自动驾驶初体验之KITTI数据集----基于SSD框架的全过程
前言
自动驾驶的时代已然来临了,各个国家和有实力的研究机构争先恐后的开始了各种自动驾驶的研究与测试。我国的一线城市也相继出台了相关的政策法规来规范自动驾驶的进程。据我了解,我们国家做自动驾驶的企业以北京最多,其次是深圳与上海。大家都知道北京是IT产业的重镇,也盘踞着各类型的IT巨鳄。有的是想要做自动驾驶的生态系统,有的则想要在自动驾驶的某一专业领域深耕。真所谓八仙过海各显神通!
百度开源了Apollo自动驾驶框架,着力打造自动驾驶生态系统。这里面包括激光雷达、毫米波雷达、视觉、高精度地图等等模块。Apollo对于相应的地图、激光点云数据也进行了部份开源。我也花了一些时间研究过这个框架,感觉整个体系非常的庞大,非常值得借鉴。但是,百度的这一框架主要针对的是有一定实力,同时也愿意加入整个Apollo生态系统的企业。然而,对于个人用户来说构建和运行如此庞大的自动驾驶系统, 在人力与财力上肯定捉襟见肘。为此,作为一个在嵌入式、电子电路、自动控制、人工智能与模式识别方向上有一定积累的研发人员。除了在本人的博客中淺显的分析一下百度Apollo系统,与此同时更愿意在自动驾驶开源数据集KITTI上验证自己代码的可行性。毫不讳言的说,确实是自己没有足够的人力与财力来实测自动驾驶。所以,如果有朋友在自动驾驶这一方面感兴趣,同时与我一样苦于条件不足。那么请和我一起以最经济的方式开启自动驾驶之旅吧!!!
电脑配置
- 品牌: 惠普(HP)
- 商品名称:惠普暗影精灵III代
- 商品编号:6372549
- 商品毛重:4.9kg
- 商品产地:中国大陆
- 货号:3KS71PA
- 系统:Windows 10
- 分辨率:全高清屏(1920×1080)
- 厚度:20.0mm以上
- 内存容量:8G
- 显卡型号:GTX1060
- 游戏性能:吃鸡性能,发烧级,骨灰级
- 待机时长:5-7小时
- 处理器:Intel i7标准电压版
- 特性:背光键盘,其他
- 系列:惠普-暗影精灵
- 裸机重量:大于2.5KG
- 显卡类别:高性能游戏独立显卡 GTX1060
- 显存容量:6G
- 硬盘容量:128G+1T
- 屏幕尺寸:15.6英寸
准备工作
KITTI数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。用于评测目标(机动车、非机动车、行人等)检测、目标跟踪、路面分割等计算机视觉技术在车载环境下的性能。KITTI包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15辆车和30个行人,还有各种程度的遮挡(ps:欧洲道路状况和中国还是很不相同,期待国内早日能有同类数据集)。
进入官网,找到object一栏,准备下载数据集:
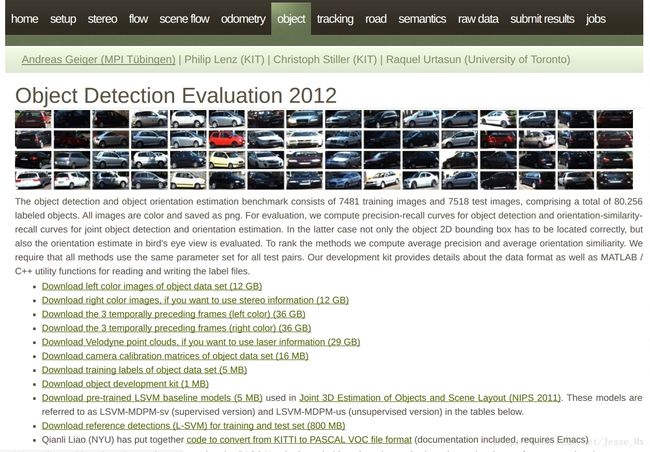
进行SSD训练只需要下载第1个图片集 Download left color images of object data set (12 GB)和标注文件 Download training labels of object data set (5 MB) 就够了。然后将其解压,发现其中7481张训练图片有标注信息,而测试图片没有,这就是本次训练所使用的图片数量。由于SSD中训练脚本是基于VOC数据集格式的,所以我们需要把KITTI数据集做成PASCAL VOC的格式,其基本架构可以参看这篇博客:PASCAL VOC数据集分析 。根据SSD训练要求,我在/home/zy/data/中目录中建立一系列文件夹存放所需数据集和工具文件,相应的路径与请参见我给出的图片,如果有什么 不懂的可以给我留言。具体如下:

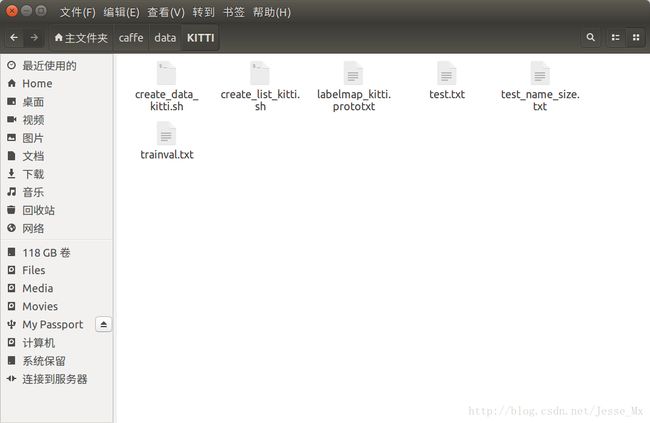
在整个KITTI文件夹中,它们的层次关系如下:
# 在data/文件夹下新建KITTIdevkit/KITTI两层子目录,所需文件放在KITTI/中
Annotations/
└── 000000.xml
ImageSets/
└── main/
└── trainval.txt
└── test.txt # 等等
JPEGImages/
└── 000000.png
Labels/
└── 000000.txt # 自建文件夹,存放原始标注信息,待转化为xml,不属于VOC格式
create_train_test_txt.py # 3个python工具,后面有详细介绍
modify_annotations_txt.py
txt_to_xml.pyKITTI标注信息说明
KITTI标注信息是放在data_object_label.zip中的,具体的格式如下图所示:(请大家仔细看看我的文件路径)

Car 0.00 0 1.96 280.38 185.10 344.90 215.59 1.49 1.76 4.01 -15.71 2.16 38.26 1.57
Car 0.00 0 1.88 365.14 184.54 406.11 205.20 1.38 1.80 3.41 -15.89 2.23 51.17 1.58
DontCare -1 -1 -10 402.27 166.69 477.31 197.98 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 518.53 177.31 531.51 187.17 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 1207.50 233.35 1240.00 333.39 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 535.06 177.65 545.26 185.82 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 558.03 177.88 567.50 184.65 -1 -1 -1 -1000 -1000 -1000 -10那么上面的数据格式是什么意思呢,我们需要很明确的知晓后,才能更好的训练模型,具体的含义如下:
下面是官方的解释文档
Data Format Description
=======================
The data for training and testing can be found in the corresponding folders.
The sub-folders are structured as follows:
- image_02/ contains the left color camera images (png)
- label_02/ contains the left color camera label files (plain text files)
- calib/ contains the calibration for all four cameras (plain text file)
The label files contain the following information, which can be read and
written using the matlab tools (readLabels.m, writeLabels.m) provided within
this devkit. All values (numerical or strings) are separated via spaces,
each row corresponds to one object. The 15 columns represent:
#Values Name Description
----------------------------------------------------------------------------
1 type Describes the type of object: 'Car', 'Van', 'Truck',
'Pedestrian', 'Person_sitting', 'Cyclist', 'Tram',
'Misc' or 'DontCare'
1 truncated Float from 0 (non-truncated) to 1 (truncated), where
truncated refers to the object leaving image boundaries
1 occluded Integer (0,1,2,3) indicating occlusion state:
0 = fully visible, 1 = partly occluded
2 = largely occluded, 3 = unknown
1 alpha Observation angle of object, ranging [-pi..pi]
4 bbox 2D bounding box of object in the image (0-based index):
contains left, top, right, bottom pixel coordinates
3 dimensions 3D object dimensions: height, width, length (in meters)
3 location 3D object location x,y,z in camera coordinates (in meters)
1 rotation_y Rotation ry around Y-axis in camera coordinates [-pi..pi]
1 score Only for results: Float, indicating confidence in
detection, needed for p/r curves, higher is better.
Here, 'DontCare' labels denote regions in which objects have not been labeled,
for example because they have been too far away from the laser scanner. To
prevent such objects from being counted as false positives our evaluation
script will ignore objects detected in don't care regions of the test set.
You can use the don't care labels in the training set to avoid that your object
detector is harvesting hard negatives from those areas, in case you consider
non-object regions from the training images as negative examples.
The coordinates in the camera coordinate system can be projected in the image
by using the 3x4 projection matrix in the calib folder, where for the left
color camera for which the images are provided, P2 must be used. The
difference between rotation_y and alpha is, that rotation_y is directly
given in camera coordinates, while alpha also considers the vector from the
camera center to the object center, to compute the relative orientation of
the object with respect to the camera. For example, a car which is facing
along the X-axis of the camera coordinate system corresponds to rotation_y=0,
no matter where it is located in the X/Z plane (bird's eye view), while
alpha is zero only, when this object is located along the Z-axis of the
camera. When moving the car away from the Z-axis, the observation angle
will change.
To project a point from Velodyne coordinates into the left color image,
you can use this formula: x = P2 * R0_rect * Tr_velo_to_cam * y
For the right color image: x = P3 * R0_rect * Tr_velo_to_cam * y
Note: All matrices are stored row-major, i.e., the first values correspond
to the first row. R0_rect contains a 3x3 matrix which you need to extend to
a 4x4 matrix by adding a 1 as the bottom-right element and 0's elsewhere.
Tr_xxx is a 3x4 matrix (R|t), which you need to extend to a 4x4 matrix
in the same way!
