战案例--采集日志汇总 & 静态拦截器使用 =========

采集日志汇总 & 拦截器使用的搭建:
1.在服务器 A 和服务器 B 上 创建采集方案的配置文件 exec_source_avro_sink.conf (此处只模拟在第一台Linux下配置采集方案exec_source_avro_sink.conf)
cd /root/flume/conf
vim exec_source_avro_sink.conf:
# Name the components on this agent
a1.sources = r1 r2 r3
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/logs/access.log # 监控的文件是 /root/logs/access.log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static# 表示配置 静态拦截器 static interceptor
# 静态拦截器 static interceptor的功能就是往采集到的数据中 添加header头信息:插入自己定义的 key-value对信息到header头信息
# 可以使用 %{key属性的值} 获取出 value属性的值
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = access
a1.sources.r2.type = exec
a1.sources.r2.command = tail -F /root/logs/nginx.log # 监控的文件是 /root/logs/nginx.log
a1.sources.r2.interceptors = i2
a1.sources.r2.interceptors.i2.type = static# 表示配置 静态拦截器 static interceptor
# 静态拦截器 static interceptor的功能就是往采集到的数据中 添加header头信息:插入自己定义的 key-value对信息到header头信息
# 可以使用 %{key属性的值} 获取出 value属性的值
a1.sources.r2.interceptors.i2.key = type
a1.sources.r2.interceptors.i2.value = nginx
a1.sources.r3.type = exec
a1.sources.r3.command = tail -F /root/logs/web.log # 监控的文件是 /root/logs/web.log
a1.sources.r3.interceptors = i3
a1.sources.r3.interceptors.i3.type = static# 表示配置 静态拦截器 static interceptor
# 静态拦截器 static interceptor的功能就是往采集到的数据中 添加header头信息:插入自己定义的 key-value对信息到header头信息
# 可以使用 %{key属性的值} 获取出 value属性的值
a1.sources.r3.interceptors.i3.key = type
a1.sources.r3.interceptors.i3.value = web
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = NODE2 # 负责汇总数据的服务器C的IP地址或主机名
a1.sinks.k1.port = 41414
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 2000000
a1.channels.c1.transactionCapacity = 100000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sources.r2.channels = c1
a1.sources.r3.channels = c1
a1.sinks.k1.channel = c1
2.在服务器 C 上创建配置文件 avro_source_hdfs_sink.conf 文件内容为(此处只模拟在第二台Linux下配置采集方案avro_source_hdfs_sink.conf)
cd /root/flume/conf
vim avro_source_hdfs_sink.conf:
#定义agent名, source、channel、sink的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#定义source
a1.sources.r1.type = avro
# 绑定当前“负责汇总数据的服务器C的”IP地址或主机名
a1.sources.r1.bind = 0.0.0.0 # 可以绑定具体的本机地址 或 0.0.0.0,但不能使用 localhost
a1.sources.r1.port =41414
#添加时间拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#定义channels
a1.channels.c1.type = memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity = 10000
#定义sink
a1.sinks.k1.type = hdfs
# 可以使用 %{key属性的值} 获取出 value属性的值
# NODE1:9000 表示hdfs集群所在Linux的IP地址和端口。/source/logs/%{type} 为存储目录,%Y%m%d为文件名
a1.sinks.k1.hdfs.path=hdfs://NODE1:9000/source/logs/%{type}/%Y%m%d
