用户流失预测——基于逻辑回归模型以及Python代码实现
研究目的
有效预测当前用户是否流失,针对高价值的潜在流失用户进行精细化运营以此挽留目标用户。
用户流失预测
2.1用户流失定义
流失用户:上一个周期有下单而本周期没有下单的用户
非流失用户:上一个周期和本周期都有下单的用户
2.2用户流失率
以一个季度为周期,用户流失率指的是上一个周期有下单而本周期没有下单的用户数与上一个周期有下单的用户之比。
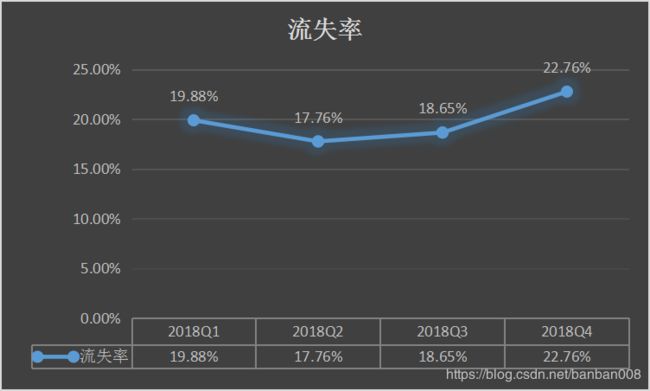
下图为近四个周期的用户流失率,平均流失率为19.76%。
2.3 用户流失分布
2.4指标设计
根据用户流失的原因整理出预测用户流失的指标。略
2.5用户流失预测模型
2.5.1数据预处理
本次实验选取的是2018年1月1日到2018年12月31日之间的用户订单相关的数据,共计X个用户。流失用户与非流失用户之比约为1:10。 按照5:1划分训练集与测试集数据。
将指标归一化处理
2.5.2相关性检验
采用person相关系数检验变量间的相关性,根据下表判断变量相关的强弱关系。
| 相关系数 | 强弱关系 |
|---|---|
| 0.8-1.0 | 极强相关 |
| 0.6-0.8 | 强相关 |
| 0.4-0.6 | 中等程度相关 |
| 0.2-0.4 | 弱相关 |
| 0.0-0.2 | 极弱相关或无相关 |
得出用户流失特征的相关系数矩阵

将上表中相关系数>0.7的指标按照加权平均法合并,合并后的相关系数矩阵,大部分指标系数相关性较低
2.5.3模型搭建
采用sklearn的逻辑回归分类器
2.5.4模型评价
| 混肴矩阵 | 预测1 | 预测0 |
|---|---|---|
| 实际1 | 4000 | 2000 |
| 实际0 | 3000 | 30000 |
正确率为4000/(4000+2000) = 66.67%,召回率= 4000/(4000+ 3000) = 57.14%
模型召回率较低,我们希望模型的召回率高一些。
2.5.5模型优化
- 样本数不均衡
- 根据类别的样本量计算权重,比如用户流失的样本量少,则权重高于非流失用户
- 增加流失样本的浓度,减少非流失用户数量,使得流失与非流失之比为1:1
- 正则化
将L2正则化方法改成L1正则化,让一些不重要的特征系数归零,从而让模型系数稀疏
python实现代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
import math
plt.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
#取消科学计数法
pd.set_option('display.float_format', lambda x: '%.3f' % x) #显示小数
file_path = 'churn.csv'
origin_dataset = pd.read_csv(file_path)
dataset.describe() #指标的描述统计分析,比如最大值,最小值,均值,标准差
dataset.info() #查看指标的记录数,数据类型
dataset = dataset.fillna(0) #缺失值填充
特征分布作图
plt.figure(figsize=(15,15))
plt.subplot2grid((3,3),(0,0))
users_sample.is_churn.value_counts().plot(kind='bar')
plt.title('用户流失分布')
plt.ylabel('用户数')
plt.subplot2grid((3,3),(0,1))
users_sample.tt_cnt[users_sample.tt_cnt>0].plot(kind='hist')
plt.title('用户XXX数')
plt.ylabel('用户数')
plt.subplot2grid((3,3),(0,2))
users_sample.user_cancel_rate[users_sample.user_cancel_rate>0].plot(kind='hist')
plt.title('用户XXXXX率')
plt.ylabel('用户数')
plt.subplot2grid((3,3),(1,0))
users_sample.auto_cancel_rate[users_sample.auto_cancel_rate>0].plot(kind='hist')
plt.title('XXXXXX率')
plt.ylabel('用户数')
plt.subplot2grid((3,3),(1,1))
users_sample.complaint_apply_rate[users_sample.complaint_apply_rate>0].plot(kind='hist')
plt.title('XXXX率')
plt.ylabel('用户数')
plt.subplot2grid((3,3),(1,2))
users_sample.reserve_timely_rate[users_sample.reserve_timely_rate>0].plot(kind='hist')
plt.title('XXXX率')
plt.ylabel('用户数')
归一化
#获取最大值,箱式图 上边缘 = Q3 + N*(Q3-Q1)
def maximum_by_box(data, column_name, n_times):
df = data[data[column_name]!=0][column_name]
q1 = df.quantile(0.25)
q3 = df.quantile(0.75)
minimum = q3 - (q3-q1)*n_times
maximum = q3 + (q3-q1)*n_times
return minimum, maximum
#自定义归一化方式
def standardize(x):
return (x - np.mean(x))/(np.std(x))
def normalize(x, max_x):
if x == 0:
return 0
elif x >= max_x:
return 1
normal_x = np.log10(x)/ np.log10(max_x)
return normal_x
# 针对某个指标归一化
min_x , max_x = maximum_by_box(users_sample,'avg_offer_cnt',1.5)
