Flink 集群部署 之 YARN配置(YARN Setup)
目录
快速开始
在YARN上启用一个长连接Flink集群
在YARN上运行一个Flink任务
Flink YARN Session
启动Flink Session
提交Job到Flink
提交一个Flink job到YARN
User jars & Classpath
YARN上Flink任务的恢复行为
Debugging一个失败的YARN session
日志文件
YARN Client控制台和Web接口
构建指定Hadoop版本的YARN client
Running Flink on YARN behind Firewalls
Flink如何向YARN申请资源
快速开始
在YARN上启用一个长连接Flink集群
启动 YARN session,其中 job manager 获得1gb堆空间,task managers 获得分配的4gb堆空间:
# get the hadoop2 package from the Flink download page at
# http://flink.apache.org/downloads.html
curl -O
tar xvzf flink-1.9.0-bin-hadoop2.tgz
cd flink-1.9.0/
./bin/yarn-session.sh -jm 2048m -tm 4096m 使用 -s 为每个 Task Manager 指定处理槽数。我们建议将槽的数量设置为每台机器的处理器数量。
# 查看物理CPU个数
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
# 查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq
# 查看逻辑CPU的个数
cat /proc/cpuinfo| grep "processor"| wc -l会话启动后,您可以使用 ./bin/flink 向集群提交作业。
在YARN上运行一个Flink任务
# get the hadoop2 package from the Flink download page at
# http://flink.apache.org/downloads.html
curl -O
tar xvzf flink-1.9.0-bin-hadoop2.tgz
cd flink-1.9.0/
./bin/flink run -m yarn-cluster -p 4 -yjm 1024m -ytm 4096m ./examples/batch/WordCount.jar Flink YARN Session
Apache Hadoop YARN 是一个集群资源管理框架。它允许在集群上运行各种分布式应用程序。Flink 在其他集群的 YARN 上运行。如果已经有 YARN 安装,用户不需要安装或安装任何东西。
基本需求
- 至少Apache Hadoop 2.2
- HDFS (Hadoop分布式文件系统)(或Hadoop支持的另一个分布式文件系统)
如果您在使用 Flink YARN 客户端时遇到问题,请查阅://TODO。
启动Flink Session
按照以下说明学习如何在 YARN 集群中启动 Flink Session。
一个会话将启动所有必需的 Flink 服务(JobManager和taskmanager),以便可以向集群提交程序。注意,可以在每个会话中运行多个程序。
下载Flink
从下载页面下载 Hadoop 版本 >= 2的Flink包。它包含所需的文件。
tar xvzf flink-1.9.0-bin-hadoop2.tgz
cd flink-1.9.0/开始一个Session
使用以下命令启动会话
./bin/yarn-session.sh该命令将向您显示以下概述:
Usage:
Optional
-D Dynamic properties
-d,--detached Start detached
-jm,--jobManagerMemory Memory for JobManager Container with optional unit (default: MB)
-nm,--name Set a custom name for the application on YARN
-at,--applicationType Set a custom application type on YARN
-q,--query Display available YARN resources (memory, cores)
-qu,--queue Specify YARN queue.
-s,--slots Number of slots per TaskManager
-tm,--taskManagerMemory Memory per TaskManager Container with optional unit (default: MB)
-z,--zookeeperNamespace Namespace to create the Zookeeper sub-paths for HA mode 请注意,客户端需要将 YARN_CONF_DIR 或 HADOOP_CONF_DIR 环境变量设置为读取 YARN 和 HDFS 配置。
示例:使用以下命令启动 YARN Session 集群,其中每个 TM 都使用8gb内存和32个处理槽启动:
./bin/yarn-session.sh -tm 8192 -s 32系统将使用 conf/flink-conf.yaml 中的配置。如果您想更改某些内容,请查阅:Flink部署运维(Deployment & Operations)- Configuration(Flink配置项)。
如果指定了槽数,YARN 上的 Flink 将覆盖以下配置参数 jobmanager.rpc.address(因为JobManager总是分配在不同的机器上),io.tmp.dirs(将使用 YARN 给的 tmp 目录),parallelism.default。
如果不希望更改配置文件来设置配置参数,可以选择通过 -D 传递动态属性。所以可以这样传递参数:-Dfs.overwrite-files=true -Dtaskmanager.network.memory.min=536346624。