Note, that while all this information is available for the training data,
only the data which is actually needed for the particular benchmark must
be provided to the evaluation server. However, all 15 values must be provided
at all times, with the unused ones set to their default values (=invalid) as
specified in writeLabels.m. Additionally a 16'th value must be provided
with a floating value of the score for a particular detection, where higher
indicates higher confidence in the detection. The range of your scores will
be automatically determined by our evaluation server, you don't have to
normalize it, but it should be roughly linear. If you use writeLabels.m for
writing your results, this function will take care of storing all required
data correctly.中文解释:(本人zouyu)
数据格式说明 ======================= 用于培训和测试的数据可以在相应的文件夹中找到。 子文件夹的结构如下: - image_02 /包含左侧彩色相机图像(png) - label_02 /包含左侧彩色相机标签文件(纯文本文件) - 校准/包含所有四台摄像机的校准(纯文本文件) 标签文件包含以下信息,可以读取和 使用在其中提供的matlab工具(readLabels.m,writeLabels.m)编写 这个开发包。所有的值(数字或字符串)都是通过空格分隔的, 每一行对应一个对象。15列代表: #Values名称说明 -------------------------------------------------- -------------------------- 1类型描述对象的类型:'Car','Van','Truck', '行人','人员配备','骑单车','电车', 'Misc'或'DontCare' 1将Float从0(非截断)截断为1(截断),其中 截断是指对象离开图像边界 1 occluded整数(0,1,2,3)表示遮挡状态: 0 =完全可见,1 =部分遮挡 2 =大部分被遮挡,3 =未知 1 alpha对象的观察角度,范围[-pi..pi] 4 bbox图像中对象的二维边界框(基于0的索引): 包含左,上,右,底像素坐标 3维3D对象尺寸:高度,宽度,长度(以米为单位) 3位置三维物体位置x,y,z相机坐标(以米为单位) 1 rotation_y在相机坐标中围绕Y轴旋转ry [-pi..pi] 1分仅用于结果:浮动,表示对自己的信心 检测,对于p / r曲线来说,越高越好。 在这里,'DontCare'标签表示对象未被标记的区域, 例如因为它们离激光扫描仪太远。至 防止此类对象被视为我们评估的误报 脚本将忽略在不关心测试集的区域中检测到的对象。 您可以使用训练集中的无关标签来避免您的对象 如果你考虑的话,探测器正在从这些地区收获难以消除的负面影响 来自训练图像的非对象区域作为反面例子。 相机坐标系中的坐标可以投影到图像中 通过使用校准文件夹中的3x4投影矩阵,在左侧 为其提供图像的彩色照相机,必须使用P2。该 rotation_y和alpha之间的区别在于,rotation_y是直接的 在摄像机坐标中给出,而阿尔法也考虑来自摄像机的矢量 摄像机中心到物体中心,计算相对方位 该物体相对于相机。例如,一辆正在面对的汽车 沿照相机坐标系的X轴对应于rotation_y = 0, 无论它位于X / Z平面(鸟瞰图)的哪个位置,同时 只有当这个物体沿着Z轴方向定位时,alpha才为零 相机。从Z轴移动汽车时,观察角度 会改变。 要将Velodyne坐标中的点投影到左侧的彩色图像中, 你可以使用这个公式:x = P2 * R0_rect * Tr_velo_to_cam * y 对于正确的彩色图像:x = P3 * R0_rect * Tr_velo_to_cam * y 注意:所有矩阵都存储在主行中,即第一个值对应 到第一行。R0_rect包含一个需要扩展到的3x3矩阵 一个4x4的矩阵,在右下角加上1作为0,在其他地方加0。 Tr_xxx是一个3x4矩阵(R | t),您需要将其扩展为4x4矩阵 以同样的方式! 请注意,虽然所有这些信息都可用于培训数据, 只有特定基准实际需要的数据必须 提供给评估服务器。但是,必须提供所有15个值 在任何时候,未使用的设置为默认值(=无效)为 在writeLabels.m中指定。另外必须提供第16个值 对于特定检测的分数浮动值更高 表明对检测的信心更高。你的分数的范围将会 由我们的评估服务器自动确定,您不必 规范化它,但它应该大致是线性的。如果你使用writeLabels.m 编写你的结果,这个功能将照顾所有需要的存储 数据正确。
转换KITTI类别
PASCAL VOC数据集总共20个类别,如果用于特定场景,20个类别确实多了。本文数据集设置3个类别, ‘Car’‘Cyclist’‘Pedestrian’,只不过标注信息中还有其他类型的车和人,直接略过有点浪费,将 ‘Van’, ‘Truck’, ‘Tram’ 合并到 ‘Car’ 类别中去,将 ‘Person_sitting’ 合并到 ‘Pedestrian’ 类别中去(‘Misc’ 和 ‘Dontcare’ 这两类直接忽略)。这里使用的是modify_annotations_txt.py工具,源码如下:
# coding=UTF-8
import glob
import string
txt_list = glob.glob('./Labels/*.txt') # 存储Labels文件夹所有txt文件路径
def show_category(txt_list):
category_list= []
for item in txt_list:
try:
with open(item) as tdf:
for each_line in tdf:
labeldata = each_line.strip().split(' ') # 去掉前后多余的字符并把其分开
category_list.append(labeldata[0]) # 只要第一个字段,即类别
except IOError as ioerr:
print('File error:'+str(ioerr))
print(set(category_list)) # 输出集合
def merge(line):
each_line=''
for i in range(len(line)):
if i!= (len(line)-1):
each_line=each_line+line[i]+' '
else:
each_line=each_line+line[i] # 最后一条字段后面不加空格
each_line=each_line+'\n'
return (each_line)
print('before modify categories are:\n')
show_category(txt_list)
for item in txt_list:
new_txt=[]
try:
with open(item, 'r') as r_tdf:
for each_line in r_tdf:
labeldata = each_line.strip().split(' ')
if labeldata[0] in ['Truck','Van','Tram']: # 合并汽车类
labeldata[0] = labeldata[0].replace(labeldata[0],'Car')
if labeldata[0] == 'Person_sitting': # 合并行人类
labeldata[0] = labeldata[0].replace(labeldata[0],'Pedestrian')
if labeldata[0] == 'DontCare': # 忽略Dontcare类
continue
if labeldata[0] == 'Misc': # 忽略Misc类
continue
new_txt.append(merge(labeldata)) # 重新写入新的txt文件
with open(item,'w+') as w_tdf: # w+是打开原文件将内容删除,另写新内容进去
for temp in new_txt:
w_tdf.write(temp)
except IOError as ioerr:
print('File error:'+str(ioerr))
print('\nafter modify categories are:\n')
show_category(txt_list)通过运行上面的modify_annotations_txt.py文件后会在Labels文件夹下生成相应的.txt文件,具体如下所示:

执行命令python modify_annotations_txt.py 来运行py程序,这里以000400.txt为例,显示转换前后的对比效果:
# 转换前
Car 0.00 0 -1.67 642.24 178.50 680.14 208.68 1.38 1.49 3.32 2.41 1.66 34.98 -1.60
Car 0.00 0 -1.75 685.77 178.12 767.02 235.21 1.50 1.62 3.89 3.27 1.67 21.18 -1.60
Car 0.67 0 -2.15 885.80 160.44 1241.00 374.00 1.69 1.58 3.95 3.64 1.65 5.47 -1.59
Truck 0.00 0 -1.89 755.82 101.65 918.16 230.75 3.55 2.56 7.97 7.06 1.63 23.91 -1.61
Car 0.00 1 -2.73 928.61 177.14 1016.83 209.77 1.48 1.36 3.51 17.33 1.71 34.63 -2.27
DontCare -1 -1 -10 541.27 169.15 551.15 175.57 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 616.21 176.35 636.76 189.44 -1 -1 -1 -1000 -1000 -1000 -10
# 转换后
Car 0.00 0 -1.67 642.24 178.50 680.14 208.68 1.38 1.49 3.32 2.41 1.66 34.98 -1.60
Car 0.00 0 -1.75 685.77 178.12 767.02 235.21 1.50 1.62 3.89 3.27 1.67 21.18 -1.60
Car 0.67 0 -2.15 885.80 160.44 1241.00 374.00 1.69 1.58 3.95 3.64 1.65 5.47 -1.59
Car 0.00 0 -1.89 755.82 101.65 918.16 230.75 3.55 2.56 7.97 7.06 1.63 23.91 -1.61
Car 0.00 1 -2.73 928.61 177.14 1016.83 209.77 1.48 1.36 3.51 17.33 1.71 34.63 -2.27 转txt为xml
对原始txt文件进行上述处理后,接下来需要将标注文件从txt转化为xml,并去掉标注信息中用不上的部分,只留下3类,还有把坐标值从float型转化为int型,最后所有生成的xml文件要存放在Annotations文件夹中。这里使用的是txt_to_xml.py工具,此处是由 KITTI_SSD 的代码修改而来,感谢作者的贡献。
# txt_to_xml.py
# encoding:utf-8
# 根据一个给定的XML Schema,使用DOM树的形式从空白文件生成一个XML
from xml.dom.minidom import Document
import cv2
import os
def generate_xml(name,split_lines,img_size,class_ind):
doc = Document() # 创建DOM文档对象
annotation = doc.createElement('annotation')
doc.appendChild(annotation)
title = doc.createElement('folder')
title_text = doc.createTextNode('KITTI')
title.appendChild(title_text)
annotation.appendChild(title)
img_name=name+'.png'
title = doc.createElement('filename')
title_text = doc.createTextNode(img_name)
title.appendChild(title_text)
annotation.appendChild(title)
source = doc.createElement('source')
annotation.appendChild(source)
title = doc.createElement('database')
title_text = doc.createTextNode('The KITTI Database')
title.appendChild(title_text)
source.appendChild(title)
title = doc.createElement('annotation')
title_text = doc.createTextNode('KITTI')
title.appendChild(title_text)
source.appendChild(title)
size = doc.createElement('size')
annotation.appendChild(size)
title = doc.createElement('width')
title_text = doc.createTextNode(str(img_size[1]))
title.appendChild(title_text)
size.appendChild(title)
title = doc.createElement('height')
title_text = doc.createTextNode(str(img_size[0]))
title.appendChild(title_text)
size.appendChild(title)
title = doc.createElement('depth')
title_text = doc.createTextNode(str(img_size[2]))
title.appendChild(title_text)
size.appendChild(title)
for split_line in split_lines:
line=split_line.strip().split()
if line[0] in class_ind:
object = doc.createElement('object')
annotation.appendChild(object)
title = doc.createElement('name')
title_text = doc.createTextNode(line[0])
title.appendChild(title_text)
object.appendChild(title)
bndbox = doc.createElement('bndbox')
object.appendChild(bndbox)
title = doc.createElement('xmin')
title_text = doc.createTextNode(str(int(float(line[4]))))
title.appendChild(title_text)
bndbox.appendChild(title)
title = doc.createElement('ymin')
title_text = doc.createTextNode(str(int(float(line[5]))))
title.appendChild(title_text)
bndbox.appendChild(title)
title = doc.createElement('xmax')
title_text = doc.createTextNode(str(int(float(line[6]))))
title.appendChild(title_text)
bndbox.appendChild(title)
title = doc.createElement('ymax')
title_text = doc.createTextNode(str(int(float(line[7]))))
title.appendChild(title_text)
bndbox.appendChild(title)
# 将DOM对象doc写入文件
f = open('Annotations/'+name+'.xml','w')
f.write(doc.toprettyxml(indent = ''))
f.close()
if __name__ == '__main__':
class_ind=('Pedestrian', 'Car', 'Cyclist')
cur_dir=os.getcwd()
labels_dir=os.path.join(cur_dir,'Labels')
for parent, dirnames, filenames in os.walk(labels_dir): # 分别得到根目录,子目录和根目录下文件
for file_name in filenames:
full_path=os.path.join(parent, file_name) # 获取文件全路径
f=open(full_path)
split_lines = f.readlines()
name= file_name[:-4] # 后四位是扩展名.txt,只取前面的文件名
img_name=name+'.png'
img_path=os.path.join('/home/zy/data/KITTIdevkit/KITTI/train_image',img_name) # 路径需要自行修改
img_size=cv2.imread(img_path).shape
generate_xml(name,split_lines,img_size,class_ind)
print('all txts has converted into xmls')执行命令python txt_to_xml.py 来运行py程序,转换效果如下:
# 原始的000400.txt
Car 0.00 0 -1.67 642.24 178.50 680.14 208.68 1.38 1.49 3.32 2.41 1.66 34.98 -1.60
Car 0.00 0 -1.75 685.77 178.12 767.02 235.21 1.50 1.62 3.89 3.27 1.67 21.18 -1.60
Car 0.67 0 -2.15 885.80 160.44 1241.00 374.00 1.69 1.58 3.95 3.64 1.65 5.47 -1.59
Car 0.00 0 -1.89 755.82 101.65 918.16 230.75 3.55 2.56 7.97 7.06 1.63 23.91 -1.61
Car 0.00 1 -2.73 928.61 177.14 1016.83 209.77 1.48 1.36 3.51 17.33 1.71 34.63 -2.27
# 生成的000400.xml(部分)
This XML file does not appear to have any style information associated with it. The document tree is shown below.
