CVPR2016 论文快讯:人脸专题
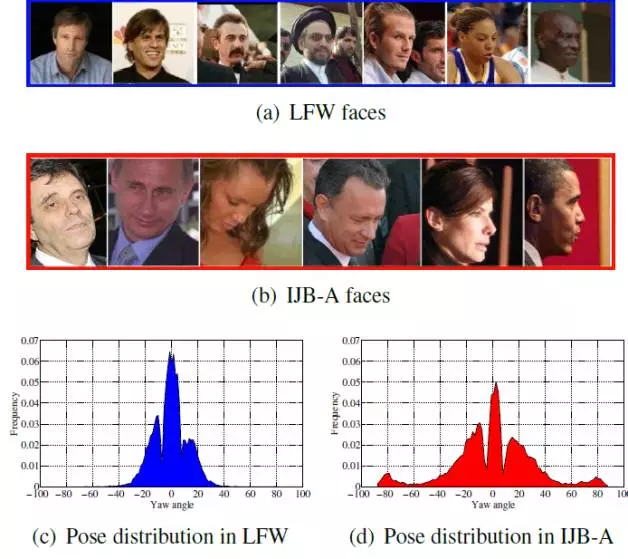
LFW数据库仅包含了部分场景的姿态、背景等变化,而且大部分实验结果都是基于严格提取关键点、人脸矫正后的训练样本和测试样本(今年CVPR做face alignment仍然是个很热门的方向)得到的。对于实际应用中的光照、对比度、抖动、焦点、模糊、遮挡、分辨率、姿态等因素影响人脸识别的复杂因素[12]依然没有得到完全解决。因此,一些更具有挑战性的人脸数据库也发布出来,比如MegaFace、IJB-A等数据库、微软百万名人数据库(不过这个数据库比较noisy)。
此外,视频人脸识别也是目前仍然比较难的一个方向,今年没有出现LSTM或者attention model去做视频中人脸识别的论文,反倒是光流、LSTM做视频中Events, Actions, and Activity Recognition的论文比较多。
本次会议大家可以关注人脸的以下几个点:人脸老龄化预测[1]、人脸的表情捕捉和复现[2]、人脸alignment(偏向于三维alignment、姿态变化较大情况下的alignment)、同时训练的级联CNN做人脸检测[3]、大规模人脸检索问题(度量学习)[4]、深度度量学习(常用于学习得到人脸的具有区分性的特征)[5]、人脸识别问题[6,7,8,9,10,11]、更具挑战性的人脸数据集MegaFace的提出等。
接下来对CVPR2016上与人脸相关的部分文章进行介绍。
一、深度度量学习- Deep Metric Learning via Lifted Structured Feature Embedding
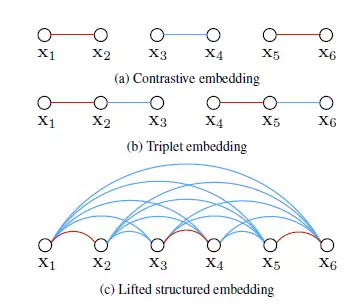 上图中,c是作者论文中挑选数据的示意图,红色表示相同label,蓝色表示不同label。不同于适用于verification的contrastive loss,和利用hard neg和hard positive的做identification的triplet loss,该论文的优化目标如下图,可以看到在选择数据进行训练的时候,作者实际上是利用了pair (i,j)的对应的所有的不同label的人脸信息。这样我们可以在当前batch的优化中,挑选出距离当前对(i,j)最小的负样本,从而使得其距离最大化。同时,也加了使得同类之间距离最小化的限制。
上图中,c是作者论文中挑选数据的示意图,红色表示相同label,蓝色表示不同label。不同于适用于verification的contrastive loss,和利用hard neg和hard positive的做identification的triplet loss,该论文的优化目标如下图,可以看到在选择数据进行训练的时候,作者实际上是利用了pair (i,j)的对应的所有的不同label的人脸信息。这样我们可以在当前batch的优化中,挑选出距离当前对(i,j)最小的负样本,从而使得其距离最大化。同时,也加了使得同类之间距离最小化的限制。
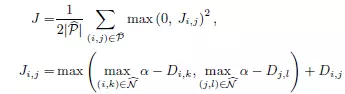
2. CP-mtML: Coupled Projection Multi-Task Metric Learning for Large Scale Face Retrieval
二、人脸识别
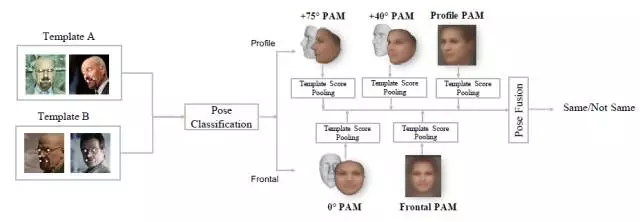
1. Pose-Aware Face Recognition in the Wild 这篇文章来自南加州大学Iacopo Masi,主要关注点在于人脸识别中的大姿态变化问题。不同于当前大部分利用单一模型通过大量训练数据,或者矫正人脸到正脸来学习姿态不变性的方法。作者通过使用五个指定角度模型和渲染人脸图片的方法处理姿态变化。作者主要利用的数据集是IJB-A数据库,同时对比了其与LFW的挑战性不同。
给定一个需要验证的模版对,每张图片都经过一个姿态分类器,然后不同的姿态输入到不同的CNN模型,从而提取到特征,并且匹配以得到分数。对于正面和侧面都有一个平面内对齐,对于0度角、40独角侧面、75度角侧面都有一个平面外旋转矫正。