示例调用为运行 Job Manager 的 ApplicationMaster 启动一个容器。
会话集群将自动分配额外的容器,这些容器将在作业提交到集群时运行 Task Managers。
一旦 Flink 部署到 YARN 集群中,它将显示 Job Manager 的连接信息。
通过停止unix进程(使用CTRL+C)或在客户机中输入“Stop”来停止 YARN 会话。
只有当集群上的 ApplicationMaster 有足够的资源可用时,才会启动 YARN 上的 Flink。大多数 YARN 调度器占用容器的内存,有些还占用 vcore 的数量。默认情况下,vcore 的数量等于processing slot (-s)参数值。yarn.containers.vcore 允许使用自定义值覆盖 vcore 的数量。为了使该参数生效,您应该在集群中启用 CPU 调度。
分离YARN Session
如果不想让 Flink YARN 客户机一直运行,也可以启动一个独立的 YARN 会话。它的参数为 -d 或 --detached。
在这种情况下,Flink YARN 客户机将只向集群提交 Flink,然后关闭自己。注意,在这种情况下,不可能停止 YARN 会话使用Flink。
使用 YARN 实用程序(YARN 应用程序-kill
添加到已有的Session
使用以下命令启动会话
./bin/yarn-session.sh该命令将向您显示以下概述:
Usage:
Required
-id,--applicationId YARN application Id 如前所述,必须设置 YARN_CONF_DIR 或 HADOOP_CONF_DIR 环境变量来读取 YARN 和 HDFS 配置。
示例:使用以下命令附加到正在运行的 Flink YARN 会话应用程序_1463870264508_0029:
./bin/yarn-session.sh -id application_1463870264508_0029附加到正在运行的会话使用 YARN ResourceManager 来确定 Job Manager RPC 端口。
通过停止unix进程(使用CTRL+C)或在客户机中输入“Stop”来停止 YARN 会话。
提交Job到Flink
使用以下命令向 YARN 集群提交 Flink 程序:
./bin/flink详情请参阅://TODO。
该命令将向您显示一个帮助菜单,如下所示:
[...]
Action "run" compiles and runs a program.
Syntax: run [OPTIONS]
"run" action arguments:
-c,--class Class with the program entry point ("main"
method or "getPlan()" method. Only needed
if the JAR file does not specify the class
in its manifest.
-m,--jobmanager Address of the JobManager (master) to
which to connect. Use this flag to connect
to a different JobManager than the one
specified in the configuration.
-p,--parallelism The parallelism with which to run the
program. Optional flag to override the
default value specified in the
configuration 使用 run 操作向 YARN 提交作业。客户端能够确定 JobManager 的地址。在遇到未知的问题,还可以使用 -m 参数传递 JobManager 地址。JobManager 地址在 YARN 控制台中可见。
Example
wget -O LICENSE-2.0.txt http://www.apache.org/licenses/LICENSE-2.0.txt
hadoop fs -copyFromLocal LICENSE-2.0.txt hdfs:/// ...
./bin/flink run ./examples/batch/WordCount.jar \
--input hdfs:///..../LICENSE-2.0.txt --output hdfs:///.../wordcount-result.txt如果出现以下错误,请确保所有 taskmanager 都已启动:
Exception in thread "main" org.apache.flink.compiler.CompilerException:
Available instances could not be determined from job manager: Connection timed out.您可以在 JobManager web 界面中检查 TM 的数量。此接口的地址打印在 YARN 会话控制台中。
如果 TM 一分钟后还没有出现,您应该使用日志文件来检查这个问题。
提交一个Flink job到YARN
上面的文档描述了如何在Hadoop YARN 环境中启动 Flink 集群。也可以在 YARN 中启动 Flink,仅用于执行单个作业。
Example
./bin/flink run -m yarn-cluster ./examples/batch/WordCount.jarYARN 会话的命令行选项也可以使用 ./bin/flink。它们的前缀是 y 或 yarn (对于长参数选项)。
注意:通过设置环境变量 flink_con_dir,可以为每个作业使用不同的配置目录。要使用此功能,请从 Flink 发行版复制 conf 目录,并修改每个作业的日志记录设置。
注意:可以将 -m yarn-cluster 与一个独立的 YARN 提交(-yd)组合在一起,以“fire and forget”向 YARN 集群执行一个 Flink 作业。在这种情况下,您的应用程序将不会从 ExecutionEnvironment.execute()调用中获得任何累加器结果或异常!
