http://www.cnblogs.com/zackyang/archive/2012/02/08/2342141.html
http://blog.chinaunix.net/uid-20737871-id-3491415.html
http://smilejay.com/2012/02/irq_affinity/
http://flash520.blog.163.com/blog/static/344144752010730103640949/
http://www.cnblogs.com/Bozh/archive/2013/01/17/2864201.html
http://blog.chinaunix.net/uid-20737871-id-3600093.html
http://www.cnblogs.com/Bozh/archive/2013/03/21/2973769.html
http://blog.chinaunix.net/uid-26642180-id-3131179.html
Linux技巧:多核下绑定硬件进程到不同CPU
硬件中断发生频繁,是件很消耗 CPU 资源的事情,在多核 CPU 条件下如果有办法把大量硬件中断分配给不同的 CPU (core) 处理显然能很好的平衡性能。现在的服务器上动不动就是多 CPU 多核、多网卡、多硬盘,如果能让网卡中断独占1个 CPU (core)、磁盘 IO 中断独占1个 CPU 的话将会大大减轻单一 CPU 的负担、提高整体处理效率。我前天收到一位网友的邮件提到了 SMP IRQ Affinity,引发了今天的话题。以下操作在 SUN FIre X2100 M2 服务器+ 64位版本 CentOS 5.5 + Linux 2.6.18-194.3.1.el5 上执行。
什么是中断
中文教材上对 “中断” 的定义太生硬了,简单的说就是,每个硬件设备(如:硬盘、网卡等)都需要和 CPU 有某种形式的通信以便 CPU 及时知道发生了什么事情,这样 CPU 可能就会放下手中的事情去处理应急事件,硬件设备主动打扰 CPU 的现象就可称为硬件中断,就像你正在工作的时候受到 QQ 干扰一样,一次 QQ 摇头就可以被称为中断。
中断是一种比较好的 CPU 和硬件沟通的方式,还有一种方式叫做轮询(polling),就是让 CPU 定时对硬件状态进行查询然后做相应处理,就好像你每隔5分钟去检查一下 QQ 看看有没有人找你一样,这种方式是不是很浪费你(CPU)的时间?所以中断是硬件主动的方式,比轮询(CPU 主动)更有效一些。
好了,这里又有了一个问题,每个硬件设备都中断,那么如何区分不同硬件呢?不同设备同时中断如何知道哪个中断是来自硬盘、哪个来自网卡呢?这个很容易,不是每个 QQ 号码都不相同吗?同样的,系统上的每个硬件设备都会被分配一个 IRQ 号,通过这个唯一的 IRQ 号就能区别张三和李四了。
在计算机里,中断是一种电信号,由硬件产生,并直接送到中断控制器(如 8259A)上,然后再由中断控制器向 CPU 发送信号,CPU 检测到该信号后,就中断当前的工作转而去处理中断。然后,处理器会通知操作系统已经产生中断,这样操作系统就会对这个中断进行适当的处理。现在来看一下中断控制器,常见的中断控制器有两种:可编程中断控制器 8259A 和高级可编程中断控制器(APIC),中断控制器应该在大学的硬件接口和计算机体系结构的相关课程中都学过。传统的 8259A 只适合单 CPU 的情况,现在都是多 CPU 多核的 SMP 体系,所以为了充分利用 SMP 体系结构、把中断传递给系统上的每个 CPU 以便更好实现并行和提高性能,Intel 引入了高级可编程中断控制器(APIC)。
光有高级可编程中断控制器的硬件支持还不够,Linux 内核还必须能利用到这些硬件特质,所以只有 kernel 2.4 以后的版本才支持把不同的硬件中断请求(IRQs)分配到特定的 CPU 上,这个绑定技术被称为 SMP IRQ Affinity. 更多介绍请参看 Linux 内核源代码自带的文档:linux-2.6.31.8/Documentation/IRQ-affinity.txt
如何使用
先看看系统上的中断是怎么分配在 CPU 上的,很显然 CPU0 上处理的中断多一些:
# cat /proc/interrupts
CPU0 CPU1
0: 918926335 0 IO-APIC-edge timer
1: 2 0 IO-APIC-edge i8042
8: 0 0 IO-APIC-edge rtc
9: 0 0 IO-APIC-level acpi
12: 4 0 IO-APIC-edge i8042
14: 8248017 0 IO-APIC-edge ide0
50: 194 0 IO-APIC-level ohci_hcd:usb2
58: 31673 0 IO-APIC-level sata_nv
90: 1070374 0 PCI-MSI eth0
233: 10 0 IO-APIC-level ehci_hcd:usb1
NMI: 5077 2032
LOC: 918809969 918809894
ERR: 0
MIS: 0
为了不让 CPU0 很累怎么把部分中断转移到 CPU1 上呢?或者说如何把 eth0 网卡的中断转到 CPU1 上呢?先查看一下 IRQ 90 中断的 smp affinity,看看当前中断是怎么分配在不同 CPU 上的(ffffffff 意味着分配在所有可用 CPU 上):
# cat /proc/irq/90/smp_affinity
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
在进一步动手之前我们需要先停掉 IRQ 自动调节的服务进程,这样才能手动绑定 IRQ 到不同 CPU,否则自己手动绑定做的更改将会被自动调节进程给覆盖掉。如果想修改 IRQ 90 的中断处理,绑定到第2个 CPU(CPU1):
# /etc/init.d/irqbalance stop
# echo "2" > /proc/irq/90/smp_affinity
过段时间在看 /proc/interrupts,是不是 90:eth0 在 CPU1 上的中断增加了(145)、在 CPU0 上的中断没变?不断打印 /proc/interrupts 就会发现 eth0 在 CPU0 上的中断数始终保持不变,而在 CPU1 上的中断数是持续增加的,这正是我们想要的结果:
# cat /proc/interrupts
CPU0 CPU1
0: 922506515 0 IO-APIC-edge timer
1: 2 0 IO-APIC-edge i8042
8: 0 0 IO-APIC-edge rtc
9: 0 0 IO-APIC-level acpi
12: 4 0 IO-APIC-edge i8042