avg_offer_cnt_normal = users_sample['avg_offer_cnt'].apply(normalize, max_x=max_x)
var_normal = pd.concat([avg_complaint_response_time_scale, avg_arbi_response_time_scale,avg_offer_cnt_normal, avg_within_1hour_offer_cnt_normal,avg_submit_first_offer_time_normal], axis=1)
var_normal.columns = ['avg_complaint_response_time_scale', 'avg_arbi_response_time_scale','avg_offer_cnt_normal', 'avg_within_1hour_offer_cnt_normal','avg_submit_first_offer_time_normal']
# 加上归一化后的指标
dataset_normal = pd.concat([users_sample, var_normal ], axis=1)
variables = dataset_normal.drop(['season','a1','is_churn','tt_cnt','paid_cnt','avg_complaint_response_time','avg_arbi_response_time','avg_offer_cnt','avg_within_1hour_offer_cnt','avg_submit_first_offer_time'], axis=1) #去掉未归一化的指标
相关系数
#导出相关系数
var_corr = variables.corr()
pd.DataFrame(var_corr).to_excel('churn_corr2.xlsx')
# 合并列
def merge_columns(group, col_list):
n = len(col_list)
group_sum = 0
for col in col_list:
group_sum += group[col]
return group_sum / n
#合并相关系数高的字段
serve_finish_timely = variables.apply(merge_columns, col_list=['reserve_timely_rate', 'sign_timely_rate', 'finish_48h_rate'], axis=1)
paid_discount = variables.apply(merge_columns, col_list=['coupon_paid_rate', 'third_paid_rate', 'security_fund_paid_rate'], axis=1)
open_offer = variables.apply(merge_columns, col_list=['avg_offer_cnt_normal', 'avg_within_1hour_offer_cnt_normal', 'avg_submit_first_offer_time_normal'], axis=1)
add_merge_variables = pd.concat([serve_finish_timely,paid_discount,open_offer], axis=1)
add_merge_variables.columns = ['serve_finish_timely','paid_discount','open_offer']
merge_variables = pd.concat([variables,add_merge_variables], axis=1)
模型拟合
from sklearn.linear_model import LogisticRegression as LR
from sklearn.model_selection import train_test_split
import copy
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import cross_val_score
input_variables = copy.deepcopy(merge_variables)
#按照3:1划分训练集和测试集
X = input_variables.drop(['is_churn'], axis=1)
Y = input_variables.is_churn
X_train, X_test, Y_train, Y_test = train_test_split(X,Y, test_size=0.25, random_state=14)
model = LR( C=1,solver='liblinear') # solver='liblinear'
model.fit(X_train, Y_train)
#交叉检验
accuracys = cross_val_score(model, X_train, Y_train, scoring=None, cv=10, n_jobs=1)
print(accuracys)
roc_score = cross_val_score(model, X_train, Y_train, scoring='roc_auc', cv=10, n_jobs=1)
print(roc_score)
# 预测测试数据集
Y_predict = model.predict(X_test)
#评价方式
accuracy = model.score(X_test, Y_test) #=np.mean(Y_predict == Y_test)*100
print(accuracy)
#混肴矩阵
confusion_matrix(Y_test, Y_predict)
# 预测结果与真实结果的作图比较
plt.subplot2grid((1,2), (0,0))
pd.DataFrame(Y_predict)[0].value_counts().plot(kind='bar')
plt.title("预测结果分布")
plt.ylabel('用户数')
plt.subplot2grid((1,2), (0,1))
pd.DataFrame(Y_test)['is_churn'].value_counts().plot(kind='bar')
plt.title("实际结果分布")
plt.ylabel('用户数')
plt.savefig('result.png')