关于做Kaggle比赛入门,看完这篇就够了
PART 0 : Kaggle 介绍
Kaggle的数据挖掘比赛近年来很火,以至于中国兴起了很多很多类似的比赛
Kaggle 是一个数据科学竞赛的平台,很多公司会发布一些接近真实业务的问题,吸引爱好数据科学的人来一起解决。
https://www.kaggle.com/
点击导航栏的 competitions 可以看到有很多比赛,其中正式比赛,一般会有奖金或者工作机会,除了正式比赛还有一些为初学者提供的 playground,在这里可以先了解这个比赛,练习能力,再去参加正式比赛。
https://www.kaggle.com/competitions
Kaggle提供了一个介于“完美”与真实之间的过渡,问题的定义基本良好,却夹着或多或少的难点,一般没有完全成熟的解决方案。在参赛过程中与论坛上的其他参赛者互动,能不断地获得启发,受益良多。即使对于一些学有所成的高手乃至大牛,参加Kaggle也常常会获得很多启发,与来着世界各地的队伍进行厮杀的刺激更让人欲罢不能。更重要的是,Kaggle是业界普遍承认的竞赛平台,能从Kaggle上的一些高质量竞赛获取好名次,是对自己实力极好的证明,还能给自己的履历添上光辉的一笔。如果能获得金牌,杀入奖金池,那更是名利兼收,再好不过。
Kaggle适用于以下人群:
- 我是小白,但是对数据科学充满求知欲。
- 我想要历练自己的数据挖掘和机器学习技能,成为一名真正的数据科(lao)学(si)家(ji)。
- 我想赢取奖金,成为人生赢家
如果你从未独立做过一个项目,还是要从练习赛开始熟悉。因为竞赛模式中的任务是公司悬赏发布的实际案例,并没有标准的答案;而练习赛不仅项目难度低,而且是有官方给出的参考方案的,大家可以用来对比改善自己的测试结果,从中进行提高。所以呢,建议感兴趣的同学先去独立做一下101和playground的训练赛,至于做多少个案例才能上道,就要看个人素质啦。这里为大家推荐几篇非常好的文章,里面手把手的教了大家入门级的三个经典练习项目,供大家学习。
1. Titanic(泰坦尼克之灾)
中文教程: 逻辑回归应用之Kaggle泰坦尼克之灾
英文教程:An Interactive Data Science Tutorial
2. House Prices: Advanced Regression Techniques(房价预测)
中文教程:Kaggle竞赛 — 2017年房价预测
英文教程:How to get to TOP 25% with Simple Model using sklearn
3. Digital Recognition(数字识别)
中文教程:大数据竞赛平台—Kaggle 入门
英文教程:Interactive Intro to Dimensionality Reduction
参加 kaggle 最简单的流程就是:
- 第一步:在 Data 里面下载三个数据集,最基本的就是上面提到的三个文件,有些比赛会有附加的数据描述文件等。
- 第二步:自己在线下分析,建模,调参,把用 test 数据集预测好的结果,按照 sample_submission 的格式输出到 csv 文件中。
- 第三步:点击蓝色按钮 ’Submit Predictions’ ,把 csv 文件拖拽进去,然后系统就会加载并检验结果,稍等片刻后就会在 Leaderboard 上显示当前结果所在的排名位置。
PART 1 : 怎么开始
为了方便,我们先定义几个名词:
- Feature 特征变量,也叫自变量,是样本可以观测到的特征,通常是模型的输入。
- Label 标签,也叫目标变量,需要预测的变量,通常是模型的标签或者输出。