14: 8280147 0 IO-APIC-edge ide0
50: 194 0 IO-APIC-level ohci_hcd:usb2
58: 31907 0 IO-APIC-level sata_nv
90: 1073399 145 PCI-MSI eth0
233: 10 0 IO-APIC-level ehci_hcd:usb1
NMI: 5093 2043
LOC: 922389696 922389621
ERR: 0
MIS: 0
有什么用
在网络非常 heavy 的情况下,对于文件服务器、高流量 Web 服务器这样的应用来说,把不同的网卡 IRQ 均衡绑定到不同的 CPU 上将会减轻某个 CPU 的负担,提高多个 CPU 整体处理中断的能力;对于数据库服务器这样的应用来说,把磁盘控制器绑到一个 CPU、把网卡绑定到另一个 CPU 将会提高数据库的响应时间、优化性能。合理的根据自己的生产环境和应用的特点来平衡 IRQ 中断有助于提高系统的整体吞吐能力和性能。
本人经常收到网友来信问到如何优化 Linux、优化 VPS、这个问题不太好回答,要记住的是性能优化是一个过程而不是结果,不是看了些文档改了改参数就叫优化了,后面还需要大量的测试、监测以及持续的观察和改进。
绑定进程到不同CPU
介绍了在 Linux 多核下如何绑定硬件中断到不同 CPU,其实也可以用类似的做法把进程手动分配到特定的 CPU 上,平时在 Linux 上运行的各种进程都是由 Linux 内核统一分配和管理的,由进程调度算法来决定哪个进程可以开始使用 CPU、哪个进程需要睡眠或等待、哪个进程运行在哪个 CPU 上等。如果你对操作系统的内核和进程调度程序感兴趣的话,不妨看看那本经典的 Operating Systems Design and Implementation(Linus Torvalds 就是看了这本书受到启发写出了 Linux),从简单的 Minix 入手,hack 内核是件很有意思的事情,本人以前修改过 Minix 内核的进程调度,学到了内核方面的很多东西。另外推荐一本课外读物:Just for Fun,Linus Torvalds 写的一本自传。
Linux 给我们提供了方便的工具用来手动分配进程到不同的 CPU 上(CPU Affinity),这样我们可以按照服务器和应用的特性来安排特定的进程到特定的 CPU 上,比如 Oracle 要消耗大量 CPU 和 I/O 资源,如果我们能分配 Oracle 进程到某个或多个 CPU 上并由这些 CPU 专门处理 Oracle 的话会毫无疑问的提高应用程序的响应和性能。还有一些特殊情况是必须绑定应用程序到某个 CPU 上的,比如某个软件的授权是单 CPU 的,如果想运行在多 CPU 机器上的话就必须限制这个软件到某一个 CPU 上。
安装 schedutils
在 CentOS/Fedora 下安装 schedutils:
# yum install schedutils
在 Debian/Ubuntu 下安装 schedutils:
# apt-get install schedutils
如果正在使用 CentOS/Fedora/Debian/Ubuntu 的最新版本的话,schedutils/util-linux 这个软件包可能已经装上了。
计算 CPU Affinity 和计算 SMP IRQ Affinity 差不多:
0x00000001 (CPU0)
0x00000002 (CPU1)
0x00000003 (CPU0+CPU1)
0x00000004 (CPU2)
...
使用 schedutils
如果想设置进程号(PID)为 12212 的进程到 CPU0 上的话:
# taskset 0x00000001 -p 12212
GNU/Linux使用LVS在多核、多CPU下网卡中断分配调优
2013-02-18 16:28:33
最近在做LVS做load balance测试时发现在并发达到1w以后网卡中断只占用了一个CPU,最终导致此CPU的100%,性能再无法提升。
逐步尝试以下方法:
- 修改内核参数irqbalance。印象中此参数能把网卡中断平分到多个CPU上。但是查询最新文档发现此参数在最新的内核中已经不存在;
- 使用设备中断的smp_affinity:
- 首先先从/proc/interrupts里查到网卡的中断号,eth0或者bg0所在行的第一列;
- 修改/proc/irq/<中断编号>/ 下修改 smp_affinity 文件内容。这个文件是一个位掩码,01意味着只有第一个CPU能处理中断,0F意味着四个CPU都会参与处理中断。
- 但是经过测试发现此方法能把网卡中断绑定到指定的CPU上,但是不能在多个CPU间平均分配。
- 使用user space态下的irqbalance daemon,未得到反馈,估计无效;
- 使用Intel高端网卡82575,见文档详细说明:
- Assigning Interrupts to Processor Cores using an Intel(R) 82575/82576
or 82598/82599 Ethernet Controller September
Http://Download.Intel.Com/Design/Network/Applnots/319935.Pdf
- Improving Network Performance in Multi-Core Systems
Http://Www.Intel.Com/Network/Connectivity/Products/Whitepapers/318483.Pdf
设备中断绑定到特定CPU(SMP IRQ AFFINITY)
在前阵子看到HelloDB的一篇文章“MySQL单机多实例方案”中提到:
因为单机运行多个实例,必须对网络进行优化,我们通过多个的IP的方式,将多个MySQL实例绑定在不同的网卡上,从而提高整体的网络能力。还有一种更高级的做法是,将不同网卡的中断与CPU绑定,这样可以大幅度提升网卡的效率。
于是,对“将不同网卡的中断与CPU绑定,这样可以大幅度提升网卡的效率”比较感兴趣,所以找了点资料了解一下。先总结如下:
1. 不同的设备一般都有自己的IRQ号码(当然一个设备还有可能有多个IRQ号码)
通过命令:cat /proc/interrupts查看
如:cat /proc/interrupts | grep -e “CPU\|eth4”
2. 中断的smp affinity在cat /proc/irq/$Num/smp_affinity
可以echo “$bitmask” > /proc/irq/$num/smp_affinity来改变它的值。
注意smp_affinity这个值是一个十六进制的bitmask,它和cpu No.序列的“与”运算结果就是将affinity设置在那个(那些)CPU了。(也即smp_affinity中被设置为1的位为CPU No.)