<annotation>
<folder>KITTIfolder>
<filename>000400.pngfilename>#KITTI的数据集中,有000400.png图片
<source>
<database>The KITTI Databasedatabase>
<annotation>KITTIannotation>
source>
<size>
<width>1242width>#图片长宽像素值,RGB三通道
<height>375height>
<depth>3depth>
size>
<object>
<name>Carname>#汽车
<bndbox>
<xmin>642xmin>
<ymin>178ymin>#左上角、右下角的坐标值
<xmax>680xmax>
<ymax>208ymax>
bndbox>
object>
<object>
<name>Carname>
<bndbox>
<xmin>685xmin>
<ymin>178ymin>
<xmax>767xmax>
<ymax>235ymax>
bndbox>
object>
......
annotation>在000400.png图片中,有一辆红色的小汽车,它的坐标值左上角为:(642,178),右下角为:(680,208)。上面的XML文件就是把图片中的汽车全部标出来了。这样用神经网络来做卷积的时候,我们就知道卷哪里(话说的有点像白话,但是可以帮人理解整个过程)。那么,我们要把训练集中的汽车全部标注出来。000400.png中的汽车如下面图片所示,给大家一个直观的感受。(ZOUYU)
生成训练验证集和测试集列表
用于SSD训练的Pascal VOC格式的数据集总共就是三大块:首先是JPEGImages文件夹,放入了所有png图片;然后是Annotations文件夹,上述步骤已经生成了相应的xml文件;最后就是imagesSets文件夹,里面有一个Main子文件夹,这个文件夹存放的是训练验证集,测试集的相关列表文件,如下图所示:

这里使用create_train_test_txt.py工具,自动生成上述16个txt文件,其中训练测试部分的比例可以自行修改,由于这个工具是用Python3写的,所以执行的时候应该是:python3 create_train_test_txt.py
# create_train_test_txt.py
# encoding:utf-8
import pdb
import glob
import os
import random
import math
def get_sample_value(txt_name, category_name):
label_path = './Labels/'
txt_path = label_path + txt_name+'.txt'
try:
with open(txt_path) as r_tdf:
if category_name in r_tdf.read():
return ' 1'
else:
return '-1'
except IOError as ioerr:
print('File error:'+str(ioerr))
txt_list_path = glob.glob('./Labels/*.txt')
txt_list = []
for item in txt_list_path:
temp1,temp2 = os.path.splitext(os.path.basename(item))
txt_list.append(temp1)
txt_list.sort()
print(txt_list, end = '\n\n')
# 有博客建议train:val:test=8:1:1,先尝试用一下
num_trainval = random.sample(txt_list, math.floor(len(txt_list)*9/10.0)) # 可修改百分比
num_trainval.sort()
print(num_trainval, end = '\n\n')
num_train = random.sample(num_trainval,math.floor(len(num_trainval)*8/9.0)) # 可修改百分比
num_train.sort()
print(num_train, end = '\n\n')
num_val = list(set(num_trainval).difference(set(num_train)))
num_val.sort()
print(num_val, end = '\n\n')
num_test = list(set(txt_list).difference(set(num_trainval)))
num_test.sort()
print(num_test, end = '\n\n')
pdb.set_trace()
Main_path = './ImageSets/Main/'
train_test_name = ['trainval','train','val','test']
category_name = ['Car','Pedestrian','Cyclist']
# 循环写trainvl train val test
for item_train_test_name in train_test_name:
list_name = 'num_'
list_name += item_train_test_name
train_test_txt_name = Main_path + item_train_test_name + '.txt'
try:
# 写单个文件
with open(train_test_txt_name, 'w') as w_tdf:
# 一行一行写
for item in eval(list_name):
w_tdf.write(item+'\n')
# 循环写Car Pedestrian Cyclist
for item_category_name in category_name:
category_txt_name = Main_path + item_category_name + '_' + item_train_test_name + '.txt'
with open(category_txt_name, 'w') as w_tdf:
# 一行一行写
for item in eval(list_name):
w_tdf.write(item+' '+ get_sample_value(item, item_category_name)+'\n')
except IOError as ioerr:
print('File error:'+str(ioerr))执行程序过程中,如遇到pdb提示,可按c键,再按enter键。如果想把标注数据全部作为trainval,而把未标注的数据(大约有7000多图片)作为test,需要重新修改脚本。
数据集的后续处理
下面进行数据集的后续处理,在/home/zy/data/KITTIdevkit/之下新建KITTI文件夹,用于存放本次训练所需的脚本工具,如下图所示。
生成训练所需列表文件
SSD训练的时候除了需要LMDB格式的数据以外,还需要读取三个列表文件,分别是:trainval.txt,test.txt和test_name_size.txt。前两个txt文件存放训练、测试图片的png路径和xml路径,第三个txt文件存放测试图片的名称和尺寸。所需工具可以由caffe/data/VOC0712/create_list.sh脚本修改而来。这里的caffe就是你自己的工程路径。
复制一份上述脚本,并重命名为create_list_kitti.sh,存放在KITTI文件夹中。经过修改后的脚本文件如下
# create_list_kitti.sh
#!/bin/bash
root_dir=/home/zy/data/KITTIdevkit ## 自行修改
sub_dir=ImageSets/Main
bash_dir="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
printf" bash_dir"
for dataset in trainval test
do
dst_file=$bash_dir/$dataset.txt
if [ -f $dst_file ]
then
rm -f $dst_file
fi
for name in KITTI ## 自行修改
do
#if [[ $dataset == "test" && $name == "VOC2012" ]] ## 这段可以注释掉
#then
#continue
#fi
echo "Create list for $name $dataset..."
dataset_file=$root_dir/$name/$sub_dir/$dataset.txt
img_file=$bash_dir/$dataset"_img.txt"
cp $dataset_file $img_file
sed -i "s/^/$name\/JPEGImages\//g" $img_file
sed -i "s/$/.png/g" $img_file ## 从jpg改为png
label_file=$bash_dir/$dataset"_label.txt"
cp $dataset_file $label_file
sed -i "s/^/$name\/Annotations\//g" $label_file
sed -i "s/$/.xml/g" $label_file
paste -d' ' $img_file $label_file >> $dst_file
rm -f $label_file
rm -f $img_file
done
# Generate image name and size infomation.
if [ $dataset == "test" ]
then
$bash_dir $root_dir $dst_file $bash_dir/$dataset"_name_size.txt"
fi
# Shuffle trainval file.
if [ $dataset == "trainval" ]
then
rand_file=$dst_file.random
cat $dst_file | perl -MList::Util=shuffle -e 'print shuffle();' > $rand_file
mv $rand_file $dst_file
fi
done 执行下面命令,可在/home/zy/data/KITTIdevkit/KITTI文件夹下生成3个训练所需txt文件。
$ cd ~/caffe
$ ./data/KITTI/create_list_kitti.sh #这里的路径根据自己的实际文件来执行而生成的txt列表格式如下:
# trainval.txt和test.txt文件格式
KITTI/JPEGImages/000003.png KITTI/Annotations/000003.xml
KITTI/JPEGImages/000136.png KITTI/Annotations/000136.xml
KITTI/JPEGImages/000022.png KITTI/Annotations/000022.xml
KITTI/JPEGImages/000151.png KITTI/Annotations/000151.xml
......# test_name_size.txt文件格式
000011 375 1242
000012 375 1242
000035 375 1242
000044 375 1242
......1由于只有3类,所以可以仿照例子,写一个labelmap_kitti.prototxt文件,用于记录label和name的对应关系,存放在/home/zy/data/KITTIdevkit/KITTI文件夹中,具体内容如下:
item {
name: "none_of_the_above"
label: 0
display_name: "background"
}
item {
name: "Car"
label: 1
display_name: "Car"
}
item {
name: "Pedestrian"
label: 2
display_name: "Pedestrian"
}
item {
name: "Cyclist"
label: 3
display_name: "Cyclist"
}生成LMDB数据库
如果前面一切顺利,现在就可以生成LMDB文件了,所需工具可以由/home/zy/data/KITTIdevkit/KITTI/create_data.sh脚本修改而来。仍然复制一份上述脚本,并重命名为create_data_kitti.sh,存放在KITTI文件夹中。经过修改后的脚本文件如下:
# create_data_kitti.sh
cur_dir=$(cd $( dirname ${BASH_SOURCE[0]} ) && pwd )
root_dir=$cur_dir
cd $root_dir
redo=1
data_root_dir="/home/zy/data/KITTIdevkit" ## 自行修改
dataset_name="KITTI" ## 自行修改
mapfile="/home/zy/data/KITTIdevkit/KITTI/labelmap_kitti.prototxt" ## 自行修改
anno_type="detection"
db="lmdb"
min_dim=0
max_dim=0
width=0
height=0
extra_cmd="--encode-type=jpg --encoded"
if [ $redo ]
then
extra_cmd="$extra_cmd --redo"
fi
for subset in test trainval
do
python $root_dir/scripts/create_annoset.py --anno-type=$anno_type --label-map-file=$mapfile --min-dim=$min_dim --max-dim=$max_dim --resize-width=$width --resize-height=$height --check-label $extra_cmd $data_root_dir $root_dir/$subset.txt $data_root_dir/$dataset_name/$db/$dataset_name"_"$subset"_"$db examples/$dataset_name
done #上面的这个scripts/create_annoset.py文件是SSD的CAFFE工程中的一个文件,这个非常重要。
#我是把它拷到了这个/home/zy/data/KITTIdevkit文件中来运行的。执行命令./data/KITTI/create_data_kitti.sh 来运行脚本,将会生成两份LMDB文件,路径分别如下
$ /home/zy/data/KITTIdevkit/KITTI/lmdb/KITTI_test_lmdb
$ /home/zy/data/KITTIdevkit/KITTI/lmdb/KITTI_trainval_lmdb

至此,训练数据可以说已经准备好了。
下载VGG预训练模型
将 SSD 用于自己的检测任务,是需要 Fine-tuning a pretrained network,看过论文的朋友可能都知道,论文中的SSD框架是是由VGG网络为基底(base)的。除此之外,作者也提供了另外两种结构的网络:ZF-SSD和Resnet-SSD,可以在caffe/examples/ssd 文件夹中查看相应的python训练代码。
初次训练,还是用VGG网络吧,下载该预训练模型,将其放到/home/zy/zouyu/deeping/caffe-ssd/models/VGGNet文件夹之下。

修改训练代码
一般的caffe训练都是使用train.prototxt和solver.prototxt文件,有同学可能想问了,为什么SSD项目下找不到这些文件呢?原因是SSD的模型很大,train.prototxt就有1000多行,直接修改参数的工作量太大,而且train.prototxt一旦改动,test.prototxt和solver.prototxt也要跟着改动。因此,作者使用了一个很有效的方法,利用python脚本,自动生成这些文件。初次训练,选择了ssd_pascal.py 脚本来训练SSD_300x300,那么将ssd_pascal.py复制一份,重命名为ssd_pascal_kitti.py,然后修改这个ython文件。
ssd_pascal.py脚本也有500多行,也不可能全部贴出来,这里就贴出可以修改的部分,作为一个参照。
PS.根据博友反馈,还是提供修改过的的训练脚本 ssd_pascal_kitti.py,以供参考。
自定义路径和常用参数
train_data = "examples/VOC0712/VOC0712_trainval_lmdb" # 训练数据路径,修改前
train_data = "examples/KITTI/KITTI_trainval_lmdb" # 修改后
------
test_data = "examples/VOC0712/VOC0712_test_lmdb" # 测试数据路径
test_data = "examples/KITTI/KITTI_test_lmdb"
------
model_name = "VGG_VOC0712_{}".format(job_name) # 模型名字
model_name = "KITTI_{}".format(job_name)
------
save_dir = "models/VGGNet/VOC0712/{}".format(job_name) # 模型保存路径
save_dir = "models/VGGNet/KITTI/{}".format(job_name)
------
snapshot_dir = "models/VGGNet/VOC0712/{}".format(job_name) # snapshot快照保存路径
snapshot_dir = "models/VGGNet/KITTI/{}".format(job_name)
------
job_dir = "jobs/VGGNet/VOC0712/{}".format(job_name) # job保存路径
job_dir = "jobs/VGGNet/KITTI/{}".format(job_name)
------
output_result_dir = "{}/data/VOCdevkit/results/VOC2007/{}/Main".format(os.environ['HOME'], job_name) # 测试结果txt保存路径