- Train Data 训练数据,有标签的数据,由举办方提供。
- Test Data 测试数据,标签未知,是比赛用来评估得分的数据,由举办方提供
- Train Set 训练集,从Train Data中分割得到的,用于训练模型(常用于交叉验证)
- Valid Set 验证集,从Train Data中分割得到的,用于验证模型(常用于交叉验证)
第一步就是要将问题转化为相应的机器学习问题。其中,Kaggle最常见的机器学习问题类型有:
- 回归问题
- 分类问题(二分类、多分类、多标签) 多分类只需从多个类别中预测一个类别,而多标签则需要预测出多个类别。
每种类型的预测会有一点点不同,个人觉得西瓜书还是需要快速看一遍的,不一定说每个公式都要仔仔细细去推导(推导公式对你做比赛基本没有什么帮助),你要知道什么是监督,半监督,非监督等等
然后就是繁复的特征工程了一般这种比赛都有个这么样的流程:

最重要的是在特征工程上,基本你会花上60%的时间在这里,因为在这里你需要做的是数据清洗,异常处理,变换,构造新特征等等,这一套有很详细的教程,给大家贴两个传送门(先别急着看)
-
用sklearn优雅地做特征工程
-
(和上面的一篇同一个作者,我觉得很不错)sklearn做单机特征工程
看完这两篇后,基本你就能做到得心应手地处理数据。
但是,其实在做特征工程之前,你应该先去了解数据,怎么去了解数据呢?这就需要你熟练掌握pandas这个工具了,为什么需要去了解数据呢?因为数据有分布,有不同的业务意义,你通过整理做图可以更加深入理解某些属性的意义,然后构造或是提取出有用的特征。
1.1 数据分析(Data Exploration)
所谓数据挖掘,当然是要从数据中去挖掘我们想要的东西,我们需要通过人为地去分析数据,才可以发现数据中存在的问题和特征。我们需要在观察数据的过程中思考以下几个问题:
- 数据应该怎么清洗和处理才是合理的?
- 根据数据的类型可以挖掘怎样的特征?
- 数据中的哪些特征会对标签的预测有帮助?
1.1.1 统计分析
对于数值类变量(Numerical Variable),我们可以得到min,max,mean,meduim,std等统计量,用pandas可以方便地完成,结果如下:
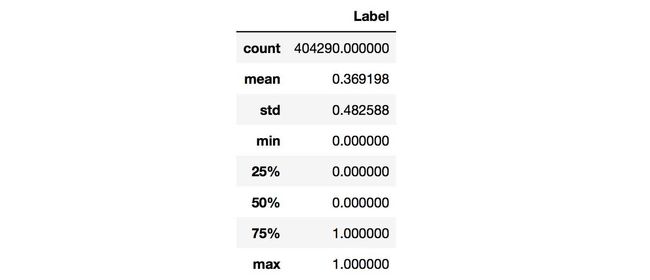
从上图中可以观察Label是否均衡,如果不均衡则需要进行over sample少数类,或者down sample多数类。我们还可以统计Numerical Variable之间的相关系数,用pandas就可以轻松获得相关系数矩阵:
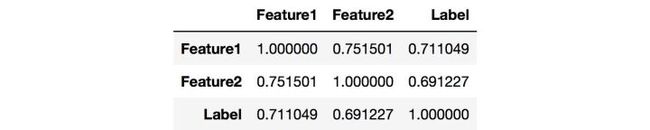
观察相关系数矩阵可以让你找到高相关的特征,以及特征之间的冗余度。而对于文本变量,可以统计词频(TF),TF-IDF,文本长度等等,更详细的内容可以参考这里
1.1.2 可视化
人是视觉动物,更容易接受图形化的表示,因此可以将一些统计信息通过图表的形式展示出来,方便我们观察和发现。比如用直方图展示问句的频数:
或者绘制相关系数矩阵:
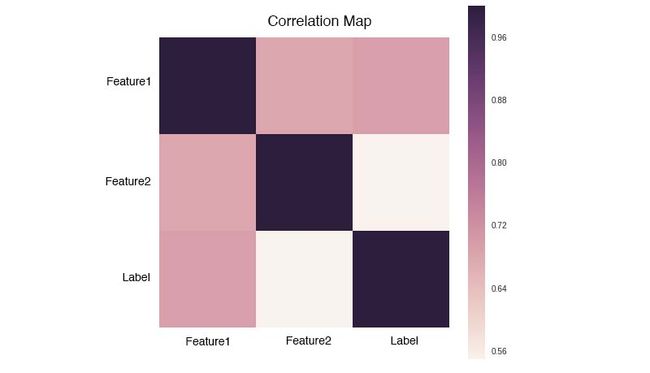
常用的可视化工具有matplotlib和seaborn。当然,你也可以跳过这一步,因为可视化不是解决问题的重点。
1.2 数据预处理(Data Preprocessing)
刚拿到手的数据会出现噪声,缺失,脏乱等现象,我们需要对数据进行清洗与加工,从而方便进行后续的工作。针对不同类型的变量,会有不同的清洗和处理方法:
- 对于数值型变量(Numerical Variable),需要处理离群点,缺失值,异常值等情况。