a1.sinks.k1.hdfs.filePrefix =events
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
#时间类型
#a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件不按条数生成
a1.sinks.k1.hdfs.rollCount = 0
#生成的文件不按时间生成
a1.sinks.k1.hdfs.rollInterval = 30
#生成的文件按大小生成
a1.sinks.k1.hdfs.rollSize = 10485760
#a1.sinks.k1.hdfs.rollSize =0
# 批量写入hdfs的个数
a1.sinks.k1.hdfs.batchSize = 20
# flume操作hdfs的线程数(包括新建,写入等)
a1.sinks.k1.hdfs.threadsPoolSize=10
#操作hdfs超时时间
a1.sinks.k1.hdfs.callTimeout=30000
#组装source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3.配置完成之后,在服务器 A 和 B 上的/root/data 有数据文件 access.log、nginx.log、web.log。
1.先启动服务器 C 上的 flume,启动命令 在 flume 安装目录下执行:
1.cd /root/flume
2.chmod 777 flume-ng
3.启动命令:bin/flume-ng agent -c conf -f conf/avro_source_hdfs_sink.conf -name a1 -Dflume.root.logger=DEBUG,console
4.启动后最后显示的打印信息:Avro source r1 started
2.然后在启动服务器上的 A 和 B,启动命令 在 flume 安装目录下执行:
1.cd /root/flume
2.chmod 777 flume-ng
3.启动命令:bin/flume-ng agent -c conf -f conf/exec_source_avro_sink.conf -name a1 -Dflume.root.logger=DEBUG,console
4.启动后最后显示的打印信息:Polling sink runner starting
3.启动命令中的参数:
-c conf:指定 flume 自身的配置文件所在目录
-f conf/avro_source_hdfs_sink.conf、-f conf/exec_source_avro_sink.conf:指定我们所描述的采集方案
-name a1:指定我们这个agent 的名字
4.测试是否搭建成功:
vim /root/logs/access.log 保存任意数据并退出
vim /root/logs/web.log 保存任意数据并退出
vim /root/logs/nginx.log 保存任意数据并退出
在第一台Linux下 执行 while true ; do echo 'access access....' >>/root/logs/access.log;sleep 0.5;done 便可不断往 /root/logs/目录下的access.log存储数据。
在第一台Linux下 执行 while true ; do echo 'web web....' >>/root/logs/web.log;sleep 0.5;done 便可不断往 /root/logs/目录下的web.log存储数据。
在第一台Linux下 执行 while true ; do echo 'nginx nginx....' >>/root/logs/nginx.log;sleep 0.5;done 便可不断往 /root/logs/目录下的nginx.log存储数据。
那么flume便能监听到“tail -F /root/logs/access.log、web.log、nginx.log文件”动态打印的信息,
然后通过轮询的方式 负责把 test.log、web.log、nginx.log文件出现新数据 分发给负载均衡中的各台Flume。
访问http://node1:50070/ 便能查看到如下信息,自动创建多了一个/source/logs/目录,该目录下还会有 access、web、nginx 三个目录 用于存储数据。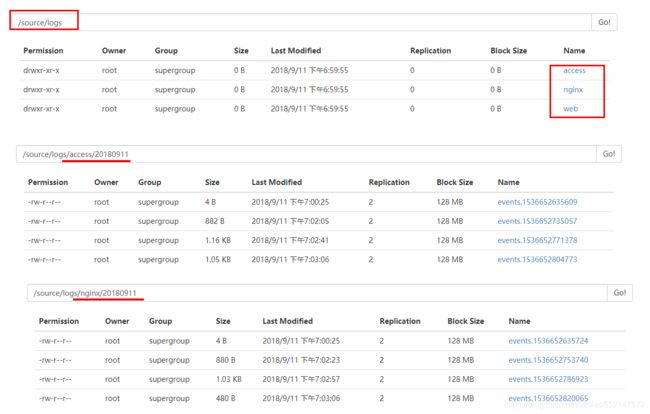

============Flume+Kafka 日志采集分析系统==============
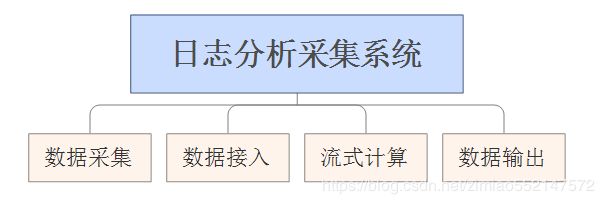
1.数据采集模块:负责从各节点上实时采集数据,建议选用Flume-NG来实现。
数据接入模块:由于采集数据的速度和数据处理的速度不一定同步,因此添加一个消息中间件来作为缓冲,建议选用Kafka来实现。
流式计算模块:对采集到的数据进行实时分析,建议选用Storm来实现。
数据输出模块:对分析后的结果持久化,可以使用HDFS、MySQL等。
日志采集选型小结
建议采用Flume作为数据的生产者,这样可以不用编程就实现数据源的引入,并采用Kafka Sink作为数据的消费者,
这样可以得到较高的吞吐量和可靠性。如果对数据的可靠性要求高的话,可以采用Kafka Channel来作为Flume的Channel使用。
Flume对接Kafka
Flume作为消息的生产者,将生产的消息数据(日志数据、业务请求数据等)通过Kafka Sink发布到Kafka中。