output_result_dir = "{}/data/KITTIdevkit/results/KITTI/{}/Main".format(os.environ['HOME'], job_name)
-------
name_size_file = "data/VOC0712/test_name_size.txt" # test_name_size.txt文件路径
name_size_file = "data/KITTI/test_name_size.txt"
-------
label_map_file = "data/VOC0712/labelmap_voc.prototxt" # label文件路径
label_map_file = "data/KITTI/labelmap_kitti.prototxt"
------
num_classes = 21 # 总类别数
num_classes = 4
------
gpus = "0,1,2,3" # 使用哪块GPU
gpus = "0" # 只有1块GPU
------
batch_size = 32 # 一次处理的图片数
batch_size = 自定义 # TITAN X刚好可以达到32,请根据显存大小调整
------
num_test_image = 4952 # 测试图片数量
num_test_image = 自定义 # 这个数量应该和test_name_size.txt保持一致
------
run_soon = True # 生成文件后自动开始训练
run_soon = False # 手动挡自定义训练参数
SSD的训练参数比较多,具体含义之前也了解过。但是初次试验,不太清楚该怎么调,所以决定基本先不改动其他参数(等训练一次后根据结果再调整,反复训练),只对初始学习率做调整。事实证明,对于KITTI数据集,初始学习率0.001过大,会导致网络不收敛,此处应调整为0.0001,具体如下:
# If true, use batch norm for all newly added layers.
# Currently only the non batch norm version has been tested.
use_batchnorm = False
lr_mult = 1
# Use different initial learning rate.
if use_batchnorm:
base_lr = 0.0004
else:
# A learning rate for batch_size = 1, num_gpus = 1.
base_lr = 0.00004
......
if normalization_mode == P.Loss.NONE:
base_lr /= batch_size_per_device
elif normalization_mode == P.Loss.VALID:
base_lr *= 25. / loc_weight
elif normalization_mode == P.Loss.FULL:
# Roughly there are 2000 prior bboxes per image.
# TODO(weiliu89): Estimate the exact # of priors.
base_lr *= 2000.
# 从以上代码可以看出,训练脚本没有使用batchnorm,未修改前,初始学习率 = base_lr * 25 / loc_weight=0.001
# 将base_lr变量改为原来十分之一,也就是0.00004->0.000004,就能把学习率调整为0.0001训练模型
修改完脚本参数后,运行该脚本程序。
$ cd caffe/
$ python examples/ssd/ssd_pascal_kitti.py#ssd_pascal_kitti.py 这个文件就是我运行的文件 ZOUYU
from __future__ import print_function
import caffe
from caffe.model_libs import *
from google.protobuf import text_format
import math
import os
import shutil
import stat
import subprocess
import sys
# Add extra layers on top of a "base" network (e.g. VGGNet or Inception).
def AddExtraLayers(net, use_batchnorm=True, lr_mult=1):
use_relu = True
# Add additional convolutional layers.
# 19 x 19
from_layer = net.keys()[-1]
# TODO(weiliu89): Construct the name using the last layer to avoid duplication.
# 10 x 10
out_layer = "conv6_1"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 256, 1, 0, 1,
lr_mult=lr_mult)
from_layer = out_layer
out_layer = "conv6_2"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 512, 3, 1, 2,
lr_mult=lr_mult)
# 5 x 5
from_layer = out_layer
out_layer = "conv7_1"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 128, 1, 0, 1,
lr_mult=lr_mult)
from_layer = out_layer
out_layer = "conv7_2"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 256, 3, 1, 2,
lr_mult=lr_mult)
# 3 x 3
from_layer = out_layer
out_layer = "conv8_1"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 128, 1, 0, 1,
lr_mult=lr_mult)
from_layer = out_layer
out_layer = "conv8_2"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 256, 3, 0, 1,
lr_mult=lr_mult)
# 1 x 1
from_layer = out_layer
out_layer = "conv9_1"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 128, 1, 0, 1,
lr_mult=lr_mult)
from_layer = out_layer
out_layer = "conv9_2"
ConvBNLayer(net, from_layer, out_layer, use_batchnorm, use_relu, 256, 3, 0, 1,
lr_mult=lr_mult)
return net
### Modify the following parameters accordingly ###
# The directory which contains the caffe code.
# We assume you are running the script at the CAFFE_ROOT.
caffe_root = os.getcwd()
# Set true if you want to start training right after generating all files.
run_soon = True #False
# Set true if you want to load from most recently saved snapshot.
# Otherwise, we will load from the pretrain_model defined below.
resume_training = True
# If true, Remove old model files.
remove_old_models = False
# The database file for training data. Created by data/VOC0712/create_data.sh
train_data = "examples/KITTI/KITTI_trainval_lmdb"
# The database file for testing data. Created by data/VOC0712/create_data.sh
test_data = "examples/KITTI/KITTI_test_lmdb"
# Specify the batch sampler.
resize_width = 300
resize_height = 300
resize = "{}x{}".format(resize_width, resize_height)
batch_sampler = [
{
'sampler': {
},
'max_trials': 1,
'max_sample': 1,
},
{
'sampler': {
'min_scale': 0.3,
'max_scale': 1.0,
'min_aspect_ratio': 0.5,
'max_aspect_ratio': 2.0,
},
'sample_constraint': {
'min_jaccard_overlap': 0.1,
},
'max_trials': 50,
'max_sample': 1,
},
{
'sampler': {
'min_scale': 0.3,
'max_scale': 1.0,
'min_aspect_ratio': 0.5,
'max_aspect_ratio': 2.0,
},
'sample_constraint': {
'min_jaccard_overlap': 0.3,
},
'max_trials': 50,
'max_sample': 1,
},
{
'sampler': {
'min_scale': 0.3,
'max_scale': 1.0,
'min_aspect_ratio': 0.5,
'max_aspect_ratio': 2.0,
},
'sample_constraint': {
'min_jaccard_overlap': 0.5,
},
'max_trials': 50,
'max_sample': 1,
},
{
'sampler': {
'min_scale': 0.3,
'max_scale': 1.0,
'min_aspect_ratio': 0.5,
'max_aspect_ratio': 2.0,
},
'sample_constraint': {
'min_jaccard_overlap': 0.7,
},
'max_trials': 50,
'max_sample': 1,
},
{
'sampler': {
'min_scale': 0.3,
'max_scale': 1.0,
'min_aspect_ratio': 0.5,
'max_aspect_ratio': 2.0,
},
'sample_constraint': {
'min_jaccard_overlap': 0.9,
},
'max_trials': 50,
'max_sample': 1,
},
{
'sampler': {
'min_scale': 0.3,
'max_scale': 1.0,
'min_aspect_ratio': 0.5,
'max_aspect_ratio': 2.0,
},
'sample_constraint': {
'max_jaccard_overlap': 1.0,
},
'max_trials': 50,
'max_sample': 1,
},
]
train_transform_param = {
'mirror': True,
'mean_value': [104, 117, 123],
'resize_param': {
'prob': 1,
'resize_mode': P.Resize.WARP,
'height': resize_height,
'width': resize_width,
'interp_mode': [
P.Resize.LINEAR,
P.Resize.AREA,
P.Resize.NEAREST,
P.Resize.CUBIC,
P.Resize.LANCZOS4,
],
},
'distort_param': {
'brightness_prob': 0.5,
'brightness_delta': 32,
'contrast_prob': 0.5,
'contrast_lower': 0.5,
'contrast_upper': 1.5,
'hue_prob': 0.5,
'hue_delta': 18,
'saturation_prob': 0.5,
'saturation_lower': 0.5,
'saturation_upper': 1.5,
'random_order_prob': 0.0,
},
'expand_param': {
'prob': 0.5,
'max_expand_ratio': 4.0,
},
'emit_constraint': {
'emit_type': caffe_pb2.EmitConstraint.CENTER,
}
}
test_transform_param = {
'mean_value': [104, 117, 123],
'resize_param': {
'prob': 1,
'resize_mode': P.Resize.WARP,
'height': resize_height,
'width': resize_width,
'interp_mode': [P.Resize.LINEAR],
},
}
# If true, use batch norm for all newly added layers.
# Currently only the non batch norm version has been tested.
use_batchnorm = False
lr_mult = 1
# Use different initial learning rate.
if use_batchnorm:
base_lr = 0.0004
else:
# A learning rate for batch_size = 1, num_gpus = 1.
base_lr = 0.000004
# Modify the job name if you want.
job_name = "SSD_{}".format(resize)
# The name of the model. Modify it if you want.
model_name = "KITTI_{}".format(job_name)
# Directory which stores the model .prototxt file.
save_dir = "models/VGGNet/KITTI/{}".format(job_name)
# Directory which stores the snapshot of models.
snapshot_dir = "models/VGGNet/KITTI/{}".format(job_name)
# Directory which stores the job script and log file.
job_dir = "jobs/VGGNet/KITTI/{}".format(job_name)
# Directory which stores the detection results.
output_result_dir = "{}/data/KITTIdevkit/results/KITTI/{}/Main".format(os.environ['HOME'], job_name)
# model definition files.
train_net_file = "{}/train.prototxt".format(save_dir)
test_net_file = "{}/test.prototxt".format(save_dir)
deploy_net_file = "{}/deploy.prototxt".format(save_dir)
solver_file = "{}/solver.prototxt".format(save_dir)
# snapshot prefix.
snapshot_prefix = "{}/{}".format(snapshot_dir, model_name)
# job script path.
job_file = "{}/{}.sh".format(job_dir, model_name)
# Stores the test image names and sizes. Created by data/VOC0712/create_list.sh
name_size_file = "data/KITTI/test_name_size.txt"
# The pretrained model. We use the Fully convolutional reduced (atrous) VGGNet.
pretrain_model = "models/VGGNet/VGG_ILSVRC_16_layers_fc_reduced.caffemodel"
# Stores LabelMapItem.
label_map_file = "data/KITTI/labelmap_kitti.prototxt"
# MultiBoxLoss parameters.
num_classes = 4
share_location = True
background_label_id=0
train_on_diff_gt = True
normalization_mode = P.Loss.VALID
code_type = P.PriorBox.CENTER_SIZE
ignore_cross_boundary_bbox = False
mining_type = P.MultiBoxLoss.MAX_NEGATIVE
neg_pos_ratio = 3.