比如:我有8个逻辑core,那么CPU#的序列为11111111 (从右到左依次为#0~#7的CPU)
如果cat /proc/irq/84/smp_affinity的值为:20(二进制为:00100000),则84这个IRQ的亲和性为#5号CPU。
每个IRQ的默认的smp affinity在这里:cat /proc/irq/default_smp_affinity
另外,cat /proc/irq/$Num/smp_affinity_list 得到的即是CPU的一个List。
3. 默认情况下,有一个irqbalance在对IRQ进行负载均衡,它是/etc/init.d/irqbalance
在某些特殊场景下,可以根据需要停止这个daemon进程。
4. 如果要想提高性能,将IRQ绑定到某个CPU,那么最好在系统启动时,将那个CPU隔离起来,不被scheduler通常的调度。
可以通过在Linux kernel中加入启动参数:isolcpus=cpu-list来将一些CPU隔离起来。
参考资料:
http://kernel.org/doc/Documentation/IRQ-affinity.txt
http://kernel.org/doc/Documentation/kernel-parameters.txt
http://www.vpsee.com/2010/07/load-balancing-with-irq-smp-affinity/
计算 SMP IRQ Affinity
如何绑定特定的硬件中断到特定的 CPU 上 ,分散和平衡各个中断到不同的 CPU 上以获取更大性能的处理能力。上篇限于篇幅的关系,没有来得及进一步说明 “echo 2 > /proc/irq/90/smp_affinity” 中的 ”2“ 是怎么来的,这其实是个二进制数字,代表 00000010,00000001 代表 CPU0 的话,00000010 就代表 CPU0, “echo 2 > /proc/irq/90/smp_affinity” 的意思就是说把 90 中断绑定到 00000010(CPU1)上。所以各个 CPU 用二进制和十六进制表示就是:
Binary Hex
[separ ator] CPU 0 00000001 1
CPU 1 00000010 2
CPU 2 00000100 4
CPU 3 00001000 8
如果我想把 IRQ 绑定到 CPU2 上就是 00000100=4:
# echo "4" > /p
Linux内核学习之旅--软中断(SIrq)与SMP IRQ Affinity
中断过程简单来说就是一种CPU 与硬件沟通的方式
中断分为两个过程,中间以中断控制器作为分隔。上半部分即中断上半部,下半部分为中断下半部。
上半部分大部分为说说的硬件中断,下半部分为软中断。
硬件中断通常由真实物理设备产生的脉冲信号作为信号源,也就是说这里的物理设备与中断控制器沟通方式是通过物理电信号来做的。
软件中断由中断控制器负责统一调度,通常硬件设备产生信号,这个信号带有中断号发送给中断控制器,中断控制器轮训收到的信号来调用对应的中断处理程序。
直观一点来看:
通过
shell> cat /proc/interrupts
可以查看到当前系统的软中断列表和对应的中断号
从左到右依次表示:
中断号,对应CPU中断次数,设备类型和设备名

[root@localhost ~]# cat /proc/interrupts
CPU0 CPU1
0: 14678 0 IO-APIC-edge timer
1: 2 0 IO-APIC-edge i8042
4: 2 0 IO-APIC-edge
7: 0 0 IO-APIC-edge parport0
8: 1 0 IO-APIC-edge rtc0
9: 0 0 IO-APIC-fasteoi acpi
12: 4 0 IO-APIC-edge i8042
14: 45394223 0 IO-APIC-edge ata_piix
15: 0 0 IO-APIC-edge ata_piix
16: 56 16232636 IO-APIC-fasteoi i915, p2p1
18: 5333843 11365439 IO-APIC-fasteoi uhci_hcd:usb4
20: 2277759 0 IO-APIC-fasteoi ata_piix
21: 3 0 IO-APIC-fasteoi ehci_hcd:usb1, uhci_hcd:usb2
22: 0 0 IO-APIC-fasteoi uhci_hcd:usb3
23: 3813 6412 IO-APIC-fasteoi uhci_hcd:usb5, Intel ICH7
NMI: 1037 925 Non-maskable interrupts
LOC: 319530452 247726622 Local timer interrupts
SPU: 0 0 Spurious interrupts
PMI: 1037 925 Performance monitoring interrupts
PND: 0 0 Performance pending work
RES: 275434 264341 Rescheduling interrupts
CAL: 4975165 5543634 Function call interrupts
TLB: 452039 409944 TLB shootdowns
TRM: 0 0 Thermal event interrupts
THR: 0 0 Threshold APIC interrupts
MCE: 0 0 Machine check exceptions
MCP: 14411 14411 Machine check polls
ERR: 0
MIS: 0
APIC表示高级可编程中断控制器(Advanced Programmable Interrupt Controlle)
APIC是SMP体系的核心,通过APIC可以将中断分发到不同的CPU 来处理
比如我这里的0号中断都是由CPU 来处理的,一些其他的中断可以绑定CPU或者可以把中断处理平摊到CPU 上,这个过程叫做 SMP IRQ Affinity
14号中断是属于硬盘设备中断,可以看到中断处理全部由单个CPU完成,这是因为为了使CPU 缓存的命中率提高等因素,使得CPU和硬盘中断绑定(IRQBalance)
如果的多网卡多CPU的情况下,也可以考虑将指定的网卡软中断绑定到对应的CPU 上,这样可以将负载有效的平衡,且能最大限度的利用CPU 缓存。
这样做的前提是先关闭IRQBalance
/etc/init.d/irqbalance stop
然后可以查看到
cat /proc/irq/14/smp_affinity
对应的软中断的多核CPU亲和性设置
我这里显示的是3,是什么意思呢
对应的CPU情况是这样的
CPU0 ---------- 00000001 1
CPU1 ---------- 00000010 2
CPU2 ---------- 00000100 4
.
.
.