2.日志采集选型
大数据平台每天会产生大量的日志,处理这些日志需要特定的日志系统。目前常用的开源日志系统有 Flume 和 Kafka两种, 都是非常优秀的日志系统,且各有特点。
3.Flume组件特点
Flume是一个分布式、可靠、高可用的海量日志采集、聚合和传输的日志收集系统。支持在日志系统中定制各类数据发送方,用于收集数据;
同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
4.Flume的设计目标
1.可靠性
Flume的核心是把数据从数据源收集过来,再送到目的地。为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,
删除自己缓存的数据。Flume 使用事务性的方式保证传送Event整个过程的可靠性。
2.可扩展性
Flume中只有一个角色Agent,其中包含Source、Sink、Channel三种组件。一个Agent的Sink可以输出到另一个Agent的Source。
这样通过配置可以实现多个层次的流配置。
3.功能可扩展性
Flume自带丰富的Source、Sink、Channel实现。用户也可以根据需要添加自定义的组件实现, 并在配置中使用起来。
5.Flume的架构
Flume的基本架构是Agent。它是一个完整的数据收集工具,含有三个核心组件,分别是 Source、Channel、Sink。
数据以Event为基本单位经过Source、Channel、Sink,从外部数据源来,向外部的目的地去。



除了单Agent的架构外,还可以将多个Agent组合起来形成多层的数据流架构:
1.多个Agent顺序连接:
将多个Agent顺序连接起来,将最初的数据源经过收集,存储到最终的存储系统中。
一般情况下,应该控制这种顺序连接的Agent的数量,因为数据流经的路径变长了,如果不考虑Failover的话,出现故障将影响整个Flow上的Agent收集服务。
2.多个Agent的数据汇聚到同一个Agent:
这种情况应用的场景比较多,适用于数据源分散的分布式系统中数据流汇总。

3.多路(Multiplexing)Agent:
多路模式一般有两种实现方式,一种是用来复制,另一种是用来分流。复制方式可以将最前端的数据源复制多份,分别传递到多个Channel中,
每个Channel接收到的数据都是相同的。分流方式,Selector可以根据Header的值来确定数据传递到哪一个Channel。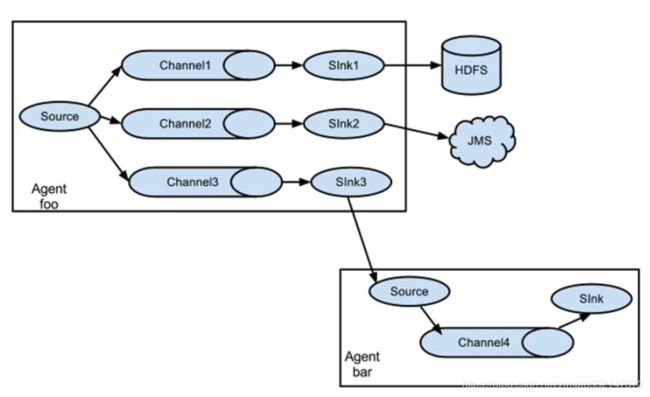
4.实现Load Balance功能:
Channel中Event可以均衡到对应的多个Sink组件上,而每个Sink组件再分别连接到一个独立的Agent上,这样可以实现负载均衡。
1.Kafka组件特点
kafka实际上是一个消息发布订阅系统。Producer向某个Topic发布消息,而Consumer订阅某个Topic的消息。
一旦有新的关于某个Topic的消息,Broker会传递给订阅它的所有Consumer。
2.Kafka的设计目标
1.数据在磁盘上的存取代价为O(1)
Kafka以Topic来进行消息管理,每个Topic包含多个Partition,每个Partition对应一个逻辑log,由多个Segment组成。
每个Segment中存储多条消息。消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。
2.为发布和订阅提供高吞吐量
Kafka每秒可以生产约25万消息(50 MB),每秒处理55万消息(110 MB)。
3.分布式系统,易于向外扩展
所有的Producer、Broker(Kafka主体)和Consumer都会有多个,均为分布式的。无需停机即可扩展机器。
3.Kafka的架构
Kafka是一个分布式的、可分区的、可复制的消息系统,维护消息队列。
Kafka的整体架构非常简单,是显式分布式架构,Producer、Broker(Kafka主体)和Consumer都可以有多个。
Producer,consumer实现Kafka注册的接口,数据从Producer发送到Broker(Kafka主体),
Broker(Kafka主体)承担一个中间缓存和分发的作用。Broker(Kafka主体)分发注册到系统中的Consumer。
Broker(Kafka主体)的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存。客户端和服务器端的通信,是基于简单、高性能、且与编程语言无关的TCP协议。


Flume与Kafka的比较
Flume和Kafka都是优秀的日志系统,其都能实现数据采集、数据传输、负载均衡、容错等一系列的需求,但是两者之间还是有着一定的差别。
由此可见Flume和Kafka还是各有特点的:
Flume 适用于没有编程的配置解决方案,由于提供了丰富的source、channel、sink实现,各种数据源的引入只是配置变更就可实现。
Kafka 适用于对数据管道的吞吐量、可用性要求都很高的解决方案,基本需要编程实现数据的生产和消费。



=========source 、channel和sink 多种组合===========
1.多sources - 多channel - 多sink ,每个sink 输出内容一致
1.memory channel 用于kafka操作,实时性高。file channel 用于 sink file 数据安全性高。
====================第一台Flume======================================
a1.sources = r1 r2 r3
a1.sinks = k1 k2
a1.channels = c1 c2