loc_weight = (neg_pos_ratio + 1.) / 4.
multibox_loss_param = {
'loc_loss_type': P.MultiBoxLoss.SMOOTH_L1,
'conf_loss_type': P.MultiBoxLoss.SOFTMAX,
'loc_weight': loc_weight,
'num_classes': num_classes,
'share_location': share_location,
'match_type': P.MultiBoxLoss.PER_PREDICTION,
'overlap_threshold': 0.5,
'use_prior_for_matching': True,
'background_label_id': background_label_id,
'use_difficult_gt': train_on_diff_gt,
'mining_type': mining_type,
'neg_pos_ratio': neg_pos_ratio,
'neg_overlap': 0.5,
'code_type': code_type,
'ignore_cross_boundary_bbox': ignore_cross_boundary_bbox,
}
loss_param = {
'normalization': normalization_mode,
}
# parameters for generating priors.
# minimum dimension of input image
min_dim = 300
# conv4_3 ==> 38 x 38
# fc7 ==> 19 x 19
# conv6_2 ==> 10 x 10
# conv7_2 ==> 5 x 5
# conv8_2 ==> 3 x 3
# conv9_2 ==> 1 x 1
mbox_source_layers = ['conv4_3', 'fc7', 'conv6_2', 'conv7_2', 'conv8_2', 'conv9_2']
# in percent %
min_ratio = 20
max_ratio = 90
step = int(math.floor((max_ratio - min_ratio) / (len(mbox_source_layers) - 2)))
min_sizes = []
max_sizes = []
for ratio in xrange(min_ratio, max_ratio + 1, step):
min_sizes.append(min_dim * ratio / 100.)
max_sizes.append(min_dim * (ratio + step) / 100.)
min_sizes = [min_dim * 10 / 100.] + min_sizes
max_sizes = [min_dim * 20 / 100.] + max_sizes
steps = [8, 16, 32, 64, 100, 300]
aspect_ratios = [[2], [2, 3], [2, 3], [2, 3], [2], [2]]
# L2 normalize conv4_3.
normalizations = [20, -1, -1, -1, -1, -1]
# variance used to encode/decode prior bboxes.
if code_type == P.PriorBox.CENTER_SIZE:
prior_variance = [0.1, 0.1, 0.2, 0.2]
else:
prior_variance = [0.1]
flip = True
clip = False
# Solver parameters.
# Defining which GPUs to use.
gpus = "0"
gpulist = gpus.split(",")
num_gpus = len(gpulist)
# Divide the mini-batch to different GPUs.zouyu changed from 32 to 16
batch_size = 16 #这个地方我做了修改,从32改到了16,主要是因为我的显存不太足,会OUT OF MEMOREY。。。。。。 ZOUYU
accum_batch_size = 16
iter_size = accum_batch_size / batch_size
solver_mode = P.Solver.CPU
device_id = 0
batch_size_per_device = batch_size
if num_gpus > 0:
batch_size_per_device = int(math.ceil(float(batch_size) / num_gpus))
iter_size = int(math.ceil(float(accum_batch_size) / (batch_size_per_device * num_gpus)))
solver_mode = P.Solver.GPU
device_id = int(gpulist[0])
if normalization_mode == P.Loss.NONE:
base_lr /= batch_size_per_device
elif normalization_mode == P.Loss.VALID:
base_lr *= 25. / loc_weight
elif normalization_mode == P.Loss.FULL:
# Roughly there are 2000 prior bboxes per image.
# TODO(weiliu89): Estimate the exact # of priors.
base_lr *= 2000.
# Evaluate on whole test set.
num_test_image = 749
test_batch_size = 8
# Ideally test_batch_size should be divisible by num_test_image,
# otherwise mAP will be slightly off the true value.
test_iter = int(math.ceil(float(num_test_image) / test_batch_size))
solver_param = {
# Train parameters
'base_lr': base_lr,
'weight_decay': 0.0005,
'lr_policy': "multistep",
'stepvalue': [80000, 100000, 120000],
'gamma': 0.1,
'momentum': 0.9,
'iter_size': iter_size,
'max_iter': 120000,
'snapshot': 80000,
'display': 10,
'average_loss': 10,
'type': "SGD",
'solver_mode': solver_mode,
'device_id': device_id,
'debug_info': False,
'snapshot_after_train': True,
# Test parameters
'test_iter': [test_iter],
'test_interval': 10000,
'eval_type': "detection",
'ap_version': "11point",
'test_initialization': False,
}
# parameters for generating detection output.
det_out_param = {
'num_classes': num_classes,
'share_location': share_location,
'background_label_id': background_label_id,
'nms_param': {'nms_threshold': 0.45, 'top_k': 400},
'save_output_param': {
'output_directory': output_result_dir,
'output_name_prefix': "comp4_det_test_",
'output_format': "VOC",
'label_map_file': label_map_file,
'name_size_file': name_size_file,
'num_test_image': num_test_image,
},
'keep_top_k': 200,
'confidence_threshold': 0.01,
'code_type': code_type,
}
# parameters for evaluating detection results.
det_eval_param = {
'num_classes': num_classes,
'background_label_id': background_label_id,
'overlap_threshold': 0.5,
'evaluate_difficult_gt': False,
'name_size_file': name_size_file,
}
### Hopefully you don't need to change the following ###
# Check file.
check_if_exist(train_data)
check_if_exist(test_data)
check_if_exist(label_map_file)
check_if_exist(pretrain_model)
make_if_not_exist(save_dir)
make_if_not_exist(job_dir)
make_if_not_exist(snapshot_dir)
# Create train net.
net = caffe.NetSpec()
net.data, net.label = CreateAnnotatedDataLayer(train_data, batch_size=batch_size_per_device,
train=True, output_label=True, label_map_file=label_map_file,
transform_param=train_transform_param, batch_sampler=batch_sampler)
VGGNetBody(net, from_layer='data', fully_conv=True, reduced=True, dilated=True,
dropout=False)
AddExtraLayers(net, use_batchnorm, lr_mult=lr_mult)
mbox_layers = CreateMultiBoxHead(net, data_layer='data', from_layers=mbox_source_layers,
use_batchnorm=use_batchnorm, min_sizes=min_sizes, max_sizes=max_sizes,
aspect_ratios=aspect_ratios, steps=steps, normalizations=normalizations,
num_classes=num_classes, share_location=share_location, flip=flip, clip=clip,
prior_variance=prior_variance, kernel_size=3, pad=1, lr_mult=lr_mult)
# Create the MultiBoxLossLayer.
name = "mbox_loss"
mbox_layers.append(net.label)
net[name] = L.MultiBoxLoss(*mbox_layers, multibox_loss_param=multibox_loss_param,
loss_param=loss_param, include=dict(phase=caffe_pb2.Phase.Value('TRAIN')),
propagate_down=[True, True, False, False])
with open(train_net_file, 'w') as f:
print('name: "{}_train"'.format(model_name), file=f)
print(net.to_proto(), file=f)
shutil.copy(train_net_file, job_dir)
# Create test net.
net = caffe.NetSpec()
net.data, net.label = CreateAnnotatedDataLayer(test_data, batch_size=test_batch_size,
train=False, output_label=True, label_map_file=label_map_file,
transform_param=test_transform_param)
VGGNetBody(net, from_layer='data', fully_conv=True, reduced=True, dilated=True,
dropout=False)
AddExtraLayers(net, use_batchnorm, lr_mult=lr_mult)
mbox_layers = CreateMultiBoxHead(net, data_layer='data', from_layers=mbox_source_layers,
use_batchnorm=use_batchnorm, min_sizes=min_sizes, max_sizes=max_sizes,
aspect_ratios=aspect_ratios, steps=steps, normalizations=normalizations,
num_classes=num_classes, share_location=share_location, flip=flip, clip=clip,
prior_variance=prior_variance, kernel_size=3, pad=1, lr_mult=lr_mult)
conf_name = "mbox_conf"
if multibox_loss_param["conf_loss_type"] == P.MultiBoxLoss.SOFTMAX:
reshape_name = "{}_reshape".format(conf_name)
net[reshape_name] = L.Reshape(net[conf_name], shape=dict(dim=[0, -1, num_classes]))
softmax_name = "{}_softmax".format(conf_name)
net[softmax_name] = L.Softmax(net[reshape_name], axis=2)
flatten_name = "{}_flatten".format(conf_name)
net[flatten_name] = L.Flatten(net[softmax_name], axis=1)
mbox_layers[1] = net[flatten_name]
elif multibox_loss_param["conf_loss_type"] == P.MultiBoxLoss.LOGISTIC:
sigmoid_name = "{}_sigmoid".format(conf_name)
net[sigmoid_name] = L.Sigmoid(net[conf_name])
mbox_layers[1] = net[sigmoid_name]
net.detection_out = L.DetectionOutput(*mbox_layers,
detection_output_param=det_out_param,
include=dict(phase=caffe_pb2.Phase.Value('TEST')))
net.detection_eval = L.DetectionEvaluate(net.detection_out, net.label,
detection_evaluate_param=det_eval_param,
include=dict(phase=caffe_pb2.Phase.Value('TEST')))
with open(test_net_file, 'w') as f:
print('name: "{}_test"'.format(model_name), file=f)
print(net.to_proto(), file=f)
shutil.copy(test_net_file, job_dir)
