学习STL
学习STL
- STL简介
- 六大组件的关系结构
- 1、容器(container)
- 2、算法(Algorithm)
- 3、迭代器(Adapter)
- 4、仿函数
- 5、适配器(Adapter)
- 6、空间配置器(Allocator)
- 泛型技术
学c++怎么能不学STL呢?《Primer C++》的第二部分介绍了C++标准库,个人感觉太碎片化了,脑海中没有形成一个整体的概念。
这篇博文转自: https://www.cnblogs.com/tgycoder/p/5379096.html。
博文中介绍了STL的六大组件。对STL有了一个整体的印象后,之后在学习和运用的时候就会感到心中有数。
STL简介
STL的原名是“Standard Template Library”,翻译过来就是标准模板库。STL是C++标准库的一个重要组成部分,主要由六大组件构成。这六大组件是:容器(Container)、算法(algorithm)、迭代器(iterator)、仿函数(functor)、适配器(adapter)、配置器(allocator)。
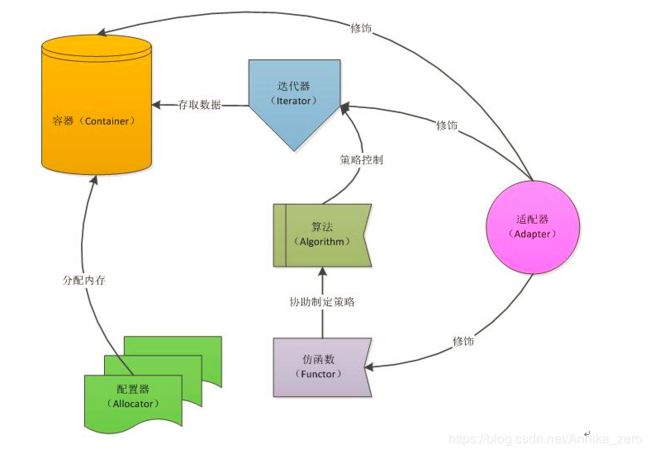
六大组件的关系结构
Container 通过Allocator获得数据存储空间;Algorithm 通过Iterator存取Container中的内容;Functor可以协助Algoritm完成不同策略;Adapter可以修饰Container、Algorithm、Iterator。
1、容器(container)
容器可以分为三类即序列容器、关联容器和容器适配器。各类具体包含如下所示:
- 序列容器:vector、list、deque
- 关联容器:set、map、multiset、multimap
- 适配器容器:stack、queue、priority_queue

2、算法(Algorithm)
算法部分主要在头文件algorithm,numeric,functional中。
- algoritm是所有STL头文件中最大的一个,它是由一大堆模版函数组成的,可以认为每个函数在很大程度上都是独立的,其中常用到的功能范 围涉及到比较、交换、查找、遍历操作、复制、修改、移除、反转、排序、合并等等。
- numeric体积很小,只包括几个在序列上面进行简单数学运算的模板函数,包括加法和乘法在序列上的一些操作。
- functional中则定义了一些模板类,用以声明函数对象。
3、迭代器(Adapter)
迭代器是用类模板(class template)实现的.重载了* ,-> ,++ ,-- 等运算符。
迭代器分5种:输入迭代器、输出迭代器、 前向迭代器、双向迭代器、 随机访问迭代器。
-
输入迭代器:向前读(只允许读;
-
输出迭代器:向前写(只允许写;
-
前向迭代器:向前读写;
-
双向迭代器:向前后读写;
-
随机迭代器:随机读写;
4、仿函数
仿函数用类模板实现,重载了符号"()"。仿函数,又或叫做函数对象,是STL六大组件之一;仿函数虽然小,但却极大的拓展了算法的功能,几乎所有的算法都有仿函数版本。
例如,查找算法find_if就是对find算法的扩展,标准的查找是两个元素相等就找到了,但是什么是相等在不同情况下却需要不同的定义,如地址相等,地址和邮编都相等,虽然这些相等的定义在变,但算法本身却不需要改变,这都多亏了仿函数。仿函数(functor)又称之为函数对象(function object),其实就是重载了()操作符的struct,没有什么特别的地方。
如以下代码定义了一个二元判断式functor:
struct IntLess
{
bool operator()(int left, int right) const
{
return (left < right);
}
};
仿函数的优势:
1)仿函数比一般函数灵活。
2)仿函数有类型识别。可以用作模板参数。
3)执行速度上仿函数比函数和指针要更快。
在STL里仿函数最常用的就是作为函数的参数,或者模板的参数。
在STL里有自己预定义的仿函数,比如所有的运算符=,-,*,、比如’<'号的仿函数是less。
// TEMPLATE STRUCT less
template
struct less
: public binary_function<_Ty, _Ty, bool>
{ // functor for operator<
bool operator()(const _Ty& _Left, const _Ty& _Right) const
{ // apply operator< to operands
return (_Left < _Right);
}
};
less继承binary_function<_Ty,_Ty,bool>
template
struct binary_function
{ // base class for binary functions
typedef _Arg1 first_argument_type;
typedef _Arg2 second_argument_type;
typedef _Result result_type;
};
从定义中可以知道binary_function知识做了一些类型的声明,这样做就是为了方便安全,提高可复用性。
按照这个规则,我们也可以自定义仿函数:
template
class func_equal :public binary_function
{
inline bool operator()(type1 t1,type2 t2) const//这里的const不能少
{
return t1 == t2;//当然这里要overload==
}
}
之所以const关键字修饰函数,是因为const对象只能访问const修饰的函数。如果一个const对象想使用重载的()函数,编译过程就会报错。
小结一下:仿函数就是重载()的class,并且重载函数要有const修饰。自定义仿函数必须要继承binary_function(二元函数)或者unary_function(一元函数)。其中unary_function的定义如下:
struct unary_function {
typedef _A argument_type;
typedef _R result_type;
};
5、适配器(Adapter)