# 建立source 和 sink 连接到 channel
a1.sources.r1.channels = c1 c2
a1.sources.r2.channels = c1 c2
a1.sources.r3.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
# sources1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/logs/access.log # 监控的文件是 /root/logs/access.log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static# 表示配置 静态拦截器 static interceptor
# 静态拦截器 static interceptor的功能就是往采集到的数据中 添加header头信息:插入自己定义的 key-value对信息到header头信息
# 可以使用 %{key属性的值} 获取出 value属性的值
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = access
# sources2
a1.sources.r2.type = exec
a1.sources.r2.command = tail -F /root/logs/nginx.log # 监控的文件是 /root/logs/nginx.log
a1.sources.r2.interceptors = i2
a1.sources.r2.interceptors.i2.type = static# 表示配置 静态拦截器 static interceptor
# 静态拦截器 static interceptor的功能就是往采集到的数据中 添加header头信息:插入自己定义的 key-value对信息到header头信息
# 可以使用 %{key属性的值} 获取出 value属性的值
a1.sources.r2.interceptors.i2.key = type
a1.sources.r2.interceptors.i2.value = nginx
# sources3
a1.sources.r3.type = exec
a1.sources.r3.command = tail -F /root/logs/web.log # 监控的文件是 /root/logs/web.log
a1.sources.r3.interceptors = i3
a1.sources.r3.interceptors.i3.type = static# 表示配置 静态拦截器 static interceptor
# 静态拦截器 static interceptor的功能就是往采集到的数据中 添加header头信息:插入自己定义的 key-value对信息到header头信息
# 可以使用 %{key属性的值} 获取出 value属性的值
a1.sources.r3.interceptors.i3.key = type
a1.sources.r3.interceptors.i3.value = web
# channel1:kafka
a1.channels.c1.type = memory # 输出到内存,比如kafka、另外一台Flume
a1.channels.c1.capacity = 2000000
a1.channels.c1.transactionCapacity = 100000
#channel2:NODE2的Flume --> hdfs
a1.channels.c1.type = memory # 输出到内存,比如kafka、另外一台Flume
a1.channels.c1.capacity = 2000000
a1.channels.c1.transactionCapacity = 100000
#sink1:kafka
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink # 使用KafkaSink:指定把数据存储到Kafka的topic主题中
a1.sinks.k1.topic = log_monitor # topic = 主题名:表示把tail命令打印的信息(即xx.log新产生的信息)存储到指定的topic主题中
# broker中间者(kafka 集群中的一个kafka server)监听的端口 port=9092。此处配置 IP/主机名:9092端口
# 配置kafka集群中所有broker:brokerList = NODE1:9092,NODE2:9092,NODE3:9092 。 配置一台broker:brokerList = NODE1:9092
a1.sinks.k1.brokerList = NODE1:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
a1.sinks.k1.channel = c1
#sink2:NODE2的Flume --> hdfs
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = NODE2 # 负责汇总数据的服务器C的IP地址或主机名
a1.sinks.k2.port = 41414====================第二台Flume:NODE2的Flume --> hdfs======================================
#定义agent名, source、channel、sink的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#组装source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