# Create deploy net.
# Remove the first and last layer from test net.
deploy_net = net
with open(deploy_net_file, 'w') as f:
net_param = deploy_net.to_proto()
# Remove the first (AnnotatedData) and last (DetectionEvaluate) layer from test net.
del net_param.layer[0]
del net_param.layer[-1]
net_param.name = '{}_deploy'.format(model_name)
net_param.input.extend(['data'])
net_param.input_shape.extend([
caffe_pb2.BlobShape(dim=[1, 3, resize_height, resize_width])])
print(net_param, file=f)
shutil.copy(deploy_net_file, job_dir)
# Create solver.
solver = caffe_pb2.SolverParameter(
train_net=train_net_file,
test_net=[test_net_file],
snapshot_prefix=snapshot_prefix,
**solver_param)
with open(solver_file, 'w') as f:
print(solver, file=f)
shutil.copy(solver_file, job_dir)
max_iter = 0
# Find most recent snapshot.
for file in os.listdir(snapshot_dir):
if file.endswith(".solverstate"):
basename = os.path.splitext(file)[0]
iter = int(basename.split("{}_iter_".format(model_name))[1])
if iter > max_iter:
max_iter = iter
train_src_param = '--weights="{}" \\\n'.format(pretrain_model)
if resume_training:
if max_iter > 0:
train_src_param = '--snapshot="{}_iter_{}.solverstate" \\\n'.format(snapshot_prefix, max_iter)
if remove_old_models:
# Remove any snapshots smaller than max_iter.
for file in os.listdir(snapshot_dir):
if file.endswith(".solverstate"):
basename = os.path.splitext(file)[0]
iter = int(basename.split("{}_iter_".format(model_name))[1])
if max_iter > iter:
os.remove("{}/{}".format(snapshot_dir, file))
if file.endswith(".caffemodel"):
basename = os.path.splitext(file)[0]
iter = int(basename.split("{}_iter_".format(model_name))[1])
if max_iter > iter:
os.remove("{}/{}".format(snapshot_dir, file))
# Create job file.
with open(job_file, 'w') as f:
f.write('cd {}\n'.format(caffe_root))
f.write('./build/tools/caffe train \\\n')
f.write('--solver="{}" \\\n'.format(solver_file))
f.write(train_src_param)
if solver_param['solver_mode'] == P.Solver.GPU:
f.write('--gpu {} 2>&1 | tee {}/{}.log\n'.format(gpus, job_dir, model_name))
else:
f.write('2>&1 | tee {}/{}.log\n'.format(job_dir, model_name))
# Copy the python script to job_dir.
py_file = os.path.abspath(__file__)
shutil.copy(py_file, job_dir)
# Run the job.
os.chmod(job_file, stat.S_IRWXU)
if run_soon:
subprocess.call(job_file, shell=True)
然后模型就训练起来了,可能会遇到“out of memory”的问题,那是batch_size设的太高,导致显存不足,此时调低batch_size再重新运行即可解决。
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
dilation: 1
}
}
layer {
name: "relu5_1"
type: "ReLU"
bottom: "conv5_1"
top: "conv5_1"
}
layer {
name: "conv5_2"
type: "Convolution"
bottom: "conv5_1"
top: "conv5_2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
dilation: 1
}
}
layer {
name: "relu5_2"
type: "ReLU"
bottom: "conv5_2"
top: "conv5_2"
}
layer {
name: "conv5_3"
type: "Convolution"
bottom: "conv5_2"
top: "conv5_3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
dilation: 1
}
}
layer {
name: "relu5_3"
type: "ReLU"
bottom: "conv5_3"
top: "conv5_3"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5_3"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
pad: 1
}
}
layer {
name: "fc6"
type: "Convolution"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 1024
pad: 6
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
dilation: 6
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "fc7"
type: "Convolution"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 1024
kernel_size: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "conv6_1"
type: "Convolution"
bottom: "fc7"
top: "conv6_1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 0
kernel_size: 1
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "conv6_1_relu"
type: "ReLU"
bottom: "conv6_1"
top: "conv6_1"
}
layer {
name: "conv6_2"
type: "Convolution"
bottom: "conv6_1"
top: "conv6_2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
stride: 2
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "conv6_2_relu"
type: "ReLU"
bottom: "conv6_2"
top: "conv6_2"
}
layer {
name: "conv7_1"
type: "Convolution"
bottom: "conv6_2"
top: "conv7_1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 0
kernel_size: 1
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "conv7_1_relu"
type: "ReLU"
bottom: "conv7_1"
top: "conv7_1"
}
layer {
name: "conv7_2"
type: "Convolution"
bottom: "conv7_1"
top: "conv7_2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
stride: 2
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "conv7_2_relu"
type: "ReLU"
bottom: "conv7_2"
top: "conv7_2"
}
layer {
name: "conv8_1"
type: "Convolution"
bottom: "conv7_2"
top: "conv8_1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 0
kernel_size: 1
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "conv8_1_relu"
type: "ReLU"
bottom: "conv8_1"
top: "conv8_1"
}
layer {
name: "conv8_2"
type: "Convolution"
bottom: "conv8_1"
top: "conv8_2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 0
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "conv8_2_relu"
type: "ReLU"
bottom: "conv8_2"
top: "conv8_2"
}
layer {
name: "conv9_1"
type: "Convolution"
bottom: "conv8_2"
top: "conv9_1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 0
kernel_size: 1
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "conv9_1_relu"
type: "ReLU"
bottom: "conv9_1"
top: "conv9_1"
}
layer {
name: "conv9_2"
type: "Convolution"
bottom: "conv9_1"
top: "conv9_2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 0
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "conv9_2_relu"
type: "ReLU"
bottom: "conv9_2"
top: "conv9_2"
}
layer {
name: "conv4_3_norm"
type: "Normalize"
bottom: "conv4_3"
top: "conv4_3_norm"
norm_param {
across_spatial: false
scale_filler {
type: "constant"
value: 20
}
channel_shared: false
}
}
layer {
name: "conv4_3_norm_mbox_loc"
type: "Convolution"
bottom: "conv4_3_norm"
top: "conv4_3_norm_mbox_loc"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 16
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "conv4_3_norm_mbox_loc_perm"
type: "Permute"
bottom: "conv4_3_norm_mbox_loc"
top: "conv4_3_norm_mbox_loc_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
layer {
name: "conv4_3_norm_mbox_loc_flat"
type: "Flatten"
bottom: "conv4_3_norm_mbox_loc_perm"
top: "conv4_3_norm_mbox_loc_flat"
flatten_param {
axis: 1
}
}
layer {
name: "conv4_3_norm_mbox_conf"
type: "Convolution"
bottom: "conv4_3_norm"
top: "conv4_3_norm_mbox_conf"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 16
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "conv4_3_norm_mbox_conf_perm"
type: "Permute"
bottom: "conv4_3_norm_mbox_conf"
top: "conv4_3_norm_mbox_conf_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
layer {
name: "conv4_3_norm_mbox_conf_flat"
type: "Flatten"
bottom: "conv4_3_norm_mbox_conf_perm"
top: "conv4_3_norm_mbox_conf_flat"
flatten_param {
axis: 1
}
}
layer {
name: "conv4_3_norm_mbox_priorbox"
type: "PriorBox"
bottom: "conv4_3_norm"
bottom: "data"
top: "conv4_3_norm_mbox_priorbox"
prior_box_param {
min_size: 30
max_size: 60
aspect_ratio: 2
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
step: 8
offset: 0.5
}
}
layer {
name: "fc7_mbox_loc"
type: "Convolution"
bottom: "fc7"
top: "fc7_mbox_loc"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 24
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "fc7_mbox_loc_perm"
type: "Permute"
bottom: "fc7_mbox_loc"
top: "fc7_mbox_loc_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
layer {
name: "fc7_mbox_loc_flat"
type: "Flatten"
bottom: "fc7_mbox_loc_perm"
top: "fc7_mbox_loc_flat"
flatten_param {
axis: 1
}
}
layer {
name: "fc7_mbox_conf"
type: "Convolution"
bottom: "fc7"
top: "fc7_mbox_conf"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 24
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "fc7_mbox_conf_perm"
type: "Permute"
bottom: "fc7_mbox_conf"
top: "fc7_mbox_conf_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
layer {
name: "fc7_mbox_conf_flat"
type: "Flatten"
bottom: "fc7_mbox_conf_perm"
top: "fc7_mbox_conf_flat"
flatten_param {
axis: 1
}
}
layer {
name: "fc7_mbox_priorbox"
type: "PriorBox"
bottom: "fc7"
bottom: "data"
top: "fc7_mbox_priorbox"
prior_box_param {
min_size: 60
max_size: 111
aspect_ratio: 2
aspect_ratio: 3
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
step: 16
offset: 0.5
}
}
layer {
name: "conv6_2_mbox_loc"
type: "Convolution"
bottom: "conv6_2"
top: "conv6_2_mbox_loc"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 24