- 对于类别型变量(Categorical Variable),可以转化为one-hot编码。
- 文本数据是较难处理的数据类型,文本中会有垃圾字符,错别字(词),数学公式,不统一单位和日期格式等。我们还需要处理标点符号,分词,去停用词,对于英文文本可能还要词性还原(lemmatize),抽取词干(stem)等等。
1.3 特征工程(Feature Engineering)
都说特征为王,特征是决定效果最关键的一环。我们需要通过探索数据,利用人为先验知识,从数据中总结出特征。
1.3.1 特征抽取(Feature Extraction)
我们应该尽可能多地抽取特征,只要你认为某个特征对解决问题有帮助,它就可以成为一个特征。特征抽取需要不断迭代,是最为烧脑的环节,它会在整个比赛周期折磨你,但这是比赛取胜的关键,它值得你耗费大量的时间。
那问题来了,怎么去发现特征呢?光盯着数据集肯定是不行的。如果你是新手,可以先耗费一些时间在Forum上,看看别人是怎么做Feature Extraction的,并且多思考。虽然Feature Extraction特别讲究经验,但其实还是有章可循的:
- 对于Numerical Variable,可以通过线性组合、多项式组合来发现新的Feature。
- 对于文本数据,有一些常规的Feature。比如,文本长度,Embeddings,TF-IDF,LDA,LSI等,你甚至可以用深度学习提取文本特征(隐藏层)。
- 如果你想对数据有更深入的了解,可以通过思考数据集的构造过程来发现一些magic feature,这些特征有可能会大大提升效果。在Quora这次比赛中,就有人公布了一些magic feature。
- 通过错误分析也可以发现新的特征(见1.5.2小节)。
1.3.2 特征选择(Feature Selection)
在做特征抽取的时候,我们是尽可能地抽取更多的Feature,但过多的Feature会造成冗余,噪声,容易过拟合等问题,因此我们需要进行特征筛选。特征选择可以加快模型的训练速度,甚至还可以提升效果。
特征选择的方法多种多样,最简单的是相关度系数(Correlation coefficient),它主要是衡量两个变量之间的线性关系,数值在[-1.0, 1.0]区间中。数值越是接近0,两个变量越是线性不相关。但是数值为0,并不能说明两个变量不相关,只是线性不相关而已。
我们通过一个例子来学习一下怎么分析相关系数矩阵:
相关系数矩阵是一个对称矩阵,所以只需要关注矩阵的左下角或者右上角。我们可以拆成两点来看:
- Feature和Label的相关度可以看作是该Feature的重要度,越接近1或-1就越好。
- Feature和Feature之间的相关度要低,如果两个Feature的相关度很高,就有可能存在冗余。
除此之外,还可以训练模型来筛选特征,比如带L1或L2惩罚项的Linear Model、Random Forest、GDBT等,它们都可以输出特征的重要度。在这次比赛中,我们对上述方法都进行了尝试,将不同方法的平均重要度作为最终参考指标,筛选掉得分低的特征。
有时候训练集的类别很不均衡
这个时候需要欠采样或是过采样。
-
欠采样 某个数据比较多的类别随机减少掉一些训练数据
-
过采样 找那些数据少的类别使用smote方法插值添加数据 smote算法
其实数据不平衡的处理也是特征工程的一部分,我这里只是提出来强调了一下,类别不平衡的处理其实还有很多,但是都不常用,大家可以去大概了解了解。
每个特征你都应该取好名字,以防乱了。
另外,由于做模型融合时需要有特征多样性这么一说,所以也许你需要不同的特征簇输入到不同的模型中,所以做好你的文件管理十分重要!!!