CPUN ---------- XXXXXXX 2^N
3 就表示1+2,也就是两个CPU 都均衡,因为开启了IRQ Balance,所以这里中断处理都会交给同一个CPU来保证效率
这里的设置都需要硬件的支持,如果开启关闭IRQBalance自己设置中断处理的CPU亲和,有的设备在负载压力大的时候也是会转到其他CPU处理的,这里的亲和并不是强制性的CPU设置。
亲和性设置建议:DB可以设置一部分CPU处理硬盘IO,一部分CPU处理网络IO,多网卡服务器可以设置对应CPU对应网卡。当然具体情况看生产情况而定
roc/irq/90/smp_affinity
如果我想把 IRQ 同时平衡到 CPU0 和 CPU2 上就是 00000001+00000100=00000101=5
# echo "5" > /proc/irq/90/smp_affinity
需要注意的是,在手动绑定 IRQ 到 CPU 之前需要先停掉 irqbalance 这个服务,irqbalance 是个服务进程、是用来自动绑定和平衡 IRQ 的:
# /etc/init.d/irqbalance stop
设备中断绑定到特定CPU(SMP IRQ Affinity)
2013-04-18 16:08:41
在前阵子看到HelloDB的一篇文章“MySQL单机多实例方案”中提到:
因为单机运行多个实例,必须对网络进行优化,我们通过多个的IP的方式,将多个MySQL实例绑定在不同的网卡上,从而提高整体的网络能力。还有一种更高级的做法是,将不同网卡的中断与CPU绑定,这样可以大幅度提升网卡的效率。
于是,对“将不同网卡的中断与CPU绑定,这样可以大幅度提升网卡的效率”比较感兴趣,所以找了点资料了解一下。先总结如下:
1. 不同的设备一般都有自己的IRQ号码(当然一个设备还有可能有多个IRQ号码)
通过命令:cat /proc/interrupts查看
如:cat /proc/interrupts | grep -e “CPU\|eth4″
2. 中断的smp affinity在cat /proc/irq/$Num/smp_affinity
可以echo “$bitmask” > /proc/irq/$num/smp_affinity来改变它的值。
注意smp_affinity这个值是一个十六进制的bitmask,它和cpu No.序列的“与”运算结果就是将affinity设置在那个(那些)CPU了。(也即smp_affinity中被设置为1的位为CPU No.)
比如:我有8个逻辑core,那么CPU#的序列为11111111 (从右到左依次为#0~#7的CPU)
如果cat /proc/irq/84/smp_affinity的值为:20(二进制为:00100000),则84这个IRQ的亲和性为#5号CPU。
每个IRQ的默认的smp affinity在这里:cat /proc/irq/default_smp_affinity
另外,cat /proc/irq/$Num/smp_affinity_list 得到的即是CPU的一个List。
3. 默认情况下,有一个irqbalance在对IRQ进行负载均衡,它是/etc/init.d/irqbalance
在某些特殊场景下,可以根据需要停止这个daemon进程。
4. 如果要想提高性能,将IRQ绑定到某个CPU,那么最好在系统启动时,将那个CPU隔离起来,不被scheduler通常的调度。
可以通过在Linux kernel中加入启动参数:isolcpus=cpu-list来将一些CPU隔离起来。
参考资料:
http://kernel.org/doc/Documentation/IRQ-affinity.txt
http://kernel.org/doc/Documentation/kernel-parameters.txt
http://www.vpsee.com/2010/07/load-balancing-with-irq-smp-affinity/
SMP IRQ affinity
Linux 2.4内核之后引入了将特定中断绑定到指定的CPU的技术,称为SMP IRQ affinity.
原理
当一个硬件(如磁盘控制器或者以太网卡), 需要打断CPU的工作时, 它就触发一个中断. 该中断通知CPU发生了某些事情并且CPU应该放下当前的工作去处理这个事情. 为了防止多个设置发送相同的中断, Linux设计了一套中断请求系统, 使得计算机系统中的每个设备被分配了各自的中断号, 以确保它的中断请求的唯一性. 从2.4 内核开始, Linux改进了分配特定中断到指定的处理器(或处理器组)的功能. 这被称为SMP IRQ affinity, 它可以控制系统如何响应各种硬件事件. 允许你限制或者重新分配服务器的工作负载, 从而让服务器更有效的工作. 以网卡中断为例,在没有设置SMP IRQ affinity时, 所有网卡中断都关联到CPU0, 这导致了CPU0负载过高,而无法有效快速的处理网络数据包,导致了瓶颈。 通过SMP IRQ affinity, 把网卡多个中断分配到多个CPU上,可以分散CPU压力,提高数据处理速度。
使用前提
- 需要多CPU的系统
- 需要大于等于2.4的Linux 内核
相关设置文件
1. /proc/irq/IRQ#/smp_affinity
- /proc/irq/IRQ#/smp_affinity 和 /proc/irq/IRQ#/smp_affinity_list 指定了哪些CPU能够关联到一个给定的IRQ源. 这两个文件包含了这些指定cpu的cpu位掩码(smp_affinity)和cpu列表(smp_affinity_list). 不允许关闭所有CPU, 同时如果IRQ控制器不支持中断请求亲和(IRQ affinity),则这些设置的值将保持不变(既关联到所有CPU). 设置方法如下
|
1
|
echo
$bitmask >
/proc/irq/IRQ
|
- 示例(把44号中断绑定到前4个CPU(CPU0-3)上面)
|
1
|
echo
f >
/proc/irq/44/smp_affinity
|
2. /proc/irq/IRQ#/smp_affinity_list
- 设置该文件取得的效果与/proc/irq/IRQ#/smp_affinity是一致的,它们两者是联动关系(既设置其中之一,另一个文件也随着改变), 有些系统可能没有该文件, 设置方法如下
|
1
|
echo
$cpuindex1-$cpuindex2 >
/proc/irq/IRQ
|
- 示例(把44号中断绑定到前4个CPU(CPU0-3)上面)
|
1
|
echo
0-3 >
/proc/irq/44/smp_affinity_list
|
3. /proc/irq/default_smp_affinity
- /proc/irq/default_smp_affinity 指定了默认情况下未激活的IRQ的中断亲和掩码(affinity mask).一旦IRQ被激活,它将被设置为默认的设置(即default_smp_affinity中记录的设置). 该文件能被修改. 默认设置是0xffffffff.