适配器是用来修改其他组件接口的STL组件,是带有一个参数的类模板(这个参数是操作的值的数据类型)。STL定义了3种形式的适配器:容器适配器,迭代器适配器,函数适配器。
1)容器适配器:栈(stack)、队列(queue)、优先(priority_queue)。使用容器适配器,stack就可以被实现为基本容器类型(vector,dequeue,list)的适配。可以把stack看作是某种特殊的vctor,deque或者list容器,只是其操作仍然受到stack本身属性的限制。queue和priority_queue与之类似。容器适配器的接口更为简单,只是受限比一般容器要多。
2)迭代器适配器:修改为某些基本容器定义的迭代器的接口的一种STL组件。反向迭代器和插入迭代器都属于迭代器适配器,迭代器适配器扩展了迭代器的功能。
3)函数适配器:通过转换或者修改其他函数对象使其功能得到扩展。这一类适配器有否定器(相当于"非"操作)、绑定器、函数指针适配器。函数对象适配器的作用就是使函数转化为函数对象,或是将多参数的函数对象转化为少参数的函数对象。
例如:
在STL程序里,有的算法需要一个一元函数作参数,就可以用一个适配器把一个二元函数和一个数值,绑在一起作为一个一元函数传给算法。
find_if(coll.begin(), coll.end(), bind2nd(greater (), 42));
这句话就是找coll中第一个大于42的元素。
greater (),其实就是">"号,是一个2元函数
bind2nd的两个参数,要求一个是2元函数,一个是数值,结果是一个1元函数。
bind2nd就是个函数适配器。
6、空间配置器(Allocator)
STL内存配置器为容器分配并管理内存。统一的内存管理使得STL库的可用性、可移植行、以及效率都有了很大的提升。
SGI-STL的空间配置器有2种,一种仅仅对c语言的malloc和free进行了简单的封装,而另一个设计到小块内存的管理等,运用了内存池技术等。在SGI-STL中默认的空间配置器是第二级的配置器。
SGI使用时std::alloc作为默认的配置器。
alloc把内存配置和对象构造的操作分开,分别由alloc::allocate()和::construct()负责,同样内存释放和对象析够操作也被分开分别由alloc::deallocate()和::destroy()负责。这样可以保证高效,因为对于内存分配释放和构造析够可以根据具体类型(type traits)进行优化。比如一些类型可以直接使用高效的memset来初始化或者忽略一些析构函数。对于内存分配alloc也提供了2级分配器来应对不同情况的内存分配。
第一级配置器直接使用malloc()和free()来分配和释放内存。第二级视情况采用不同的策略:当需求内存超过128bytes的时候,视为足够大,便调用第一级配置器;当需求内存小于等于128bytes的时候便采用比较复杂的memeory pool的方式管理内存。
无论allocal被定义为第一级配置器还是第二级,SGI还为它包装一个接口,使得配置的接口能够符合标准即把配置单位从bytes转到了元素的大小:
template
class simple_alloc
{
public:
static T* allocate(size_t n)
{
return 0 == n ? 0 : (T*)Alloc::allocate(n * sizeof(T));
}
static T* allocate(void)
{
return (T*) Alloc::allocate(sizeof(T));
}
static void deallocate(T* p, size_t n)
{
if (0 != n) Alloc::deallocate(p, n * sizeof(T));
}
static void deallocate(T* p)
{
Alloc::deallocate(p, sizeof(T));
}
}
内存的基本处理工具,均具有commit或rollback能力。
template
ForwardIterator
uninitialized_copy(InputIterator first, InputIterator last, ForwardIterator result);
template
void uninitialized_fill(ForwardIterator first, ForwardIterator last, const T& x);
template
ForwardIterator
uninitialized_fill_n(ForwardIterator first, ForwardIterator last, const T& x)
泛型技术
泛型技术的实现方法有:模板、多态等。模板是编译时决定的,多态是运行时决定的,RTTI也是运行时确定的。
多态是依靠虚表在运行时查表实现的。比如一个类拥有虚方法,那么这个类的实例的内存起始地址就是虚表地址,可以把内存起始地址强制转换成int*,取得虚表,然后(int*)(int)取得虚表里的第一个函数的内存地址,然后强制转换成函数类型,即可调用来验证虚表机制。
泛型编程(Generic Programming,以下直接以GP称呼)是一种全新的程序设计思想,和OO,OB,PO这些为人所熟知的程序设计想法不同的是GP抽象度更高,基于GP设计的组件之间耦合度低,没有继承关系,所以其组件间的互交性和扩展性都非常高。我们都知道,任何算法都是作用在一种特定的数据结构上的,最简单的例子就是快速排序算法最根本的实现条件就是所排序的对象是存贮在数组里面,因为快速排序就是因为要用到数组的随机存储特性,即可以在单位时间内交换远距离的对象,而不只是相临的两个对象,而如果用链表去存储对象,由于在链表中取得对象的时间是线性的即O[n],这样将使快速排序失去其快速的特点。也就是说,我们在设计一种算法的时候,我们总是先要考虑其应用的数据结构,比如数组查找,联表查找,树查找,图查找其核心都是查找,但因为作用的数据结构不同将有多种不同的表现形式。数据结构和算法之间这样密切的关系一直是我们以前的认识。泛型设计的根本思想就是想把算法和其作用的数据结构分离,也就是说,我们设计算法的时候并不去考虑我们设计的算法将作用于何种数据结构之上。泛型设计的理想状态是一个查找算法将可以作用于数组,联表,树,图等各种数据结构之上,变成一个通用的,泛型的算法。