我建议你的比赛工程文件如下。
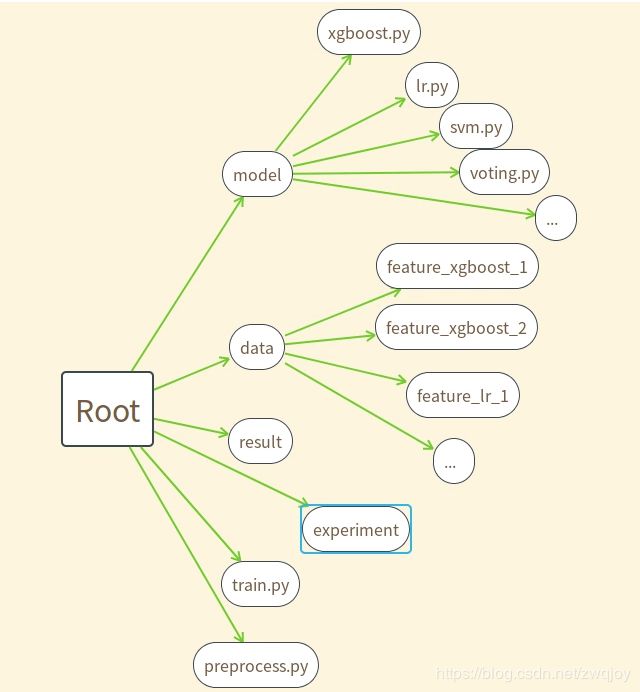
result里面你需也要分好文件夹放不同的结果,这样方便后面模型融合时我们用投票器的方式。
experiment里面是你的jupyter实验文件,因为这类文件你会创建很多,所以最好有一个专门的文件夹来管理。
是不是很简单并且清晰明了,当你学会了sklearn中的pipeline之后,你就可以搭建一个可以轻易修改并给别人看讨论思考过程的工程代码。但是不能完成的是做成一个可以轻易复用到各种比赛的框架。因为每个比赛的数据大不相同。不再多言。
OK!! 走过上面的流程,我们现在进入到part 2的训练阶段吧,这个阶段是最激动人心的,因为你将在这里遇见你特征工程以及模型的不足,然后调优,看着成绩慢慢提高~!
PART 2
模型阶段,在这里,你需要对各种模型都有很清晰的了解,最好是你能够推导公式,不能也算了。
- KNN
- SVM
- Naive Bayes
- Linear Model(带惩罚项)
- ExtraTree
- RandomForest
- Gradient Boost Tree
- Neural Network
- Xgboost
- LightGBM
熟读西瓜书吧,里面从基础开始会让你懂很多,最好是李航的统计学习方法看一遍,这本书比较薄,涵盖的内容却很全,推导也好理解。
幸运的是,这些模型都已经有现成的工具(如scikit-learn、XGBoost、LightGBM等)可以使用,不用自己重复造轮子。但是我们应该要知道各个模型的原理,这样在调参的时候才会游刃有余。当然,你也使用PyTorch/Tensorflow/Keras等深度学习工具来定制自己的Deep Learning模型,玩出自己的花样。
先看一下这篇简单调用: python sklearn常用分类算法模型的调用,你会发现模型用起来好容易好方便~是的,但是这只是开始,别忘记要保存模型哦,另外保存结果也要严格按照规定的文件路径,不然后面你就乱了。
sklearn的编程方式博大精深,但是api使用还是很简单,你只需要花点时间好好学学,就能很熟练了,推荐 python之sklearn学习笔记,这个比官网的教程好看懂,毕竟是中文的嘛...流汗~
再来你还需要去对这些算法调参,这些我就不再谈了,我想着重提一下xgboost,这是一个可以并行运算的回归树,在现在的比赛中用的十分频繁而且有效。
-
XGBoost 原理解析,还不错的blog,我之前也翻译过官方的但是那个太偏理论,这个还有点工程上的见解,还不错
-
我翻译的官网的原理解释 : (XGBoost)提升树入门介绍(Inrtoduction to Boosted Trees)
看懂了后你就会知道为什么这个东西这么牛逼了,当然前提是你需要知道决策树,随机森林的原理。
xgboost运行后的效果一般就很好了,但是这不是最终的,因为xgboost有很多的参数,怎么去调参使得结果更优很重要。
-
XGBoost调参经验(这篇是很好很详细的)
-
余音的xgboost调参经验
在训练模型前,我们需要预设一些参数来确定模型结构(比如树的深度)和优化过程(比如学习率),这种参数被称为超参(Hyper-parameter),不同的参数会得到的模型效果也会不同。总是说调参就像是在“炼丹”,像一门“玄学”,但是根据经验,还是可以找到一些章法的:
- 根据经验,选出对模型效果影响较大的超参。
- 按照经验设置超参的搜索空间,比如学习率的搜索空间为[0.001,0.1]。
- 选择搜索算法,比如Random Search、Grid Search和一些启发式搜索的方法。