2.Multi-view Deep Network for Cross-view Classification 这篇文章来自中科院计算所山世光老师组Meina Kan的工作。类似于上篇论文,也是针对人脸识别中的跨视图或跨姿态问题提出对应的解决办法,这篇论文尝试移除人脸数据之间的跨模态差异性,并且找寻跨模态之间的非线性的差异性和模态不变性表达。
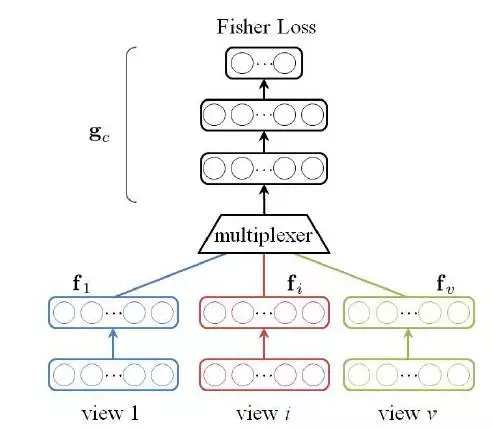
作者提出的MvDN模型,由两个子网络组成。模态特定子网络(view-specific subnetwork)用于移除指定模态的差异性,注意这里的多个自网络1,2,...,v是多路复用的方式,也就是说公共子网络独立的连接到指定模态的子网络。接下来的公共子网络(common subnetwork)用于获取所有模态的公共特征表达。作者使用Rayleigh quotient objective来学习整个网络。目标函数如下,
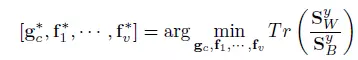 其中样本类内离散度表示为下图,最小化类内离散度矩阵确保了跨模态之间的同类样本间的距离更近。
其中样本类内离散度表示为下图,最小化类内离散度矩阵确保了跨模态之间的同类样本间的距离更近。
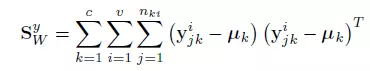 样本类间离散度表示为下图,这样可以最大化跨模态不同类之间的距离。
样本类间离散度表示为下图,这样可以最大化跨模态不同类之间的距离。
3. Sparsifying Neural Network Connections for Face Recognition
这篇文章来自香港中文汤晓鸥老师组Yi Sun大神的作品,在此膜一膜。早在DeepID2+里面,作者就做过sparse的一些解释,认为稀疏性对于卷积神经网络应用于人脸识别效果有提升。最近一年多,关于pruning(英伟达和斯坦福合作的论文[17])和sparse应用于深度学习的文章比较多,也是神经网络优化的一个重要方向。这篇文章实际上是应该有类似于stacked Auto-Encoder的逐层单独训练得到初始化参数的灵感。

作者以迭代的方式来稀疏convnet,每次仅仅对其中一层加稀疏限制,得到的整个模型作为下次迭代的初始化参数。作者从最后一个卷积层开始加稀疏限制,并且固定前面几层的参数。然后对倒数第二层局部连接层加稀疏限制,固定其他层的参数。依次从后往前。作者之所以先删除高层的连接的原因是因为,全连接层和局部连接层在深度模型中有大量的参数,而这些层里面的大量参数都是冗余的。同时Yi Sun也提到了具体如何用caffe去实现相关操作。
4. The MegaFace Benchmark: 1 Million Faces for Recognition at Scale
这篇论文来自华盛顿大学的大规模人脸识别测试数据集。MegaFace资料集包含一百万张图片,代表690000个独特的人。这是第一个在一百万规模级别的面部识别算法测试基准。
现有脸部识别系统仍难以准确识别超过百万的数据量。为了比较现有公开脸部识别算法的准确度,华盛顿大学在去年年底开展了一个名为“MegaFace Challenge”的公开竞赛。这个项目旨在研究当数据库规模提升数个量级时,现有的脸部识别系统能否维持可靠的准确率。
下图是人脸识别常用数据库的规模介绍。
 5. Latent Factor Guided Convolutional Neural Networks for Age-Invariant Face Recognition
5. Latent Factor Guided Convolutional Neural Networks for Age-Invariant Face Recognition
这篇论文来自中国科学院深圳先进技术研究院,主要介绍如何年龄不变性人脸识别(AIFR)。作者在几个常用的人脸老龄化数据集上面做了实验,比如MORPH Album2, FGNET, CACD-VS。在CACD-VS数据库上超过了人类投票识别的结果。
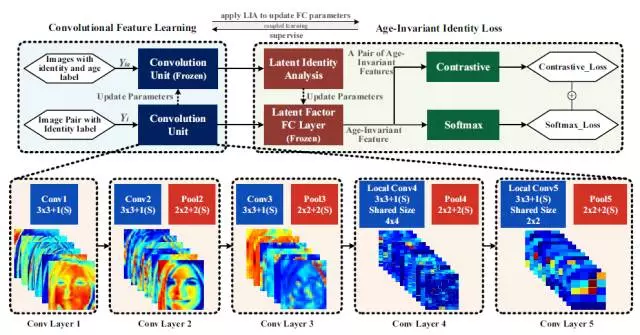
上图介绍了作者提出的LF-CNN以及训练过程,前面三个卷积层是正常的卷积,后面的两个卷积层是局部卷积层(最先在deepface论文中提出),作者用的激活函数是PReLU,同时使用Latent Identity Analysis (LIA)方法来学习全连接层部分的参数。