bitmask计算方法
首先我们来看看smp_affinity文件的内容
|
1
2
|
root@
hostname
:
/home/igi
ffffff
|
这个bitmask表示了76号中断将被路由到哪个指定处理器. bit mask转换成二进制后,其中的每一位代表了一个CPU. smp_affinity文件中的数值以十六进制显示。为了操作该文件,在设置之前我们需要把CPU位掩码从二进制转换到十六进制。
上面例子中每一个”f”代表了4个CPU的集合,最靠右边的值是最低位的意思。 以4个CPU的系统为例:
- “f” 是十六进制的值, 二进制是”1111”. 二进制中的每个位代表了服务器上的每个CPU. 那么能用以下方法表示每个CPU
二进制 十六进制
CPU 0 0001 1
CPU 1 0010 2
CPU 2 0100 4
CPU 3 1000 8
- 结合这些位掩码(简单来说就是直接对十六进制值做加法), 我们就能一次定位多个CPU。 例如, 我想同时表示CPU0和CPU2, bitmask结果就是:
二进制 十六进制
CPU 0 0001 1
+ CPU 2 0100 4
-----------------------
bitmask 0101 5
- 如果我想一次性表示所有4个CPU,bitmask结果是:
二进制 十六进制
CPU 0 0001 1
CPU 1 0010 2
CPU 2 0100 4
+ CPU 3 1000 8
-----------------------
bitmask 1111 f
假如有一个4个CPU的系统, 我们能给一个IRQ分配15种不同的CPU组合(实际上有16种,但我们不能给任何中断分配中断亲和为”0”的值, 即使你这么做,系统也会忽略你的做法)
对比测试
| 类别 |
测试客户端 |
测试服务端 |
| 型号 |
BladeCenter HS22 |
BladeCenter HS22 |
| CPU |
Xeon E5640 |
Xeon E5640 |
| 网卡 |
Broadcom NetXtreme II BCM5709S Gigabit Ethernet |
Broadcom NetXtreme II BCM5709S Gigabit Ethernet |
| 内核 |
2.6.38-2-686-bigmem |
2.6.38-2-686-bigmem |
| 内存 |
24GB |
24GB |
| 系统 |
Debian 6.0.3 |
Debian 6.0.3 |
| 驱动 |
bnx2 |
bnx2 |
- 客户端: netperf
- 服务端: netserver
- 测试分类: 不开启IRQ affinity和RPS/RFS, 单独开启IRQ affinity, 单独开启RPS/RFS,同时开启IRQ affinity和RPS/RFS, 不同分类设置值如下
- 不开启IRQ affinity和RPS/RFS
/proc/irq/74/smp_affinity 00ffff
/proc/irq/75/smp_affinity 00ffff
/proc/irq/76/smp_affinity 00ffff
/proc/irq/77/smp_affinity 00ffff
/proc/irq/78/smp_affinity 00ffff
/proc/irq/79/smp_affinity 00ffff
/proc/irq/80/smp_affinity 00ffff
/proc/irq/81/smp_affinity 00ffff
/sys/class/net/eth0/queues/rx-0/rps_cpus 00000000
/sys/class/net/eth0/queues/rx-1/rps_cpus 00000000
/sys/class/net/eth0/queues/rx-2/rps_cpus 00000000
/sys/class/net/eth0/queues/rx-3/rps_cpus 00000000
/sys/class/net/eth0/queues/rx-4/rps_cpus 00000000
/sys/class/net/eth0/queues/rx-5/rps_cpus 00000000
/sys/class/net/eth0/queues/rx-6/rps_cpus 00000000
/sys/class/net/eth0/queues/rx-7/rps_cpus 00000000
/sys/class/net/eth0/queues/rx-0/rps_flow_cnt 0
/sys/class/net/eth0/queues/rx-1/rps_flow_cnt 0
/sys/class/net/eth0/queues/rx-2/rps_flow_cnt 0
/sys/class/net/eth0/queues/rx-3/rps_flow_cnt 0
/sys/class/net/eth0/queues/rx-4/rps_flow_cnt 0
/sys/class/net/eth0/queues/rx-5/rps_flow_cnt 0
/sys/class/net/eth0/queues/rx-6/rps_flow_cnt 0
/sys/class/net/eth0/queues/rx-7/rps_flow_cnt 0
/proc/sys/net/core/rps_sock_flow_entries 0
- 单独开启IRQ affinity
/proc/irq/74/smp_affinity 000001
/proc/irq/75/smp_affinity 000002
/proc/irq/76/smp_affinity 000004
/proc/irq/77/smp_affinity 000008
/proc/irq/78/smp_affinity 000010
/proc/irq/79/smp_affinity 000020
/proc/irq/80/smp_affinity 000040
/proc/irq/81/smp_affinity 000080
/sys/class/net/eth0/queues/rx-0/rps_cpus 00000000
/sys/class/net/eth0/queues/rx-1/rps_cpus 00000000
/sys/class/net/eth0/queues/rx-2/rps_cpus 00000000
/sys/class/net/eth0/queues/rx-3/rps_cpus 00000000
/sys/class/net/eth0/queues/rx-4/rps_cpus 00000000
/sys/class/net/eth0/queues/rx-5/rps_cpus 00000000
/sys/class/net/eth0/queues/rx-6/rps_cpus 00000000
/sys/class/net/eth0/queues/rx-7/rps_cpus 00000000
/sys/class/net/eth0/queues/rx-0/rps_flow_cnt 0
/sys/class/net/eth0/queues/rx-1/rps_flow_cnt 0
/sys/class/net/eth0/queues/rx-2/rps_flow_cnt 0
/sys/class/net/eth0/queues/rx-3/rps_flow_cnt 0
/sys/class/net/eth0/queues/rx-4/rps_flow_cnt 0
/sys/class/net/eth0/queues/rx-5/rps_flow_cnt 0
/sys/class/net/eth0/queues/rx-6/rps_flow_cnt 0
/sys/class/net/eth0/queues/rx-7/rps_flow_cnt 0
/proc/sys/net/core/rps_sock_flow_entries 0
- 单独开启RPS/RFS
/proc/irq/74/smp_affinity 00ffff
/proc/irq/75/smp_affinity 00ffff
/proc/irq/76/smp_affinity 00ffff
/proc/irq/77/smp_affinity 00ffff
/proc/irq/78/smp_affinity 00ffff
/proc/irq/79/smp_affinity 00ffff
/proc/irq/80/smp_affinity 00ffff
/proc/irq/81/smp_affinity 00ffff
/sys/class/net/eth0/queues/rx-0/rps_cpus 0000ffff
/sys/class/net/eth0/queues/rx-1/rps_cpus 0000ffff
/sys/class/net/eth0/queues/rx-2/rps_cpus 0000ffff
/sys/class/net/eth0/queues/rx-3/rps_cpus 0000ffff
/sys/class/net/eth0/queues/rx-4/rps_cpus 0000ffff
/sys/class/net/eth0/queues/rx-5/rps_cpus 0000ffff
/sys/class/net/eth0/queues/rx-6/rps_cpus 0000ffff
/sys/class/net/eth0/queues/rx-7/rps_cpus 0000ffff