#定义source
a1.sources.r1.type = avro
# 绑定当前“负责汇总数据的服务器C的”IP地址或主机名
a1.sources.r1.bind = 0.0.0.0 # 可以绑定具体的本机地址 或 0.0.0.0,但不能使用 localhost
a1.sources.r1.port =41414
#添加时间拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#定义channels
a1.channels.c1.type = memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity = 10000
#定义sink
a1.sinks.k1.type = hdfs
# 可以使用 %{key属性的值} 获取出 value属性的值
# NODE1:9000 表示hdfs集群所在Linux的IP地址和端口。/source/logs/%{type} 为存储目录,%Y%m%d为文件名
a1.sinks.k1.hdfs.path=hdfs://NODE1:9000/source/logs/%{type}/%Y%m%d
a1.sinks.k1.hdfs.filePrefix =events
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
#时间类型
#a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件不按条数生成
a1.sinks.k1.hdfs.rollCount = 0
#生成的文件不按时间生成
a1.sinks.k1.hdfs.rollInterval = 30
#生成的文件按大小生成
a1.sinks.k1.hdfs.rollSize = 10485760
#a1.sinks.k1.hdfs.rollSize =0
# 批量写入hdfs的个数
a1.sinks.k1.hdfs.batchSize = 20
# flume操作hdfs的线程数(包括新建,写入等)
a1.sinks.k1.hdfs.threadsPoolSize=10
#操作hdfs超时时间
a1.sinks.k1.hdfs.callTimeout=30000
1.多sink
集群(轮询):channel 的内容只输出一次,同一个event。如果sink1 输出,sink2 不输出;如果sink1 输出,sink1 不输出。 最终 sink1+sink2=channel 中的数据。
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.shell = /bin/bash -c
a1.sources.r1.channels = c1
a1.sources.r1.command = tail -F /opt/apps/logs/tail4.log
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#sink1
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = mytopic
a1.sinks.k1.kafka.bootstrap.servers = localhost:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.ki.kafka.producer.compression.type = snappy
#sink2
a1.sinks.k2.type = file_roll
a1.sinks.k2.channel = c1
#a1.sinks.k2.sink.rollInterval=0
a1.sinks.k2.sink.directory = /opt/apps/tmp
2.多 channel 多sink ,每个sink 输出内容一致
memory channel 用于kafka操作,实时性高。file channel 用于 sink file 数据安全性高。
多channel 单 sink 的情况没有举例,个人感觉用处不广泛。
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.shell = /bin/bash -c
a1.sources.r1.channels = c1 c2
a1.sources.r1.command = tail -F /opt/apps/logs/tail4.log
#多个channel 的数据相同
a1.sources.r1.selector.type=replicating
# channel1
a1.channels.c1.type = memory # 输出到内存,比如kafka
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#channel2
a1.channels.c2.type = file # 输出到文件系统,比如本地、hdfs
a1.channels.c2.checkpointDir = /opt/apps/flume-1.7.0/checkpoint
a1.channels.c2.dataDirs = /opt/apps/flume-1.7.0/data
#sink1
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = mytopic
a1.sinks.k1.kafka.bootstrap.servers = localhost:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.ki.kafka.producer.compression.type = snappy