作者分别使用了两部分数据来训练这两个并行的网络,第一部分是用于学习全连接层参数标注年龄和身份label的数据,第二部分是用于学习卷积层参数的只标注了身份label的数据。整个训练过程中,学习卷积层参数的时候,全连接层参数固定,并且最后既使用softmax loss,又使用contrastive loss。在学习全连接层参数的时候,卷积层的参数固定。具体的全连接层参数的学习过程可以参见论文以及下图,具体不做赘述。

三、人脸老龄化
1. Recurrent Face Aging
这篇文章是意大利特伦托大学的论文,也是CVPR2016的oral paper,主要是做人脸老龄化预测。以下图是作者论文模型的效果示意图,最左边一列是输入的图片,其他的几列分别是模型产生的更老龄化的人脸。

作者认为传统的将年龄分组成离散组合,然后对于每个来源于相邻的年龄段组成的人脸对进行单步的特征映射方法忽略了相邻年龄段之间的in-between evolving states。由于人脸老龄化是一个平缓的过程,所以作者认为通过平缓的转换变换更合适。因此,作者利用两层的门循环单元作为基本循环模块,其中的底层将一个年轻的人脸编码成隐式表达,顶层用于将隐式特征表达解码成相应的更老的人脸。

作者使用两个步骤来进行操作。第一步是人脸归一化,第二步是老龄化模式学习。作者通过迭代优化特征脸和光流估计的方法来做人脸归一化。循环人脸老化模块如上图所示,利用RNN来建模相邻年龄段之间的老化模块。RFA通过之前状态人脸来产生进一步老化的人脸。训练好后,我们可以通过0-5岁年龄段图片的输入,一步步得到61-80年龄段的人脸老龄化预测结果。
2. Ordinal Regression With Multiple Output CNN for Age Estimation
四、表情捕捉、复现
1. Face2Face: Real-time Face Capture and Reenactment of RGB Videos
先来看段振奋人心的demo展示吧。实现表情捕捉,然后复现input video的表情。 http://weibo.com/p/23044490fdc7728d1859aff62fb4ca62f2eba8[一个小故事,当时cvpr2016现场,作者打算演示下demo,结果打开visual studio之后,就崩了o(〃'▽'〃)o] 女生的表情作为输入源,将其表情map到施瓦辛格脸上。

这篇论文也是CVPR2016的oral paper。论文中能够实时重现一个人说话时的动作和表情,并将其映射到(视频中)另外一个人的脸上。该软件有一个强大的研究团队,包括来自普朗克信息学研究所(Max Planck Institute for Informatics)、埃朗根纽伦堡大学(University of Erlangen-Nuremberg)和斯坦福大学的研究人员。
这个技术的原理是通过一种密集光度一致性办法(Dense Photometric Consistency measure),达到跟踪源和目标视频中脸部表情的实时转换,由于间隔的时间很短,使得“复制”面部表情成为可能,但现在还没办法实现声音也一样模仿出来。[由于对这部分不是很了解,所以部分摘自新闻信息(〜^㉨^)〜]
五、人脸检测
1.Joint Training of Cascaded CNN for Face Detection2. WIDER FACE: A Face Detection Benchmark
六、人脸对齐
1. Face Alignment Across Large Poses: A 3D Solution.2. Unconstrained Face Alignment via Cascaded Compositional Learning.3. Occlusion-Free Face Alignment: Deep Regression Networks Coupled With De-Corrupt AutoEncoders.4. Mnemonic Descent Method: A Recurrent Process Applied for End-To-End Face Alignment.5. Large-Pose Face Alignment via CNN-Based Dense 3D Model Fitting.