- 验证模型的泛化能力
模型验证(Validation)
在Test Data的标签未知的情况下,我们需要自己构造测试数据来验证模型的泛化能力,因此把Train Data分割成Train Set和Valid Set两部分,Train Set用于训练,Valid Set用于验证。
- 简单分割
将Train Data按一定方法分成两份,比如随机取其中70%的数据作为Train Set,剩下30%作为Valid Set,每次都固定地用这两份数据分别训练模型和验证模型。这种做法的缺点很明显,它没有用到整个训练数据,所以验证效果会有偏差。通常只会在训练数据很多,模型训练速度较慢的时候使用。
- 交叉验证
交叉验证是将整个训练数据随机分成K份,训练K个模型,每次取其中的K-1份作为Train Set,留出1份作为Valid Set,因此也叫做K-fold。至于这个K,你想取多少都可以,但一般选在3~10之间。我们可以用K个模型得分的mean和std,来评判模型得好坏(mean体现模型的能力,std体现模型是否容易过拟合),并且用K-fold的验证结果通常会比较可靠。
如果数据出现Label不均衡情况,可以使用Stratified K-fold,这样得到的Train Set和Test Set的Label比例是大致相同。
好了,part 2 也就讲到这里了,其实把这前两个部分好好做,就能取得好的成绩了,第三个部分是后期往上窜一窜的手段,当然不可不用。
PART 3
模型融合
曾经听过一句话,”Feature为主,Ensemble为后”。Feature决定了模型效果的上限,而Ensemble就是让你更接近这个上限。Ensemble讲究“好而不同”,不同是指模型的学习到的侧重面不一样。举个直观的例子,比如数学考试,A的函数题做的比B好,B的几何题做的比A好,那么他们合作完成的分数通常比他们各自单独完成的要高。
常见的Ensemble方法有Bagging、Boosting、Stacking、Blending
-
Kaggle机器学习之模型融合(stacking)心得
-
【机器学习】模型融合方法概述
关于模型融合这一块就看你想怎么弄了,多标签分类这种比较局限,就是投票器,回归的话花样就多了,还能分层搞,所以不怕你想不到,就怕你不尝试。
为了加深你对模型融合的理解和使用,另外推荐三篇:
-
关于bagging和random forest,GDBT以及属性扰动(属性扰动我在西瓜书里看到的,但是实际中我觉得还是不敢用)
-
Bagging与随机森林(这个算是多种方法的一个小总结吧)
-
讲sklearn中的投票器实现,很好,这篇偏讲理论,讲的很不错,可以学到一些东西
PART 4
最后我讲两个trick吧。(没什么道理性的,有时候行,有时不行)
-
找比赛leak,这个就是钻空子吧。通过分析测试集的一些特性找出golden feature(就是一下子能把成绩提高老多的feature)我听大牛的分享里有讲到但是我做比赛时没有想到,很惭愧。
-
利用GDBT或是XGBoost的叶子节点的信息创建出新的特征,一般来讲能提高成绩,但是训练起来贼慢,像我借了好几台电脑,把训练集分散到不同电脑上跑。累死了...
-
利用GDBT的叶子节点信息构造新的特征(原理不是很清楚,Facebook发表的,这篇最后面有些链接可以点进去看,会更明白点)
-
参考:
- 分分钟带你杀入Kaggle Top 1%
-
关于做Kaggle比赛,Jdata,天池的经验,看完我这篇就够了
-
Kaggle 首战拿银总结 | 入门指导 (长文、干货)
-
从0到1走进 Kaggle