#sink2
a1.sinks.k2.type = file_roll
a1.sinks.k2.channel = c2
#a1.sinks.k2.sink.rollInterval=0
a1.sinks.k2.sink.directory = /opt/apps/tmp
3.多source 单 channel 单 sink
多个source 可以读取多种信息放在一个channel 然后输出到同一个地方
a1.sources = r1 r2
a1.sinks = k1
a1.channels = c1
# source1
a1.sources.r1.type = exec
a1.sources.r1.shell = /bin/bash -c
a1.sources.r1.channels = c1
a1.sources.r1.command = tail -F /opt/apps/logs/tail4.log
# source2
a1.sources.r2.type = exec
a1.sources.r2.shell = /bin/bash -c
a1.sources.r2.channels = c1
a1.sources.r2.command = tail -F /opt/apps/logs/tail2.log
# channel1 in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#sink1
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = mytopic
a1.sinks.k1.kafka.bootstrap.servers = localhost:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.ki.kafka.producer.compression.type = snappy
==============Comparable、compareTo、Comparator==============
1.对数组、集合进行排序:
1.Arrays.sort(自定义类名类型的数组名)、Collections.sort(自定义类名类型的集合名)
2. Arrays.sort(new 自定义类名[len], new 自定义比较器类名MyComparator() )、
Collections.sort(List<自定义类名> list, new 自定义比较器类名MyComparator())
3. TreeSet<包装类型/String/自定义类名> set = new TreeSet<>():同样可以使用 implements Comparable/Comparator 进行排序
(详细看TreeSet知识点)
1.TreeSet<包装类/String类> set = new TreeSet<>():
因为 包装类/String类 都实现了 implements Comparable<包装类型/String> 接口,
并且 包装类/String类中 都重写了 compareTo 和 compare方法,
TreeSet都会对包装类/String类的数据 进行从小到大 的自然排序;
2.TreeSet<自定义类名类型> set = new TreeSet<>():
1.定义:class 自定义类 implements Comparable<自定义类名>;
2.自定义类中 重写 public int compareTo(自定义类名 obj) 方法进行自然排序;
3.TreeSet<自定义类名类型> set = new TreeSet<>(new 自定义比较器类名MyComparator()):
1.定义:class 自定义比较器类MyComparator implements Comparator<自定义类名> ;
2.class 自定义比较器类MyComparator中 重写 public int compare(自定义类名 obj1, 自定义类名 obj2) 进行定制排序 ;
2.compareTo:
1.对 自定义类名类型的数组/集合 中的元素(实例对象) 进行 比较排序;
Arrays.sort(自定义类名类型的数组名)、Collections.sort(自定义类名类型的集合名)、TreeSet<自定义类名> 都会调用
public int compareTo(自定义类名 obj) 进行比较;
2.在实现了 Comparable接口的 自定义类中 手动重写 Comparable接口中的 compareTo方法,compareTo方法中实现的 大小比较规则:
1.this调用者 和 实参传入者 进行比较 两者中的 同一实例属性的 基本数据类型/包装类型的 值的大小:
1.可以使用">" / "<" 进行比较;
比如:this.age > 实参传入者.age
2.从小到大排序:
1.第一种写法:
1.this.age > 实参传入者.age:return 1
2.this.age < 实参传入者.age:return -1
2.第二种写法:
this.age - 实参传入者.age:return 差值
3.从大到小排序:
1.第一种写法:
1.this.age > 实参传入者.age:return -1
2.this.age < 实参传入者.age:return 1
2.第二种写法:
this.age - 实参传入者.age:return 差值
2.this调用者 和 实参传入者 进行比较 两者中的 同一实例属性的 String字符串类型的 值的大小:
1.使用 this.实例属性名.compareTo(实参传入者.实例属性名) 进行比较;