七、人脸重建
1. Automated 3D Face Reconstruction From Multiple Images Using Quality Measures.2. A Robust Multilinear Model Learning Framework for 3D Faces.3. Adaptive 3D Face Reconstruction From Unconstrained Photo Collections.4. A 3D Morphable Model Learnt From 10,000 Faces.
结语
总的来说,CVPR2016会议中关于人脸的论文仍然有很多,涉及到计算机视觉,图形学,深度学习等等方面,CVPR的工业界展示上面,也有很多令人振奋的demo。很多厂商都参展了,比如百度IDL,腾讯优图,商汤,格灵深瞳,旷视科技等。除了本文提到的论文,感兴趣的同学和老师可以在CVPR2016官网查询更多论文: http://cvpr2016.thecvf.com/program/main_conference 所有pdf版本友善版下载链接: http://www.cv-foundation.org/openaccess/CVPR2016.py 已开源的所有论文code的下载链接: https://tensortalk.com/?cat=conference-cvpr-2016&t=type-code
致谢本文作者特别感谢中科院计算所阚美娜副研究员对本文的修改和建设性意见。
参考文献[1] Wang W, Cui Z, Yan Y, et al. Recurrent Face Aging[J].[2] Thies J, Zollhöfer M, Stamminger M, et al. Face2face: Real-time face capture and reenactment of rgb videos[J]. Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2016, 1.[3] Qin H, Yan J, Li X, et al. Joint Training of Cascaded CNN for Face Detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 3456-3465.[4]CP-mtML: Coupled Projection Multi-Task Metric Learning for Large Scale Face Retrieval.[5] Song H O, Xiang Y, Jegelka S, et al. Deep metric learning via lifted structured feature embedding[J]. arXiv preprint arXiv:1511.06452, 2015.[6] Masi I, Rawls S, Medioni G, et al. Pose-Aware Face Recognition in the Wild[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 4838-4846.[7] Kan M, Shan S, Chen X. Multi-view Deep Network for Cross-view Classification[J].[8] Sun Y, Wang X, Tang X. Sparsifying Neural Network Connections for Face Recognition[J]. arXiv preprint arXiv:1512.01891, 2015.[9] Feng Q, Zhou Y, Lan R. Pairwise Linear Regression Classification for Image Set Retrieval[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 4865-4872.[10] Kemelmacher-Shlizerman I, Seitz S, Miller D, et al. The megaface benchmark: 1 million faces for recognition at scale[J]. arXiv preprint arXiv:1512.00596, 2015. [11] Wen Y, Li Z, Qiao Y. Latent Factor Guided Convolutional Neural Networks for Age-Invariant Face Recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 4893-4901.[12] Abaza A, Harrison M A, Bourlai T. Quality metrics for practical face recognition[C]//Pattern Recognition (ICPR), 2012 21st International Conference on. IEEE, 2012: 3103-3107.[13] Taigman Y, Yang M, Ranzato M A, et al. Deepface: Closing the gap to human-level performance in face verification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2014: 1701-1708.[14]Sun Y, Chen Y, Wang X, et al. Deep learning face representation by joint identification-verification[C]//Advances in Neural Information Processing Systems. 2014: 1988-1996.[15]Hadsell R, Chopra S, LeCun Y. Dimensionality reduction by learning an invariant mapping[C]//2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'06). IEEE, 2006, 2: 1735-1742.[16] Schroff F, Kalenichenko D, Philbin J. Facenet: A unified embedding for face recognition and clustering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 815-823.[17] Han S, Pool J, Tran J, et al. Learning both weights and connections for efficient neural network[C]//Advances in Neural Information Processing Systems. 2015: 1135-1143.
作者简介
 汤旭
汤旭
上海科技大学信息学院研究生二年级,导师为“青年千人”高盛华教授。百度深度学习研究院人脸组实习生。研究方向为深度学习与计算机视觉(人脸识别等),个人邮箱:[email protected]