yolov3--25--Detectron目标检测可视化-P-R曲线绘制-Recall-TP-FP-FN等评价指标
Detectron目标检测平台
- 评估训练结果(生成mAP)
CUDA_VISIBLE_DEVICES=4 python tools/test_net.py --cfg experiments/2gpu_e2e_faster_rcnn_R-50-FPN-voc2007.yaml TEST.WEIGHTS out-faster-rcnn-1/train/voc_2007_train/generalized_rcnn/model_final.pkl NUM_GPUS 1 | tee visualization/2gpu_e2e_faster_rcnn_R-50-FPN-voc2007-test_net.log
- 可视化检测结果(测试多张图片)
CUDA_VISIBLE_DEVICES=4 python tools/visualize_results.py --dataset voc_2007_val --detections out-faster-rcnn-1/test/voc_2007_val/generalized_rcnn/detections.pkl --output-dir out-faster-rcnn-1/detectron-visualizations
P-R曲线绘制
效果如下图:
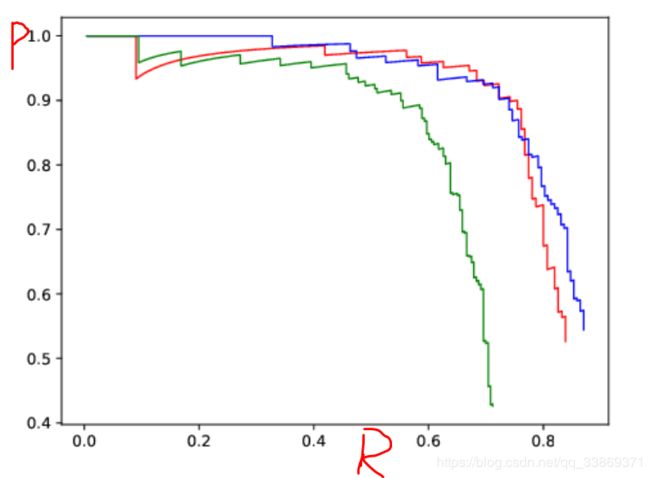
得到Recall-TP-FP-FN等评价指标



改动一:函数部分更改为:
# first load gt
if not os.path.isdir(cachedir):
os.mkdir(cachedir)
imageset = os.path.splitext(os.path.basename(imagesetfile))[0]
cachefile = os.path.join(cachedir, imageset + '_annots.pkl') #val_annotations.pkl
# read list of images
with open(imagesetfile, 'r') as f: #
lines = f.readlines()
imagenames = [x.strip() for x in lines]
#
if not os.path.isfile(cachefile):
# load annots
recs = {}
for i, imagename in enumerate(imagenames):
recs[imagename] = parse_rec(annopath.format(imagename))
if i % 100 == 0:
logger.info(
'Reading annotation for {:d}/{:d}'.format(
i + 1, len(imagenames)))
# save
logger.info('Saving cached annotations to {:s}'.format(cachefile))
save_object(recs, cachefile) #change
else:
recs = load_object(cachefile) #change
# extract gt objects for this class
class_recs = {}
npos = 0
for imagename in imagenames:
R = [obj for obj in recs[imagename] if obj['name'] == classname] #
bbox = np.array([x['bbox'] for x in R])
difficult = np.array([x['difficult'] for x in R]).astype(np.bool)
det = [False] * len(R)
npos = npos + sum(~difficult)
class_recs[imagename] = {'bbox': bbox,
'difficult': difficult,
'det': det}
# read dets
detfile = detpath.format(classname) #
with open(detfile, 'r') as f:
lines = f.readlines() #
splitlines = [x.strip().split(' ') for x in lines] #
image_ids = [x[0] for x in splitlines] #
confidence = np.array([float(x[1]) for x in splitlines]) #
BB = np.array([[float(z) for z in x[2:]] for x in splitlines]) #
# sort by confidence
sorted_ind = np.argsort(-confidence) #
BB = BB[sorted_ind, :] #
image_ids = [image_ids[x] for x in sorted_ind] #
# go down dets and mark TPs and FPs
nd = len(image_ids) #
tp = np.zeros(nd)
fp = np.zeros(nd)
for d in range(nd): #
R = class_recs[image_ids[d]] #image_ids[d]
bb = BB[d, :].astype(float) #
ovmax = -np.inf
BBGT = R['bbox'].astype(float)
#
if BBGT.size > 0:
# compute overlaps
# intersection
ixmin = np.maximum(BBGT[:, 0], bb[0])
iymin = np.maximum(BBGT[:, 1], bb[1])
ixmax = np.minimum(BBGT[:, 2], bb[2])
iymax = np.minimum(BBGT[:, 3], bb[3])
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
inters = iw * ih
# union
uni = ((bb[2] - bb[0] + 1.) * (bb[3] - bb[1] + 1.) +
(BBGT[:, 2] - BBGT[:, 0] + 1.) *
(BBGT[:, 3] - BBGT[:, 1] + 1.) - inters)
overlaps = inters / uni
ovmax = np.max(overlaps)
jmax = np.argmax(overlaps)
if ovmax > ovthresh:
if not R['difficult'][jmax]:
if not R['det'][jmax]:
tp[d] = 1.
R['det'][jmax] = 1 #
else:
fp[d] = 1.
else:
fp[d] = 1. #
num = len(np.where(confidence>0.7)[0]) #confidence
# compute precision recall
fp = np.cumsum(fp)
fpnum = int(fp[num-1]) #
tp = np.cumsum(tp)
tpnum = int(tp[num-1]) #
rec = tp / float(npos)
objectnum = int(npos)
# avoid divide by zero in case the first detection matches a difficult
# ground truth
prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps)
alarm = 1-prec[num-1]
ap = voc_ap(rec, prec, use_07_metric)
return rec, prec, ap, objectnum, tpnum, fpnum, alarm改动二:函数部分更改为:

if not os.path.isdir(output_dir):
os.mkdir(output_dir)
for _, cls in enumerate(json_dataset.classes):
if cls == '__background__':
continue
filename = _get_voc_results_file_template(
json_dataset, salt).format(cls)
rec, prec, ap ,objectnum, tpnum, fpnum, alarm = voc_eval(
filename, anno_path, image_set_path, cls, cachedir, ovthresh=0.5,
use_07_metric=use_07_metric)
aps += [ap]
logger.info('AP for {} = {:.4f}'.format(cls, ap))
logger.info(' {}TP+FN{:d}, TP{:d}, FN{:d}, recall{:.4f}, FP{:d}, precision{:.4f}, precision2{:.4f}'.format(cls, objectnum, tpnum, objectnum-tpnum, tpnum/float(objectnum), fpnum, 1-alarm, tpnum/(tpnum+fpnum)))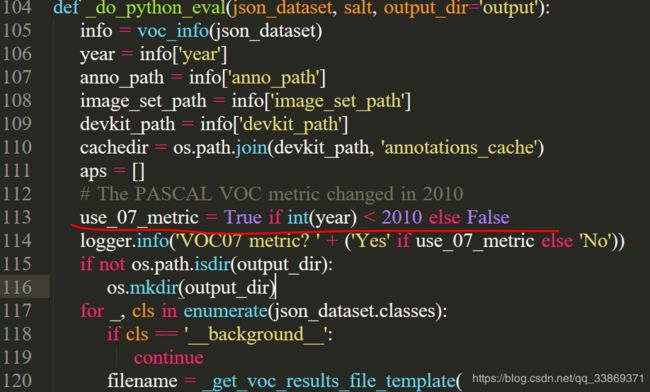
不使用07_metric计算AP指标,替换True与False的位置(重要,会影响精度)
.sh 训练文件:
CUDA_VISIBLE_DEVICES='6,7' python tools/train_net.py --cfg experiments/e2e_mask_rcnn_R-101-FPN_2x_gn-train1999-2gpu.yaml OUTPUT_DIR e2e_mask_rcnn_R-101-FPN_2x_gn-train1999-2gpu/ | tee visualization/e2e_mask_rcnn_R-101-FPN_2x_gn-train1999-2gpu-start6-18-416-416-1.log1、训练得到.pkl文件,


2、转换为此种格式:


3、和其它曲线画到一张图中:

出现错误:
python3错误之ImportError: No module named 'cPickle'

Python 文件操作出现错误(result, consumed) = self._buffer_decode(data, self.errors, final)
解决办法:
解决办法:“r”改为“rb”
R = [obj for obj in recs[imagename] if obj['name'] == classname] KeyError: '007765'
有效解决方案:训练前需要将cache中的pki文件以及VOCdevkit2007中annotations_cache的缓存删掉。我的路径是../data/VOCdevkit/annotations_cache/ ,删掉annots.pkl即可正常test,亲测有效
问题:https://blog.csdn.net/nuoyanli/article/details/94434890
注意Python插入程序时的对齐:空4格
pickle.load的时候出现EOFError: Ran out of input
参考:https://blog.csdn.net/Mr_health/article/details/89519469