比如:this.name.compareTo(实参传入者.name)
2.this.name.compareTo(实参传入者.name):
比较 两个实例对象中的 名字内容 String字符串字段值是否相同,调用String类中 重写了的 compareTo方法,
先判断两个字符串的长度,然后判断 两个字符串的中的 每个对应索引位上的中文字符是否相同,
实际就是把 两个 中文字符在 Unicode码表中的 数值 进行相减 判断;
3.从小到大排序:
1.第一种写法:
1.this.name.compareTo(实参传入者.name) < 0:return -1
2.this.name.compareTo(实参传入者.name) > 0:return 1
2.第二种写法:
this.name.compareTo(实参传入者.name):返回 差值
4.从大到小排序:
1.第一种写法:
1.this.name.compareTo(实参传入者.name) < 0:return 1
2.this.name.compareTo(实参传入者.name) > 0:return -1
2.第二种写法:
this.name.compareTo(实参传入者.name):返回 差值
3.例子:
class Person implements Comparable
{
private String name;
private int age;
//比较 调用者this 和 传入者nagisa 两个同类名类型的 实例对象,根据两个实例对象中的同名字段值 进行比较
public int compareTo(Person nagisa)
{
//-----------------------------------第一种写法-----------------------------------------
//比较 两个实例对象中的 年龄字段值 的大小
if (this.age > nagisa.age )
{
// 第一种:从小到大排序
return 1;
// 第二种:从大到小排序
return -1;
}
else if(this.age < nagisa.age )
{
// 第一种:从小到大排序
return -1;
// 第二种:从大到小排序
return 1;
}
//1.代码执行到这里,也就是this.age - nagisa.age等于0,也就是两个实例对象中的 年龄 int字段值 相同
//2.此处比较 两个实例对象中的 名字内容 String字符串字段值是否相同,调用String类中 重写了的 compareTo方法,
// 先判断两个字符串的长度,然后判断 两个字符串的中的 每个对应索引位上的中文字符是否相同,
// 实际就是把 两个 中文字符在 Unicode码表中的 数值 进行相减 判断
int nun1 = this.name.compareTo(nagisa.name);
if (nun1 != 0)
{
if(nun1<0)
{
// 第一种:从小到大排序
return -1;
// 第二种:从大到小排序
return 1;
}
if(nun1>0)
{
// 第一种:从小到大排序
return 1;
// 第二种:从大到小排序
return -1;
}
}
//代码执行到这里,意味着age、name都一样,即代表两个实例对象都相同
return 0;
//-----------------------------------第二种写法-----------------------------------------
//比较 两个实例对象中的 年龄字段值 的大小
int num1 = this.age - nagisa.age;
if (num1 != 0)
{
return num1;
}
//1.代码执行到这里,也就是this.age - nagisa.age等于0,也就是两个实例对象中的 年龄 int字段值 相同
//2.此处比较 两个实例对象中的 名字内容 String字符串字段值是否相同,调用String类中 重写了的 compareTo方法,
// 先判断两个字符串的长度,然后判断 两个字符串的中的 每个对应索引位上的中文字符是否相同,
// 实际就是把 两个 中文字符在 Unicode码表中的 数值 进行相减 判断
int num2 = this.name.compareTo(nagisa.name);
if (num2 != 0)
{
return num2;
}
//代码执行到这里,意味着age、name都一样,即代表两个实例对象都相同
return 0;
}
}
public static void main(String[] args)
{
//-------------------自定义类名类型的数组 中的 实例对象元素 进行排序---------------------------------------
Person[] arr = new Person[5];
arr[0] = new Person("lisi", 30);
arr[1] = new Person("lisi", 24);
arr[2] = new Person("zhangsan", 23);
arr[3] = new Person("langwu", 24);
arr[4] = new Person("langwu", 23);
System.out.println("排序前:"+Arrays.toString(arr));
//Arrays.sort(数组名) 调用 public int compareTo(Person obj) 进行比较
Arrays.sort(arr);
System.out.println("排序后:"+Arrays.toString(arr));
//-------------------自定义类名类型的集合 中的 实例对象元素 进行排序---------------------------------------