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "conv6_2_mbox_loc_perm"
type: "Permute"
bottom: "conv6_2_mbox_loc"
top: "conv6_2_mbox_loc_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
layer {
name: "conv6_2_mbox_loc_flat"
type: "Flatten"
bottom: "conv6_2_mbox_loc_perm"
top: "conv6_2_mbox_loc_flat"
flatten_param {
axis: 1
}
}
layer {
name: "conv6_2_mbox_conf"
type: "Convolution"
bottom: "conv6_2"
top: "conv6_2_mbox_conf"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 24
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "conv6_2_mbox_conf_perm"
type: "Permute"
bottom: "conv6_2_mbox_conf"
top: "conv6_2_mbox_conf_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
layer {
name: "conv6_2_mbox_conf_flat"
type: "Flatten"
bottom: "conv6_2_mbox_conf_perm"
top: "conv6_2_mbox_conf_flat"
flatten_param {
axis: 1
}
}
layer {
name: "conv6_2_mbox_priorbox"
type: "PriorBox"
bottom: "conv6_2"
bottom: "data"
top: "conv6_2_mbox_priorbox"
prior_box_param {
min_size: 111
max_size: 162
aspect_ratio: 2
aspect_ratio: 3
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
step: 32
offset: 0.5
}
}
layer {
name: "conv7_2_mbox_loc"
type: "Convolution"
bottom: "conv7_2"
top: "conv7_2_mbox_loc"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 24
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "conv7_2_mbox_loc_perm"
type: "Permute"
bottom: "conv7_2_mbox_loc"
top: "conv7_2_mbox_loc_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
layer {
name: "conv7_2_mbox_loc_flat"
type: "Flatten"
bottom: "conv7_2_mbox_loc_perm"
top: "conv7_2_mbox_loc_flat"
flatten_param {
axis: 1
}
}
layer {
name: "conv7_2_mbox_conf"
type: "Convolution"
bottom: "conv7_2"
top: "conv7_2_mbox_conf"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 24
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "conv7_2_mbox_conf_perm"
type: "Permute"
bottom: "conv7_2_mbox_conf"
top: "conv7_2_mbox_conf_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
layer {
name: "conv7_2_mbox_conf_flat"
type: "Flatten"
bottom: "conv7_2_mbox_conf_perm"
top: "conv7_2_mbox_conf_flat"
flatten_param {
axis: 1
}
}
layer {
name: "conv7_2_mbox_priorbox"
type: "PriorBox"
bottom: "conv7_2"
bottom: "data"
top: "conv7_2_mbox_priorbox"
prior_box_param {
min_size: 162
max_size: 213
aspect_ratio: 2
aspect_ratio: 3
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
step: 64
offset: 0.5
}
}
layer {
name: "conv8_2_mbox_loc"
type: "Convolution"
bottom: "conv8_2"
top: "conv8_2_mbox_loc"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 16
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "conv8_2_mbox_loc_perm"
type: "Permute"
bottom: "conv8_2_mbox_loc"
top: "conv8_2_mbox_loc_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
layer {
name: "conv8_2_mbox_loc_flat"
type: "Flatten"
bottom: "conv8_2_mbox_loc_perm"
top: "conv8_2_mbox_loc_flat"
flatten_param {
axis: 1
}
}
layer {
name: "conv8_2_mbox_conf"
type: "Convolution"
bottom: "conv8_2"
top: "conv8_2_mbox_conf"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 16
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "conv8_2_mbox_conf_perm"
type: "Permute"
bottom: "conv8_2_mbox_conf"
top: "conv8_2_mbox_conf_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
layer {
name: "conv8_2_mbox_conf_flat"
type: "Flatten"
bottom: "conv8_2_mbox_conf_perm"
top: "conv8_2_mbox_conf_flat"
flatten_param {
axis: 1
}
}
layer {
name: "conv8_2_mbox_priorbox"
type: "PriorBox"
bottom: "conv8_2"
bottom: "data"
top: "conv8_2_mbox_priorbox"
prior_box_param {
min_size: 213
max_size: 264
aspect_ratio: 2
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
step: 100
offset: 0.5
}
}
layer {
name: "conv9_2_mbox_loc"
type: "Convolution"
bottom: "conv9_2"
top: "conv9_2_mbox_loc"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 16
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "conv9_2_mbox_loc_perm"
type: "Permute"
bottom: "conv9_2_mbox_loc"
top: "conv9_2_mbox_loc_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
layer {
name: "conv9_2_mbox_loc_flat"
type: "Flatten"
bottom: "conv9_2_mbox_loc_perm"
top: "conv9_2_mbox_loc_flat"
flatten_param {
axis: 1
}
}
layer {
name: "conv9_2_mbox_conf"
type: "Convolution"
bottom: "conv9_2"
top: "conv9_2_mbox_conf"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 16
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "conv9_2_mbox_conf_perm"
type: "Permute"
bottom: "conv9_2_mbox_conf"
top: "conv9_2_mbox_conf_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
layer {
name: "conv9_2_mbox_conf_flat"
type: "Flatten"
bottom: "conv9_2_mbox_conf_perm"
top: "conv9_2_mbox_conf_flat"
flatten_param {
axis: 1
}
}
layer {
name: "conv9_2_mbox_priorbox"
type: "PriorBox"
bottom: "conv9_2"
bottom: "data"
top: "conv9_2_mbox_priorbox"
prior_box_param {
min_size: 264
max_size: 315
aspect_ratio: 2
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
step: 300
offset: 0.5
}
}
layer {
name: "mbox_loc"
type: "Concat"
bottom: "conv4_3_norm_mbox_loc_flat"
bottom: "fc7_mbox_loc_flat"
bottom: "conv6_2_mbox_loc_flat"
bottom: "conv7_2_mbox_loc_flat"
bottom: "conv8_2_mbox_loc_flat"
bottom: "conv9_2_mbox_loc_flat"
top: "mbox_loc"
concat_param {
axis: 1
}
}
layer {
name: "mbox_conf"
type: "Concat"
bottom: "conv4_3_norm_mbox_conf_flat"
bottom: "fc7_mbox_conf_flat"
bottom: "conv6_2_mbox_conf_flat"
bottom: "conv7_2_mbox_conf_flat"
bottom: "conv8_2_mbox_conf_flat"
bottom: "conv9_2_mbox_conf_flat"
top: "mbox_conf"
concat_param {
axis: 1
}
}
layer {
name: "mbox_priorbox"
type: "Concat"
bottom: "conv4_3_norm_mbox_priorbox"
bottom: "fc7_mbox_priorbox"
bottom: "conv6_2_mbox_priorbox"
bottom: "conv7_2_mbox_priorbox"
bottom: "conv8_2_mbox_priorbox"
bottom: "conv9_2_mbox_priorbox"
top: "mbox_priorbox"
concat_param {
axis: 2
}
}
layer {
name: "mbox_loss"
type: "MultiBoxLoss"
bottom: "mbox_loc"
bottom: "mbox_conf"
bottom: "mbox_priorbox"
bottom: "label"
top: "mbox_loss"
include {
phase: TRAIN
}
propagate_down: true
propagate_down: true
propagate_down: false
propagate_down: false
loss_param {
normalization: VALID
}
multibox_loss_param {
loc_loss_type: SMOOTH_L1
conf_loss_type: SOFTMAX
loc_weight: 1
num_classes: 4
share_location: true
match_type: PER_PREDICTION
overlap_threshold: 0.5
use_prior_for_matching: true
background_label_id: 0
use_difficult_gt: true
neg_pos_ratio: 3
neg_overlap: 0.5
code_type: CENTER_SIZE
ignore_cross_boundary_bbox: false
mining_type: MAX_NEGATIVE
}
}
I0422 11:53:44.443205 19129 layer_factory.hpp:77] Creating layer data
I0422 11:53:44.443338 19129 net.cpp:100] Creating Layer data
I0422 11:53:44.443349 19129 net.cpp:408] data -> data
I0422 11:53:44.443374 19129 net.cpp:408] data -> label
I0422 11:53:44.444303 19138 db_lmdb.cpp:35] Opened lmdb examples/KITTI/KITTI_trainval_lmdb
I0422 11:53:44.460831 19129 annotated_data_layer.cpp:62] output data size: 16,3,300,300
I0422 11:53:44.484822 19129 net.cpp:150] Setting up data
I0422 11:53:44.484858 19129 net.cpp:157] Top shape: 16 3 300 300 (4320000)
I0422 11:53:44.484863 19129 net.cpp:157] Top shape: 1 1 1 8 (8)
I0422 11:53:44.484865 19129 net.cpp:165] Memory required for data: 17280032
I0422 11:53:44.484910 19129 layer_factory.hpp:77] Creating layer data_data_0_split
I0422 11:53:44.484937 19129 net.cpp:100] Creating Layer data_data_0_split
I0422 11:53:44.484944 19129 net.cpp:434] data_data_0_split <- data
I0422 11:53:44.484958 19129 net.cpp:408] data_data_0_split -> data_data_0_split_0
I0422 11:53:44.484968 19129 net.cpp:408] data_data_0_split -> data_data_0_split_1
I0422 11:53:44.484975 19129 net.cpp:408] data_data_0_split -> data_data_0_split_2
I0422 11:53:44.485005 19129 net.cpp:408] data_data_0_split -> data_data_0_split_3
I0422 11:53:44.485013 19129 net.cpp:408] data_data_0_split -> data_data_0_split_4
I0422 11:53:44.485018 19129 net.cpp:408] data_data_0_split -> data_data_0_split_5
I0422 11:53:44.485023 19129 net.cpp:408] data_data_0_split -> data_data_0_split_6
I0422 11:53:44.485126 19129 net.cpp:150] Setting up data_data_0_split
I0422 11:53:44.485147 19129 net.cpp:157] Top shape: 16 3 300 300 (4320000)
I0422 11:53:44.485150 19129 net.cpp:157] Top shape: 16 3 300 300 (4320000)
I0422 11:53:44.485153 19129 net.cpp:157] Top shape: 16 3 300 300 (4320000)
I0422 11:53:44.485174 19129 net.cpp:157] Top shape: 16 3 300 300 (4320000)
I0422 11:53:44.485177 19129 net.cpp:157] Top shape: 16 3 300 300 (4320000)
I0422 11:53:44.485180 19129 net.cpp:157] Top shape: 16 3 300 300 (4320000)