User jars & Classpath
默认情况下,Flink 将在运行单个作业时将用户 jar 包含到系统类路径中。这种行为可以通过 yarn.per-job-cluster.include-user-jar 参数来控制。
将此设置为 DISABLED 时,Flink 将把jar包含在用户类路径中。
用户jar在类路径中的位置可以通过将参数设置为以下参数之一来控制:
ORDER: (default):根据字典顺序将jar添加到系统类路径。FIRST:将jar添加到系统类路径的开头。LAST:将jar添加到系统类路径的末尾。
YARN上Flink任务的恢复行为
Flink 的 YARN 客户端有以下配置参数,用于控制容器发生故障时的行为。这些参数可以从 conf/flink-conf 设置。或在开始 YARN 会话时,使用 -D 参数。
yarn.application-attempts:尝试 ApplicationMaster(及其 TaskManager 容器)的次数。如果该值设置为1(默认值),当应用程序主程序失败时,整个 YARN 会话将失败。较高的值按 YARN 指定应用程序主程序的重启次数。
Debugging一个失败的YARN session
Flink YARN 会话部署可能失败的原因有很多。错误配置的 Hadoop 设置(HDFS 权限、YARN 配置)、版本不兼容(在Cloudera Hadoop 上运行 Flink 和普通 Hadoop 依赖项)或其他错误。
日志文件
在部署过程中 Flink YARN 会话失败的情况下,用户必须依赖 Hadoop YARN 的日志功能。其中最有用的特性是 YARN 日志聚合。要启用它,用户必须设置 YARN。在 yarn-site.xml 文件中,log-aggregation-enable 属性为 true。启用此功能后,用户可以使用以下命令检索(失败的) YARN 会话的所有日志文件。
yarn logs -applicationId 请注意,在会话结束后需要几秒钟,直到出现日志为止。
YARN Client控制台和Web接口
如果运行时发生错误(例如 TM 在一段时间后停止工作),Flink YARN 客户端还会在终端中打印错误消息。
除此之外,还有 YARN Resource Manager web接口(默认端口为8088)。Resource Manager web接口的端口由yarn.resourcemanager.webapp 决定地址配置值。
它允许访问运行 YARN 应用程序的日志文件,并显示故障应用程序的诊断。
构建指定Hadoop版本的YARN client
使用来自Hortonworks、Cloudera或MapR等公司的Hadoop发行版的用户可能不得不针对其特定版本的Hadoop (HDFS)和YARN构建Flink。有关详细信息,请阅读构建说明。
Running Flink on YARN behind Firewalls
一些 YARN 集群使用防火墙来控制集群与网络其他部分之间的网络流量。在这些设置中,Flink 作业只能从集群的网络(防火墙后面)提交到 YARN 会话。如果这对生产使用不可行,Flink允许为其REST端点配置端口范围,用于客户机-集群通信。配置了此范围后,用户还可以向Flink提交跨越防火墙的作业。
指定REST端点端口的配置参数如下:
rest.bind-port
此配置选项接受单个端口(例如:“50010”)、范围(“5000 -50025”)或两者的组合(“50010、50011、50020-50025、50050-50075”)。
请确保配置选项已停止。没有指定端口,因为它优先于 rest 绑定端口,不接受范围。
(Hadoop使用了类似的机制,配置参数名为 yarn.app.mapreduce.am.job.client.port-range。)
Flink如何向YARN申请资源
这一节简要描述了 Flink 和 YARN 是如何相互调度的。
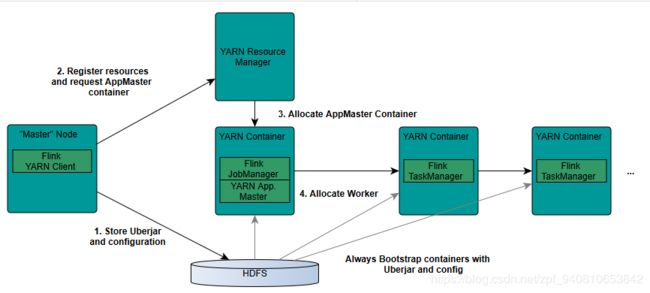
1、YARN 客户端需要访问 Hadoop 配置来连接到 YARN resource manager 和 HDFS。它使用以下策略确定 Hadoop 配置:
- 测试是否设置了 YARN_CONF_DIR、HADOOP_CONF_DIR 或 HADOOP_CONF_PATH(按该顺序)。如果设置了其中一个变量,它将用于读取配置。
- 如果上述策略失败(在正确的 YARN 设置中不应该出现这种情况),客户端将使用 HADOOP_HOME 环境变量。如果设置好了,客户机将尝试访问 $HADOOP_HOME/etc/hadoop (hadoop 2)和 $HADOOP_HOME/conf (hadoop 1)。
2、当开始一个新的Flink YARN 会话时,客户端首先检查所请求的资源(ApplicationMaster的内存和vcore)是否可用。然后,它将一个包含 Flink 和配置的jar上传到HDFS(步骤1)。
3、下一步的客户机请求(步骤2) YARN 容器启动 ApplicationMaster(步骤3)。由于客户端注册的配置和jar文件作为资源容器,YARN 的 NodeManager 特定机器上运行会提前准备容器(如下载文件)。一旦完成,应用程序管理器(AM)就会启动。
4、JobManager 和 AM 运行在同一个容器中。一旦成功启动,AM 就知道 JobManager (它自己的主机)的地址。它正在为 TM 生成一个新的 Flink 配置文件(以便它们可以连接到 JobManager)。该文件也上传到 HDFS。此外,AM 容器还提供 Flink 的 web 接口。YARN 代码分配的所有端口都是临时端口。这允许用户并行执行多个Flink YARN 会话。
5、然后,AM 开始为 Flink 的 TM 分配容器,该 TM 将从 HDFS 下载 jar 文件和修改后的配置。完成这些步骤后,Flink 就被设置好,可以接收 job 了。