ArrayList list = new ArrayList();
list.add(new Person("lisi", 30));
list.add(new Person("lisi", 24));
list.add(new Person("zhangsan", 23));
list.add(new Person("langwu", 24));
list.add(new Person("langwu", 23));
System.out.println("排序前:"+list);
//Collections.sort(集合名)调用 public int compareTo(Person obj) 进行比较
Collections.sort(list);
System.out.println("排序后:"+list);
//-------------------TreeSet集合:自动对TreeSet集合中的 实例对象元素 进行排序---------------------------------------
//只要 TreeSet<自定义类名> 使用的 自定义类 实现了implements Comparable,
//并同时 自定义类中 重写了 compareTo方法为 public int compareTo(自定义类名 obj)
TreeSet set = new TreeSet<>()
set.add(new Person("ushio",17));
set.add(new Person("furu",17));
set.add(new Person("nagisa",18));
System.out.println("排序后:"+set );
}
3.Comparator:
1.对 自定义类名类型的数组/集合 中的元素(实例对象) 进行 比较排序;
Arrays.sort(new 自定义类名[len], new 自定义比较器类名MyComparator() )、
Collections.sort(List<自定义类名> list, new 自定义比较器类名MyComparator())、TreeSet<自定义类名>
都会调用 class MyComparator implements Comparator<自定义类名> 中的 public int compare(自定义类名 obj1, 自定义类名 obj2) 进行比较;
2.Arrays.sort(new 自定义类名[len], new 自定义比较器类名() ):public static void sort(T[] a, Comparator c)
1.对自定义类名名类型数组中的实例对象进行排序,则首先要求必须 定义一个 自定义比较器类,
该类 implements Comparator<自定义类名>,并在自定义比较器类中 重写compare方法;
2.例子:
Person[] arr = new Person[3];
Arrays.sort(arr, new MyComparator ());
class MyComparator implements Comparator
{
@Override
public int compare(Person p1, Person p2)
{
//比较规则
}
}
3.static void sort(List list, Comparator c) 根据指定比较器产生的顺序对指定列表进行排序。
1.Collections.sort(List<自定义类名> list, new MyComparator()):
首先定义 class MyComparator implements Comparator<自定义类名>,并在MyComparator自定义比较器类
中重写compare方法,在使用 Collections.sort 进行排序时,会根据MyComparator 类中的 compare方法
实现的排序规则 进行对 List集合 进行排序;
2.例子:
ArrayList list = new ArrayList<>()
Collections.sort(list, new MyComparator())
class MyComparator implements Comparator
{
@Override
public int compare(Person p1, Person p2)
{
//比较规则
}
}
4.例子:
class MyComparator implements Comparator
{
@Override
public int compare(Person p1, Person p2)
{
//比较 两个实例对象中的 年龄字段值 的大小
if (p1.age > p2.age )
{
// 第一种:从小到大排序
return 1;
// 第二种:从大到小排序
return -1;
}
else if(p1.age < p2.age )
{
// 第一种:从小到大排序
return -1;
// 第二种:从大到小排序
return 1;
}
//代码执行到这里,表明num1是等于0的,也就是this.age - o.age等于0,也就是说年龄是一样的
int nun1 = p1.name.compareTo(p2.name);
if (nun1 != 0)
{
if(nun1<0)
{
// 第一种:从小到大排序
return -1;
// 第二种:从大到小排序
return 1;
}
if(nun1>0)
{
// 第一种:从小到大排序
return 1;
// 第二种:从大到小排序
return -1;
}
}
//代码执行到这里,意味着age、name都一样,即代表两个实例对象都相同
return 0;
}
}