I0422 11:53:44.485183 19129 net.cpp:157] Top shape: 16 3 300 300 (4320000)
I0422 11:53:44.485185 19129 net.cpp:165] Memory required for data: 138240032
I0422 11:53:44.485189 19129 layer_factory.hpp:77] Creating layer conv1_1
I0422 11:53:44.485205 19129 net.cpp:100] Creating Layer conv1_1
I0422 11:53:44.485210 19129 net.cpp:434] conv1_1 <- data_data_0_split_0
I0422 11:53:44.485218 19129 net.cpp:408] conv1_1 -> conv1_1
I0422 11:53:45.007372 19129 net.cpp:150] Setting up conv1_1
I0422 11:53:45.007395 19129 net.cpp:157] Top shape: 16 64 300 300 (92160000)
I0422 11:53:45.007398 19129 net.cpp:165] Memory required for data: 506880032
I0422 11:53:45.007426 19129 layer_factory.hpp:77] Creating layer relu1_1
I0422 11:53:45.007442 19129 net.cpp:100] Creating Layer relu1_1
I0422 11:53:45.007447 19129 net.cpp:434] relu1_1 <- conv1_1
I0422 11:53:45.007454 19129 net.cpp:395] relu1_1 -> conv1_1 (in-place)
I0422 11:53:45.007680 19129 net.cpp:150] Setting up relu1_1
I0422 11:53:45.007688 19129 net.cpp:157] Top shape: 16 64 300 300 (92160000)
I0422 11:53:45.007709 19129 net.cpp:165] Memory required for data: 875520032
I0422 11:53:45.007711 19129 layer_factory.hpp:77] Creating layer conv1_2
I0422 11:53:45.007726 19129 net.cpp:100] Creating Layer conv1_2
I0422 11:53:45.007731 19129 net.cpp:434] conv1_2 <- conv1_1
I0422 11:53:45.007737 19129 net.cpp:408] conv1_2 -> conv1_2
I0422 11:53:45.009729 19129 net.cpp:150] Setting up conv1_2
I0422 11:53:45.009742 19129 net.cpp:157] Top shape: 16 64 300 300 (92160000)
I0422 11:53:45.009763 19129 net.cpp:165] Memory required for data: 1244160032
I0422 11:53:45.009773 19129 layer_factory.hpp:77] Creating layer relu1_2
I0422 11:53:45.009781 19129 net.cpp:100] Creating Layer relu1_2
I0422 11:53:45.009789 19129 net.cpp:434] relu1_2 <- conv1_2
I0422 11:53:45.009795 19129 net.cpp:395] relu1_2 -> conv1_2 (in-place)
I0422 11:53:45.009982 19129 net.cpp:150] Setting up relu1_2
I0422 12:14:00.465445 19129 solver.cpp:243] Iteration 840, loss = 4.30929
I0422 12:14:00.465477 19129 solver.cpp:259] Train net output #0: mbox_loss = 4.25927 (* 1 = 4.25927 loss)
I0422 12:14:00.465487 19129 sgd_solver.cpp:138] Iteration 840, lr = 0.0001
I0422 12:14:14.878239 19129 solver.cpp:243] Iteration 850, loss = 4.49961
I0422 12:14:14.878271 19129 solver.cpp:259] Train net output #0: mbox_loss = 4.58178 (* 1 = 4.58178 loss)
I0422 12:14:14.878279 19129 sgd_solver.cpp:138] Iteration 850, lr = 0.0001
I0422 12:14:29.397267 19129 solver.cpp:243] Iteration 860, loss = 4.43597
I0422 12:14:29.397416 19129 solver.cpp:259] Train net output #0: mbox_loss = 4.70289 (* 1 = 4.70289 loss)
I0422 12:14:29.397428 19129 sgd_solver.cpp:138] Iteration 860, lr = 0.0001
I0422 12:14:43.483563 19129 solver.cpp:243] Iteration 870, loss = 4.79228
I0422 12:14:43.483608 19129 solver.cpp:259] Train net output #0: mbox_loss = 5.82301 (* 1 = 5.82301 loss)
I0422 12:14:43.483619 19129 sgd_solver.cpp:138] Iteration 870, lr = 0.0001
I0422 12:14:58.156549 19129 solver.cpp:243] Iteration 880, loss = 4.56616
I0422 12:14:58.156586 19129 solver.cpp:259] Train net output #0: mbox_loss = 5.05384 (* 1 = 5.05384 loss)
I0422 12:14:58.156595 19129 sgd_solver.cpp:138] Iteration 880, lr = 0.0001
I0422 12:15:13.084661 19129 solver.cpp:243] Iteration 890, loss = 4.44497
I0422 12:15:13.084812 19129 solver.cpp:259] Train net output #0: mbox_loss = 4.02057 (* 1 = 4.02057 loss)
I0422 12:15:13.084825 19129 sgd_solver.cpp:138] Iteration 890, lr = 0.0001
I0422 12:15:27.360756 19129 solver.cpp:243] Iteration 900, loss = 4.80043

KITTI自动驾驶所有文件.tar.gz
在上面的压缩包中,由于JPEGImages、lmdb的文件太大在CSDN网站上上传不了,请大家谅解,如有需要可以给我留言。截止于2018年4月22日下午16:04,我的模型还在运行当中,等模型训练好后,后续会贴出测试效果。。。
训练完成
现在时间是2018年4月23日下午13:14 ,我的模型经过16个小时(中间因为batch_size设置为16太大,内存不足中断过。)训练,终于完成了。具体情况如下图所示:
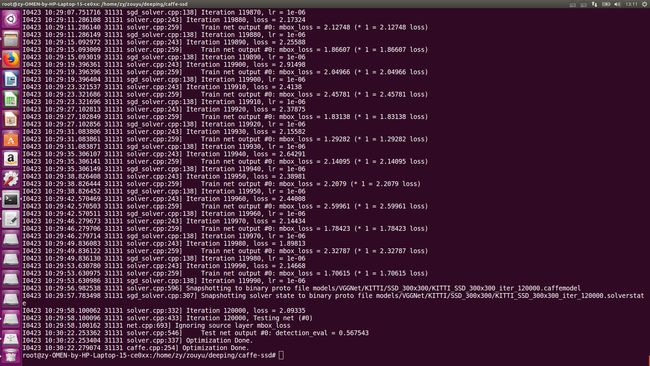

最后的mbox_loss=1.70615,detection_eval=0.567543。通过这个来看,精度不是太高。
我的观点有几个方面 :
1、训练迭代次数不够,要增加迭代数。
2、因为SSD网络的输入图片的原始分辨率与KITTI的图片分辨率可能有出入,需要调整网络结构。
3、可以尝试其它网络结构来对KITTI进行训练。
测试模型
首先放上我自己在本机上测试的源码(文章后面有链接),如果大家要进行测试的话,请自行修改一些图片路径和模型路径。
# coding: utf-8
# # Detection with SSD
#
# In this example, we will load a SSD model and use it to detect objects.
# ### 1. Setup
#
# * First, Load necessary libs and set up caffe and caffe_root
# In[1]:
import cv2
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (10, 10)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# Make sure that caffe is on the python path:
caffe_root = '/home/zy/zouyu/deeping/caffe-ssd/' # this file is expected to be in {caffe_root}/examples
import os
os.chdir(caffe_root)
import sys
sys.path.insert(0, 'python')
import caffe
caffe.set_device(0)
caffe.set_mode_gpu()
# * Load LabelMap.
# In[2]:
from google.protobuf import text_format
from caffe.proto import caffe_pb2
# load PASCAL VOC labels
labelmap_file = 'data/VOC0712/labelmap_kitti.prototxt'
file = open(labelmap_file, 'r')
labelmap = caffe_pb2.LabelMap()
text_format.Merge(str(file.read()), labelmap)
def get_labelname(labelmap, labels):
num_labels = len(labelmap.item)
labelnames = []
if type(labels) is not list:
labels = [labels]
for label in labels:
found = False
for i in xrange(0, num_labels):
if label == labelmap.item[i].label:
found = True
labelnames.append(labelmap.item[i].display_name)
break
assert found == True
return labelnames
# * Load the net in the test phase for inference, and configure input preprocessing.
# In[3]:
model_def ='models/VGGNet/KITTI/SSD_300x300/deploy.prototxt'
model_weights = 'models/VGGNet/KITTI/SSD_300x300/KITTI_SSD_300x300_iter_120000.caffemodel'
net = caffe.Net(model_def, # defines the structure of the model
model_weights, # contains the trained weights
caffe.TEST) # use test mode (e.g., don't perform dropout)
# input preprocessing: 'data' is the name of the input blob == net.inputs[0]
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2, 0, 1))
transformer.set_mean('data', np.array([104,117,123])) # mean pixel
transformer.set_raw_scale('data', 255) # the reference model operates on images in [0,255] range instead of [0,1]
transformer.set_channel_swap('data', (2,1,0)) # the reference model has channels in BGR order instead of RGB
#
#
# ### 2. SSD detection
# * Load an image.
# In[4]:
# set net to batch size of 1
image_resize = 300
net.blobs['data'].reshape(1,3,image_resize,image_resize)
image = caffe.io.load_image('examples/images/000088.png')
image = caffe.io.load_image('examples/images/000095.png')
#image = caffe.io.load_image('examples/images/000098.png')
#plt.imshow(image)
# * Run the net and examine the top_k results
# In[5]:
transformed_image = transformer.preprocess('data', image)
net.blobs['data'].data[...] = transformed_image
# Forward pass.
detections = net.forward()['detection_out']
# Parse the outputs.
det_label = detections[0,0,:,1]
det_conf = detections[0,0,:,2]
det_xmin = detections[0,0,:,3]
det_ymin = detections[0,0,:,4]
det_xmax = detections[0,0,:,5]
det_ymax = detections[0,0,:,6]
# Get detections with confidence higher than 0.6.
top_indices = [i for i, conf in enumerate(det_conf) if conf >= 0.25]
top_conf = det_conf[top_indices]
top_label_indices = det_label[top_indices].tolist()
top_labels = get_labelname(labelmap, top_label_indices)
top_xmin = det_xmin[top_indices]
top_ymin = det_ymin[top_indices]
top_xmax = det_xmax[top_indices]
top_ymax = det_ymax[top_indices]
#
# * Plot the boxes
colors = plt.cm.hsv(np.linspace(0, 1, 21)).tolist()
plt.imshow(image)
currentAxis = plt.gca()
for i in xrange(top_conf.shape[0]):
xmin = int(round(top_xmin[i] * image.shape[1]))
ymin = int(round(top_ymin[i] * image.shape[0]))
xmax = int(round(top_xmax[i] * image.shape[1]))
ymax = int(round(top_ymax[i] * image.shape[0]))
score = top_conf[i]
label = int(top_label_indices[i])
label_name = top_labels[i]
display_txt = '%s: %.2f'%(label_name, score)
coords = (xmin, ymin), xmax-xmin+1, ymax-ymin+1
color = colors[label]
currentAxis.add_patch(plt.Rectangle(*coords, fill=False, edgecolor=color, linewidth=2))
currentAxis.text(xmin, ymin, display_txt, bbox={'facecolor':color, 'alpha':0.5})
plt.show()
其次,看看我的模型训练出来后的测试效果。

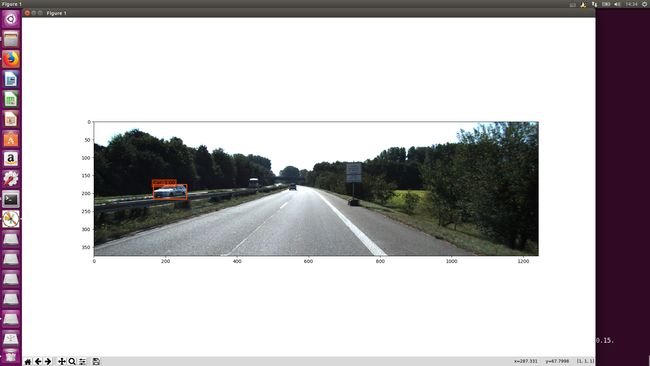
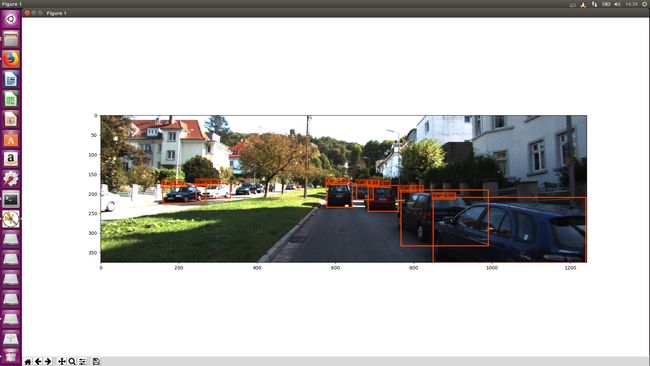
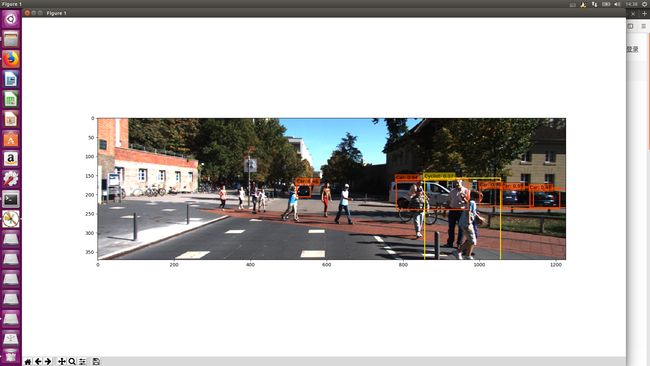
通过上图,我们可以看出,训练出来的模型对于汽车(Car),这个类型 分辨率还可以,而其他两个类型 :行人&自行车 的分辨率有待提升。后续如果有时间,我会继续改进。
总结
本博客以KITTI为基础数据集。从数据的整理、分类、注释等各方面入手,从零到一完成了整个深度学习的过程。在这一过程中碰到了各种各样的问题,有些问题也让人头痛不已。但是我想表达的思想是,只要抱着必胜的信念就一定能够完成我们的工作,让理想照进现实。最后我把我生成的模型文件放在文章的后面供大家参考。谢谢!!!