/sys/class/net/eth0/queues/rx-0/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-1/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-2/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-3/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-4/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-5/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-6/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-7/rps_flow_cnt 4096
/proc/sys/net/core/rps_sock_flow_entries 32768
- 同时开启IRQ affinity和RPS/RFS
/proc/irq/74/smp_affinity 000001
/proc/irq/75/smp_affinity 000002
/proc/irq/76/smp_affinity 000004
/proc/irq/77/smp_affinity 000008
/proc/irq/78/smp_affinity 000010
/proc/irq/79/smp_affinity 000020
/proc/irq/80/smp_affinity 000040
/proc/irq/81/smp_affinity 000080
/sys/class/net/eth0/queues/rx-0/rps_cpus 0000ffff
/sys/class/net/eth0/queues/rx-1/rps_cpus 0000ffff
/sys/class/net/eth0/queues/rx-2/rps_cpus 0000ffff
/sys/class/net/eth0/queues/rx-3/rps_cpus 0000ffff
/sys/class/net/eth0/queues/rx-4/rps_cpus 0000ffff
/sys/class/net/eth0/queues/rx-5/rps_cpus 0000ffff
/sys/class/net/eth0/queues/rx-6/rps_cpus 0000ffff
/sys/class/net/eth0/queues/rx-7/rps_cpus 0000ffff
/sys/class/net/eth0/queues/rx-0/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-1/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-2/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-3/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-4/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-5/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-6/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-7/rps_flow_cnt 4096
/proc/sys/net/core/rps_sock_flow_entries 32768
测试方法: 每种测试类型执行3次,中间睡眠10秒, 每种测试类型分别执行100、500、1500个实例, 每实例测试时间长度为60秒
- TCP_RR 1 byte: 测试TCP 小数据包 request/response的性能
|
1
|
netperf -t TCP_RR -H $serverip -c -C -l 60
|
- UDP_RR 1 byte: 测试UDP 小数据包 request/response的性能
|
1
|
netperf -t UDP_RR -H $serverip -c -C -l 60
|
- TCP_RR 256 byte: 测试TCP 大数据包 request/response的性能
|
1
|
netperf -t TCP_RR -H $serverip -c -C -l 60 -- -r256,256
|
- UDP_RR 256 byte: 测试UDP 大数据包 request/response的性能
|
1
|
netperf -t UDP_RR -H $serverip -c -C -l 60 -- -r256,256
|
测试结果
CPU核负载的变化
以小数据包1500进程测试的CPU(除了明确指明类型,否则这里的负载都是TCP_RR测试的负载)负载数据为示例
- 不开启IRQ affinity和RPS/RFS: 软中断集中在第一个CPU上,导致了性能瓶颈
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
Average: all 2.15 0.00 11.35 0.00 0.00 5.66 0.00 0.00 80.84
Average: 0 0.12 0.00 0.65 0.00 0.00 90.86 0.00 0.00 8.38
Average: 1 8.36 0.00 37.46 0.00 0.00 0.00 0.00 0.00 54.19
Average: 2 7.92 0.00 32.94 0.00 0.00 0.00 0.00 0.00 59.13
Average: 3 5.68 0.00 23.96 0.00 0.00 0.00 0.00 0.00 70.36
Average: 4 0.78 0.00 9.77 0.07 0.00 0.00 0.00 0.00 89.39
Average: 5 0.67 0.00 8.87 0.00 0.00 0.00 0.00 0.00 90.47
Average: 6 0.77 0.00 6.91 0.00 0.00 0.00 0.00 0.00 92.32
Average: 7 0.50 0.00 5.55 0.02 0.00 0.00 0.00 0.00 93.93
Average: 8 7.29 0.00 37.16 0.00 0.00 0.00 0.00 0.00 55.55
Average: 9 0.35 0.00 2.28 0.00 0.00 0.00 0.00 0.00 97.37
Average: 10 0.27 0.00 2.01 0.00 0.00 0.00 0.00 0.00 97.72
Average: 11 0.25 0.00 1.87 0.00 0.00 0.00 0.00 0.00 97.88
Average: 12 0.23 0.00 2.78 0.00 0.00 0.00 0.00 0.00 96.99
Average: 13 0.27 0.00 2.70 0.00 0.00 0.00 0.00 0.00 97.04
Average: 14 0.55 0.00 3.03 0.02 0.00 0.00 0.00 0.00 96.40
Average: 15 0.10 0.00 2.16 0.00 0.00 0.00 0.00 0.00 97.74
- 单独开启RPS/RFS: 软中断主要集中在CPU0上,但有少许分布在其他CPU上
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
Average: all 4.65 0.00 34.71 0.01 0.00 7.37 0.00 0.00 53.26
Average: 0 0.02 0.00 0.37 0.00 0.00 99.40 0.00 0.00 0.22
Average: 1 5.60 0.00 38.33 0.02 0.00 2.02 0.00 0.00 54.04
Average: 2 5.57 0.00 37.33 0.03 0.00 1.01 0.00 0.00 56.05
Average: 3 5.11 0.00 36.28 0.00 0.00 0.73 0.00 0.00 57.88
Average: 4 4.78 0.00 37.16 0.00 0.00 2.05 0.00 0.00 56.01
Average: 5 4.45 0.00 37.46 0.00 0.00 0.97 0.00 0.00 57.12
Average: 6 4.34 0.00 36.25 0.00 0.00 0.97 0.00 0.00 58.45
Average: 7 4.28 0.00 35.87 0.00 0.00 0.97 0.00 0.00 58.88
Average: 8 5.47 0.00 37.11 0.02 0.00 1.27 0.00 0.00 56.13
Average: 9 5.58 0.00 37.59 0.03 0.00 2.13 0.00 0.00 54.66
Average: 10 5.98 0.00 37.04 0.00 0.00 1.22 0.00 0.00 55.76
Average: 11 4.99 0.00 34.58 0.00 0.00 0.99 0.00 0.00 59.44
Average: 12 4.46 0.00 37.47 0.00 0.00 0.99 0.00 0.00 57.09
