3d fully convolutional network for vehicle detection in point cloud
3d fully convolutional network for vehicle detection in point cloud
文章目录
- 3d fully convolutional network for vehicle detection in point cloud
- 方法介绍
- A. FCN Based Detection Revisited
- B. 3D FCN Detection Network for Point Cloud
- C. Comparison with 2D CNN
- 实验部分
本文是将2D的全卷积网络FCN引入到3D点云中,从而实现3D目标检测。
方法介绍
A. FCN Based Detection Revisited
基于检测框架的FCN的流程可以被分为两个任务:目标预测和Bboxd的回归。如下图所示,FCN 由两个分别对应于两个任务的输出组成。目标预测用于预测是否为目标,bbox预测则回归bbox的尺寸信息。
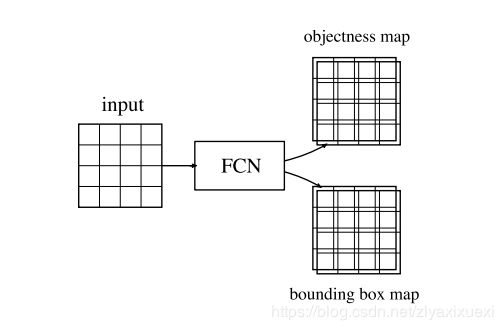
设 o P a o_P^a oPa为区域p的objectness map,可以用softmax 或者hinge loss编码。设 o P b o_P^b oPb为bounding box map的输出,可以用由边界框的坐标偏移编码。
设区域p的目标真实值标签为 l P \mathcal{l}_P lP.区域p对应的目标损失函数为:
L o b j ( p ) = − log ( p p ) p p = exp ( − o p , ℓ p a ) ∑ ℓ ∈ { 0 , 1 } exp ( − o p , ℓ a ) \begin{aligned} \mathcal{L}_{\mathrm{obj}}(\mathbf{p}) &=-\log \left(p_{\mathbf{p}}\right) \\ p_{\mathbf{p}} &=\frac{\exp \left(-\mathbf{o}_{\mathbf{p}, \ell_{\mathrm{p}}}^{a}\right)}{\sum_{\ell \in\{0,1\}} \exp \left(-\mathbf{o}_{\mathbf{p}, \ell}^{a}\right)} \end{aligned} Lobj(p)pp=−log(pp)=∑ℓ∈{0,1}exp(−op,ℓa)exp(−op,ℓpa)
设区域p的真实边界框的偏移量为 b p b_p bp。则每个边界框的损失函数被定义为:
L b o x ( p ) = ∥ o p b − b p ∥ 2 \mathcal{L}_{\mathrm{box}}(\mathbf{p})=\left\|\mathbf{o}_{\mathbf{p}}^{b}-\mathbf{b}_{\mathbf{p}}\right\|^{2} Lbox(p)=∥∥opb−bp∥∥2
因此整个网络总的损失函数被定义为:(其中w用于均衡目标损失函数和边界框损害函数)
L = ∑ p ∈ P L o b j ( p ) + w ∑ p ∈ V L b o x ( p ) \mathcal{L}=\sum_{\mathbf{p} \in \mathcal{P}} \mathcal{L}_{\mathrm{obj}}(\mathbf{p})+w \sum_{\mathbf{p} \in \mathcal{V}} \mathcal{L}_{\mathrm{box}}(\mathbf{p}) L=∑p∈PLobj(p)+w∑p∈VLbox(p)
P \mathcal P P代表objectness map所有的区域, V ∈ P \mathcal V \in \mathcal P V∈P表示所有的目标区域。在部署阶段,选择具有正目标预测的区域。然后收集与这些区域对应的边界框预测,并将其作为检测结果进行聚类。
B. 3D FCN Detection Network for Point Cloud
本文使用方形网格离散化点云。离散数据可以由具有长度、宽度、高度和通道尺寸的 4D 数组表示。对于最简单的情况,仅使用一个值 [0,1] 的通道来显示在相应的网格元素上是否观察到任何点。2D CNN机制可以很自然地拓展到3D网格中去。图2展示了本文使用方法的样例。

图2。 本文使用的3D FCN的一个简单样例。特征图首先通过卷积进行三次下采样。然后在进行上采样。每层之间进行ReLU。deconv4b对应着bounding box map,deconv4a则对应着objectness map。
与 DenseBox 类似,目标区域 V \mathcal V V代表目标的中心区域。对于建议的 3D 案例,使用位于对象中心的 3D 球体。球体内的点标记为正/前景标签。点 p 处的边界框预测由坐标偏移编码,定义为:( c p , ∗ c_{p,*} cp,∗代表边界框的八个角点)
Δ b p = ( c p , 1 ⊤ , c p , 2 ⊤ , … , c p , 8 ⊤ ) ⊤ − ( p ⊤ , … , p ⊤ ) \Delta \mathbf{b}_{\mathbf{p}}=\left(\mathbf{c}_{\mathbf{p}, 1}^{\top}, \mathbf{c}_{\mathbf{p}, 2}^{\top}, \ldots, \mathbf{c}_{\mathbf{p}, 8}^{\top}\right)^{\top}-\left(\mathbf{p}^{\top}, \ldots, \mathbf{p}^{\top}\right) Δbp=(cp,1⊤,cp,2⊤,…,cp,8⊤)⊤−(p⊤,…,p⊤)
3D CNN的训练和预测流程遵循着《 Vehicle detection from 3d lidar using fully convolutional network》。在测试阶段,候选边界框从预测为目标的区域中提取,并通过从所有候选边界框中计算其相邻值进行评分。边界框是从最高分中选择的,并且与所选框重叠的候选框将被抑制。
图 3 显示了检测中间结果的示例。来自目标点的边界框预测绘制为绿色框。请注意,对于严重遮挡的车辆,边界框形状会失真且为聚集。这主要是因为在训练阶段缺乏类似的样本。

图3. 3D FCN 检测过程的中间结果。(a) 边界框预测从具有高目标置信度的区域收集,并绘制为绿色框。(b) 使用蓝色原始点云绘制的聚类后的边界框。(c) 3D检测,因为(a)和(b)为鸟视图中的可视化。
C. Comparison with 2D CNN
与2D CNN相比,3D CNN的尺寸增量必然消耗更多的计算资源,这主要是由于 1)3D数据嵌入网格的内存成本增加,2)3D内核的仿真计算成本增加。
另一方面,在 3D 空间中自然嵌入目标可避免 2D 情况下的透视失真和比例变化。这使得使用相对简单的网络结构来学习检测成为可能。
实验部分
实验数据集:KITTI
本文使用的评价指标: bounding box overlap on the image plane (计算图像上的重叠面积)
这是 KITTI 基准的原始指标。3D 边界框检测投影回图像平面,投影的最小矩形外壳被视为 2D 边界框。3D 边界框检测以正交投影到 2D 接地平面上。如果与groundtruth的重叠区域 IoU 大于 0.7,则接受检测。此指标自然反映了自动驾驶系统的需求,其中车辆的垂直定位不如水平系统重要。
th的重叠区域 IoU 大于 0.7,则接受检测。此指标自然反映了自动驾驶系统的需求,其中车辆的垂直定位不如水平系统重要。
除了上述指标外,还评估了Average Precision (AP) 和 Average Orientation Similarity (AOS) 。