python基于pandas数据分析实例——FIFA球员数据简单分析
pandas+matplotlib=简单数据分析
- 1、简介
- 2、需要用到的库
- 3、代码正文
1、简介
最近在学习数据分析,这也是python比较热门的一个方向,结合爬虫能分析许多东西,数据是在kaggle上找到的,上面很多实用性很强的数据,每个数据也有国外大佬做的分析实例,可以借鉴
kaggle
本文的分析有两部分:一、运动员的年龄分布。二、运动员能力与薪资的分布关系
!!!本文所有代码都是在python交互模式jupyter下完成的,只是不会用CSDN写入=.=!!!
2、需要用到的库
import pandas as pd
import matplotlib.pyplot as plt
#为了让图片显示在交互模式界面
%matplotlib inline
这个例子用到的库很简单,但这两个库也是用处很大的库
3、代码正文
#读取csv文件
df = pd.read_csv('data.csv')
df.head()

读取文件后用head()方法可以查看csv文件的前5行,包括索引、标头等信息
#判断数据中是否有缺失值
df.isnull().any()
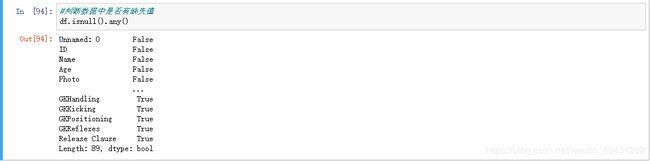
这种很大的数据集很容易有缺失值,所以在进行数据判断之前,一定要判断是否有缺失值,会对分析结果造成影响,如图出现了True证明数据是有缺失的
#将缺失值填充
new_df = df.fillna(0)
#再次判断是否有缺失值,以及每一列值的类型
new_df.info()

判断有缺失值之后有两种解决方案,删去缺失值或者用另一个数值补充,这里选择对结果影响较小的填充数据,填充之后再用info()判断是否填充成功,并且可以看到每一列值的类型
#区别年龄等级
def Age_Level(t):
if t<20:
return '20-'
elif t>=20 and t<25:
return '20-25'
elif t>=25 and t<30:
return '25-30'
elif t>=30 and t<35:
return '30-35'
elif t>=35:
return '35+'
else:
return 'ERROR'
#将年龄等级并入csv文件
new_df['Age_Level'] = new_df['Age'].map(Age_Level)
new_df.head()

第一个例子就是运动员的年龄分布,先将划分后的等级组成一列并入csv文件中,这里也可以再次保存一个新的csv文件方便调用
#查看每个年龄段的人数
new_df['Age_Level'].value_counts()

用value_counts()方法可以知道在每个年龄段的人数,然后绘制饼图,显示每个部分所占百分比
#绘制饼图
explodes = (0.05,0,0,0,0)
new_df['Age_Level'].value_counts().plot.pie(title = 'Age of Player',explode = explodes,fontsize = 12,figsize = (12,12),autopct = '%.1f%%')
plt.savefig('E:/jupyter/result/Age_of_Player.jpg')

可见运动员在20-30之间是状态最好的年龄段
第二个例子是利用散点图了解运动员能力和薪资的关系
#根据索引获取能力和薪资两列生成新的df
the_df = new_df.loc[:,['Overall','Wage']]
the_df
先通过索引将需要的两列值调出来再生成一个新的dataframe
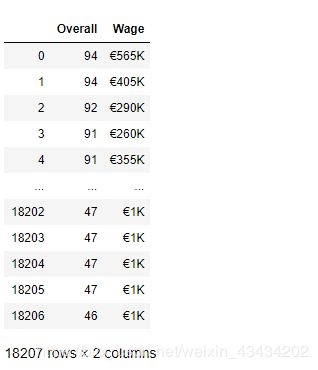
再调用出来之后会发现一个问题,再Value里有欧元的符号还有K,因为要看两者的分布关系,所以两者必须都要为数字类型,所以我们用replace()方法将两个符号去掉
#将Wage里的字符去掉
the_df['Wage'] = the_df['Wage'].str.replace('€','')
the_df['Wage'] = the_df['Wage'].str.replace('K','')
the_df

#Wage为object型需转化为int型
the_df.info()

可是再去掉符号之后,Value里的值还是为object类型,还没有达到我们需要的,接下来我们要用astype强制转化一下类型
#转化
the_df = the_df.astype(int)
应该还记得再前面我们再处理缺失值的时候填充了零,但是在只在这两列数据之间是将零删去更好的,所以删去含有零的每一行
#判读是否有零
the_df['Wage'].value_counts()
#删除之前填充的零
the_df = the_df[~the_df['Wage'].isin([0])]
#查看删除零后的数据
the_df.info()

这样散点图的数据也清洗完成,下面就进行绘制散点图,要先将两列值转换为列表,作为散点图的数据
#转化为列表,作为数据
x = the_df['Overall'].values.tolist()
y = the_df['Wage'].values.tolist()
#绘制饼图
plt.figure(figsize=(20, 8), dpi=80)
plt.title('The relationship between ability and salary',fontsize = 18)
plt.scatter(x, y)
plt.ylabel('Wage(K)',fontsize = 15)
plt.xlabel('Overall',fontsize = 15)
plt.show()
plt.savefig('E:/jupyter/result/ability_and_salary.jpg')

什么都不知道,但那两个孤立的点一定是梅西和C罗
python菜鸟=。=请多见谅~