Average: 13 4.83 0.00 36.97 0.00 0.00 1.37 0.00 0.00 56.83
Average: 14 4.60 0.00 38.06 0.00 0.00 1.53 0.00 0.00 55.81
Average: 15 4.36 0.00 37.26 0.00 0.00 1.45 0.00 0.00 56.92
- 单独开启IRQ affinity, TCP_RR测试: 软中断负载比较均匀的分散到前面8个CPU之上(与bitmask设置一致)
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
Average: all 6.13 0.00 55.66 0.00 0.00 32.04 0.00 0.00 6.17
Average: 0 6.31 0.00 54.49 0.03 0.00 4.19 0.00 0.00 34.98
Average: 1 2.00 0.00 16.65 0.00 0.00 81.35 0.00 0.00 0.00
Average: 2 3.31 0.00 29.36 0.00 0.00 64.58 0.00 0.00 2.76
Average: 3 2.91 0.00 23.11 0.00 0.00 71.40 0.00 0.00 2.58
Average: 4 2.48 0.00 20.82 0.00 0.00 75.30 0.00 0.00 1.40
Average: 5 2.49 0.00 21.90 0.00 0.00 73.30 0.00 0.00 2.31
Average: 6 3.00 0.00 28.87 0.00 0.00 65.96 0.00 0.00 2.17
Average: 7 2.58 0.00 22.95 0.00 0.00 72.46 0.00 0.00 2.01
Average: 8 6.61 0.00 56.48 0.00 0.00 0.00 0.00 0.00 36.90
Average: 9 9.83 0.00 89.28 0.00 0.00 0.05 0.00 0.00 0.83
Average: 10 9.73 0.00 87.18 0.00 0.00 0.00 0.00 0.00 3.08
Average: 11 9.73 0.00 88.08 0.00 0.00 0.05 0.00 0.00 2.14
Average: 12 9.11 0.00 88.71 0.00 0.00 0.05 0.00 0.00 2.12
Average: 13 9.43 0.00 89.53 0.00 0.00 0.03 0.00 0.00 1.00
Average: 14 9.38 0.00 87.58 0.00 0.00 0.03 0.00 0.00 3.00
Average: 15 9.53 0.00 88.97 0.00 0.00 0.07 0.00 0.00 1.43
- 单独开启IRQ affinity, UDP_RR测试: 软中断负载不能均匀的分散到前面8个CPU之上,主要分布在CPU2上,导致了瓶颈,性能下降(下降原因请见本文测试的局限性部分)
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
Average: all 1.05 0.00 8.21 0.01 0.00 5.83 0.00 0.00 84.90
Average: 0 3.10 0.00 23.25 0.00 0.00 0.33 0.00 0.00 73.31
Average: 1 2.73 0.00 21.15 0.00 0.00 0.37 0.00 0.00 75.75
Average: 2 0.72 0.00 4.93 0.00 0.00 92.35 0.00 0.00 2.00
Average: 3 1.27 0.00 9.81 0.00 0.00 0.10 0.00 0.00 88.82
Average: 4 0.15 0.00 1.87 0.10 0.00 0.07 0.00 0.00 97.82
Average: 5 0.07 0.00 1.04 0.00 0.00 0.07 0.00 0.00 98.82
Average: 6 0.02 0.00 0.53 0.00 0.00 0.03 0.00 0.00 99.42
Average: 7 0.00 0.00 0.23 0.00 0.00 0.00 0.00 0.00 99.77
Average: 8 0.23 0.00 1.96 0.00 0.00 0.00 0.00 0.00 97.81
Average: 9 0.08 0.00 0.60 0.00 0.00 0.00 0.00 0.00 99.32
Average: 10 8.38 0.00 65.07 0.00 0.00 0.00 0.00 0.00 26.56
Average: 11 0.00 0.00 0.36 0.00 0.00 0.00 0.00 0.00 99.64
Average: 12 0.03 0.00 0.23 0.00 0.00 0.00 0.00 0.00 99.73
Average: 13 0.00 0.00 0.19 0.00 0.00 0.00 0.00 0.00 99.81
Average: 14 0.00 0.00 0.12 0.00 0.00 0.00 0.00 0.00 99.88
Average: 15 0.02 0.00 0.10 0.00 0.00 0.00 0.00 0.00 99.88
- 同时开启IRQ affinity和RPS/RFS: 软中断负载比较均匀的分散到各个CPU之上
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
Average: all 6.27 0.00 53.65 0.00 0.00 32.33 0.00 0.00 7.74
Average: 0 7.05 0.00 59.70 0.00 0.00 26.18 0.00 0.00 7.07
Average: 1 5.44 0.00 43.33 0.00 0.00 44.54 0.00 0.00 6.69
Average: 2 5.49 0.00 43.06 0.00 0.00 43.38 0.00 0.00 8.07
Average: 3 5.48 0.00 44.90 0.00 0.00 42.94 0.00 0.00 6.67
Average: 4 4.74 0.00 43.27 0.00 0.00 45.14 0.00 0.00 6.85
Average: 5 4.83 0.00 41.90 0.00 0.00 46.74 0.00 0.00 6.53
Average: 6 5.04 0.00 44.73 0.00 0.00 43.68 0.00 0.00 6.56
Average: 7 4.85 0.00 44.68 0.00 0.00 45.22 0.00 0.00 5.25
Average: 8 7.60 0.00 61.50 0.02 0.00 22.79 0.00 0.00 8.08
Average: 9 7.40 0.00 61.31 0.00 0.00 22.92 0.00 0.00 8.37
Average: 10 7.74 0.00 60.62 0.00 0.00 22.64 0.00 0.00 9.00
Average: 11 8.22 0.00 61.02 0.00 0.00 22.13 0.00 0.00 8.63
Average: 12 6.53 0.00 62.42 0.00 0.00 22.09 0.00 0.00 8.97
Average: 13 6.68 0.00 62.75 0.00 0.00 22.13 0.00 0.00 8.43
Average: 14 6.62 0.00 62.41 0.00 0.00 22.69 0.00 0.00 8.28
Average: 15 6.64 0.00 60.66 0.00 0.00 22.38 0.00 0.00 10.32
结果分析
1. TCP_RR TPS小数据包性能
- 单独开启RPS/RFS分别提升60%,145%,200%(依次对应100进程,500进程,1500进程,下同)
- 单独开启IRQ affinity分别提升135%, 343%, 443%
- 同时开启RPS/RFS和IRQ affinity分别提升148%, 346%, 372%
2. TCP_RR TPS大数据包性能
- 单独开启RPS/RFS分别提升76%,77%,89%
- 单独开启IRQ affinity分别提升79%, 77%, 88%
- 同时开启RPS/RFS和IRQ affinity分别提升79%, 77%, 88%
3. UDP_RR TPS小数据包性能
- 单独开启RPS/RFS分别提升44%,103%,94%
- 单独开启IRQ affinity性能分别下降11%, 8%, 8% (这是此次测试的局限造成, 详细分析见: 测试的局限性)
- 同时开启RPS/RFS和IRQ affinity分别提升65%, 130%, 137%
4. UDP_RR TPS小数据包性能
- 单独开启RPS/RFS分别提升55%,53%,61%
- 单独开启IRQ affinity性能分别下降5%, 4%, 4%
- 同时开启RPS/RFS和IRQ affinity分别提升55%, 51%, 53%
- TCP 小数据包应用上,单独开启IRQ affinity能获得最大的性能提升,随着进程数的增加,IRQ affinity的优势越加明显.
- UDP 小数据包方面,由于此次测试的局限,无法真实体现实际应用中的单独开启IRQ affinity而获得的性能提升, 但用RPS/RFS配合IRQ affinity,也能获得大幅度的性能提升;
- TCP 大数据包应用上,单独开启IRQ affinity性能提升没有小数据包那么显著,但也有接近80%的提升, 基本与单独开启RPS/RFS的性能持平, 根据实验的数据计算所得,此时网卡流量约为88MB,还没达到千兆网卡的极限。
- UDP 大数据包应用上,也是同样受测试局限性的影响,无法真实体现实际应用中的单独开启IRQ affinity而获得的性能提升, 但用RPS/RFS配合IRQ affinity,也能获得大幅度的性能提升
测试的局限性
对于UDP测试在IRQ affinity上性能的下降, 查阅了内核源码(drivers/net/bnx2.c)及资料, bnx2 网卡的RSS hash不支持对UDP的端口进行计算,从而导致单独启用IRQ affinity的时候(这时候由硬件进行hash计算), UDP的数据只被hash了IP地址而导致数据包的转发出现集中在某个CPU的现象. 这是此次测试的局限所在,由于测试只是一台服务器端及一台客户端,所有UDP的IP地址都相同,无法体现UDP性能在单独启用IRQ affinity的性能提升. 但RPS/RFS的hash计算不受硬件影响,故而能体现性能提升. 对于实际应用中,服务器与多台客户端交互的情形,应该不受bnx2的RSS hash影响(以上只是针对bnx2网卡的特定问题)
网卡IRQ绑定CPU实验
随着cpu内核的增多的及中断处理机制的提升,linux社区在kernel 2.4 以后的版本支持把不同的硬件中断请求(IRQ)分配到特定的 “CPU ”上,这个绑定技术被称为 SMP IRQ Affinity
试验过程如下:
1.首先查看当前系统上的中断是如何分配的
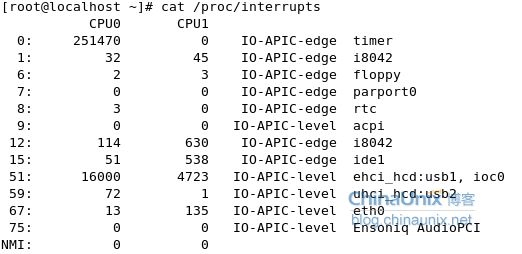
可以看出当前eth0在cpu0 和 cpu1上都有中断请求
2、查看一下当前eth0对应的IRQ 67中断的smp affinity值

不同CPU二进制与十六进制之间的对应关系表
Binary Hex
CPU 0 00000001 1
CPU 1 00000010 2
CPU 2 00000100 4
CPU 3 00001000 8
需要注意的是smp_affinity的值都是以十六进制的数值存放的,从上图可知道
Eth0的中断被分配给了cpu1上来执行,
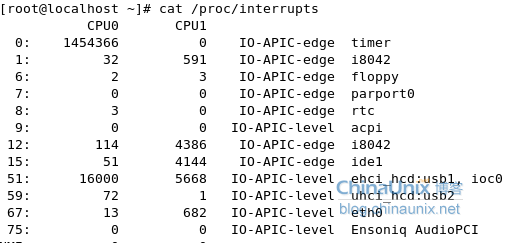
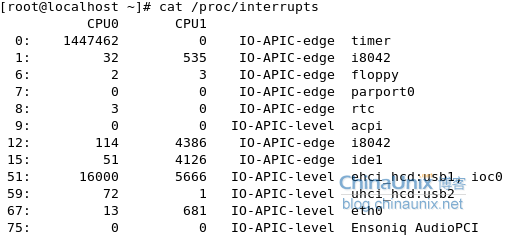
3、实验结果对比
在停止irqbalance 服务后
不断查看中断表可以看出cpu0上的中断数一直没有变化,而cpu1上的不断在变化

4、改变eth0的中断设置

重新查看中断表中eth0的中断值变化情况
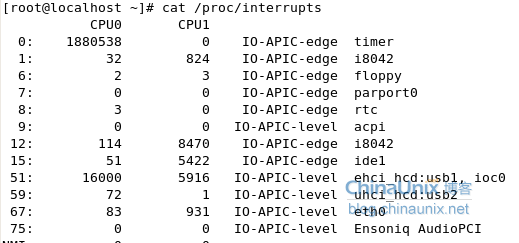


通过此实验得知:如果当前系统网络应用比较繁忙的情况下,可以单独绑定网卡的IRQ到指定的CPU上或者其他设备指定到单独的CPU上来提高系统整体的处理中断的能力,从而提高整体的吞吐负载性能