单向散列函数SHA-1算法分析与实现
1、简介:
SHA,全称安全哈希算法(Secure Hash Algorithm)主要适用于数字签名标准(Digital Signature Standard,DSS)里面定义的数字签名算法(Digital Signature Algorithm,DSA)。也就是说通常是用来对于信息的完整性进行验证的。而由于SHA的不可逆性,或者说是SHA中函数的不可逆性,该算法只能用于加密,不能用于解密。而加密的过程是将信息输入,经过Hash函数一系列计算后输出一串16进制字符串。不像双钥密钥/单钥密钥加密解密算法那样生成的是一堆“乱码”(其实只是输出方式不同而已)。
而SHA根据版本不同,可分为SHA-1、SHA-256、SHA-384、SHA-512等。其中SHA-256、SHA-384、SHA-512统称为SHA-2。SHA-1和SHA-256的可处理的消息上限为2^64bit(2^61Byte=2^21TB,大约200万TB,试想哪个消息长度能达到百万TB级别?至少目前没有,所以2^64bit上限完全可以满足常规需求),而SHA-384和SHA-512可处理的消息上限为2^128bit。SHA-1产生的散列值长度为160bit(20Byte),上述SHA-2的散列值长度分别为:256、384、512bit。
比如“Hello World!”的不同散列函数的加密后的散列值为(关于这一点可在在线加密解密进行验证,任意修改内容都会改变散列值,这也就是文件/信息完整性的验证):
//SHA-1:
2ef7bde608ce5404e97d5f042f95f89f1c232871
//SHA-256:
7f83b1657ff1fc53b92dc18148a1d65dfc2d4b1fa3d677284addd200126d9069
//SHA-384:
bfd76c0ebbd006fee583410547c1887b0292be76d582d96c242d2a792723e3fd6fd061f9d5cfd13b8f961358e6adba4a
//SHA-512:
861844d6704e8573fec34d967e20bcfef3d424cf48be04e6dc08f2bd58c729743371015ead891cc3cf1c9d34b49264b510751b1ff9e537937bc46b5d6ff4ecc8SHA-1的强抗碰撞性已经被攻破(强抗碰撞性:指的是要找到散列值相同的两条不同的消息是非常困难的这一特性,对应的有个弱抗碰撞性:指的是要找到和一条已有消息的散列值相同的另一条消息是非常困难的)。如今SHA-1已经面临被逐渐弃用的境地。但是取而代之的SHA-2其依旧是十分安全的。而SHA-1和SHA-2的基本算法结构是相通的。所以我们就SHA-1来分析学习并简单实现。
2、SHA-1的基本流程解析:
(1)、分组与填充:
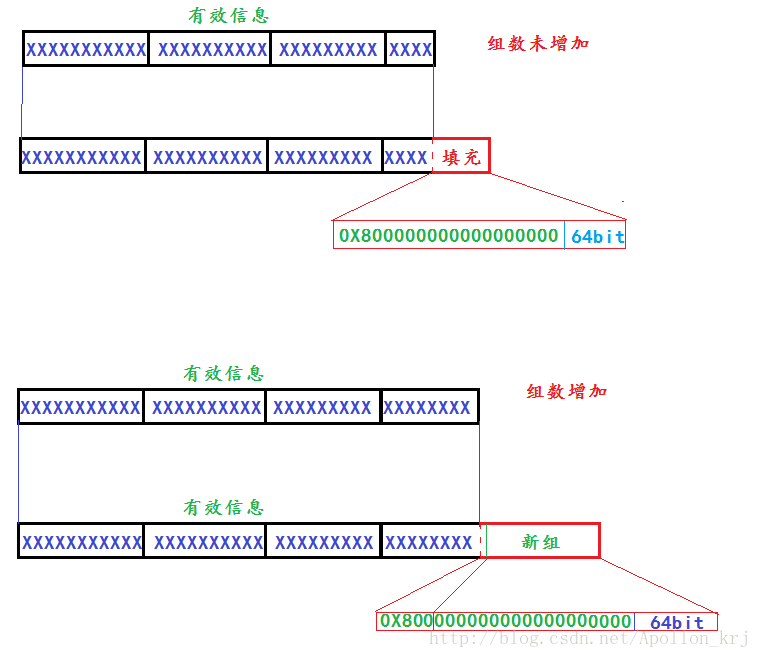
首先SHA-1可以进行分组加密,每一组的信息长度为512bit即64字节。而有效信息不足512的整数倍,就需要进行填充/补位操作,使进行SHA-1运算的数据总长度为512bit的整数倍。如何填充?首先消息长度为n * 8bit,紧接着在第n*8+1的bit位添加一个1,然后填充0,填充的0的个数根据长度来定。即:
若:(有效消息长度bit数)/512 = k
则:(有效消息长度bit数 + 添加的1和0长度bit数)/512bit == k或k+1
(有效消息长度bit数 + 添加的1和0长度bit数) %512bit == 64bit
64bit是用来存放有效消息长度(bit数)的。
eg:消息长度为69字节。可分为两组:64+5,由于最后一组不足512bit(64Byte)。所以先再第六个字节添加一个1,接着补0,剩余64bit填充信息长度69 * 8 = 552bit = 0X228bit,即后64bit的十六进制形式为: 00 00 00 00 00 00 02 28 。整个两组的信息(512 * 3 = 1536bit)为:
第一组:
XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX(16B)
XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX(16B)
XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX(16B)
XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX(16B)
第二组:
XX XX XX XX XX 80 00 00 00 00 00 00 00 00 00 00(16B)
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00(16B)
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00(16B)
00 00 00 00 00 00 00 00 00 00 00 00 00 00 02 28(16B)
eg:如果消息长度为124Byte(992bit=0X3E0),分为两组:64 + 60,由于第二组长度超过55(即不能为:0X80的1字节和消息长度的8字节留下至少9字节(55+9=64)),为了满足所有要求(①消息长度是512bit的整数倍;②64bit存放消息长度信息;③消息后面要紧接着一个‘1’)
则扩充后的组为三组。
第一组:
XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX(16B)
XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX(16B)
XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX(16B)
XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX(16B)
第二组:
XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX(16B)
XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX(16B)
XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX(16B)
XX XX XX XX XX XX XX XX XX XX XX XX 80 00 00 00(16B)
第三组:
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00(16B)
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00(16B)
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00(16B)
00 00 00 00 00 00 00 00 00 00 00 00 00 00 03 E0 (16B)
即分组填充的图解如下:
(2)分组与填充完成以后根据分组计算Wi:
Wi有80个即W0~W79,每组32bit。由512bit的分组来计算,其中W0~W15由512bit的分组信息直接分割而来:32 * 16 = 512。而胜剩余的组由前面的组组合计算而来,计算公式为:Wi = W(i-16) XOR W(i-14) XOR W(i-8) XOR W(i-3),图解如下:

不同分组的Wi不尽相同。每一分组都要重新根据分组内容计算Wi。
(3)80个Wi的80次循环进行Hash函数计算:
我们根据上面计算得到的Wi来进行具体的算法操作。操作的流程图如图所示:

蓝色虚线框内是每次循环的流程操作,我们上面说到散列值的长度为160bit,而这160bit是有初始值的,160bit分为5部分ABCDE,每部分32bit(5*32bit=160bit)。初始值为如图所示(注意:这是在x86的PC下按照小端格式写的,计算时也按小端计算,但是在输出时要按照大端格式输出):
A = 0X67452301
B = 0XEFCDAB89
C = 0X98BADCFE
D = 0X10325476
E = 0XC3D2E1F0
虚线框外是上一个分组计算完毕后的输出(第一组不存在上一个分组,初始值即为上面设定的常量),作为本组输入。同样本组输出作为下一组输入(最后一组不存在下一组输入,所以左后一组的输出便是最终的散列值结果)。
80个循环的步骤为:
①用上一组的散列值结果作为输入,赋值给A、B、C、D、E:
A = buffer[0];
B = buffer[1];
C = buffer[2];
D = buffer[3];
E = buffer[4];②进行位计算
for(i = 0; i < 80; i++){
tmp = E + func(B,C,D); //func(B,C,D)是以B,C,D作为输入,进行非线性Hash函数运算的操作
tmp += A <<< 5;//循环左移5位
tmp += Wi + Ki;//Wi共80个,不同Wi对应循环中不同的i,Ki为常量
E = D;
D = C;
C = B <<< 30;
B = A;
A = tmp
}循环中出现func()函数与Ki,Ki和func()在i确定时都是固定的,func()为哈希函数不可逆,Ki为四个由无理数算出来的常量:

③80次循环完成后,将第80次循环的输出A,B,C,D,E与上一组的输出相加,得到的结果为本组的输出,即:
buffer[0] += A;
buffer[1] += B;
buffer[2] += C;
buffer[3] += D;
buffer[4] += E;④如果还有下一组则,重复①~④步骤,如果不存在下一组,则输出散列值(按大端输出),结束操作。
3、算法基本实现:
#include "sha1.h"
void ShaAlgorithm(void)
{
//test用,可修改为文件操作
unsigned char plaintext[64] = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";//超过448bit
//unsigned char plaintext[64] = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
unsigned char ciphertext[20] = {0};//put last hash value
ShaMess sha;
ShaInit(&sha, strlen((const char *)plaintext));
ShaPadding(&sha, plaintext, strlen((const char*)plaintext));
ShaGetCiphertext(&sha, ciphertext);
}
void ShaGetCiphertext(ShaMess * sha, unsigned char * ciphertext)
{
//小端转大端
for(int i = 0; i < 5; i++){
put_uint32(&(sha->buffer[i]), ciphertext , i*4);
}
for(int i = 0; i < 20; i++){
printf("%02x",ciphertext[i]);
}
printf("\n");
}
void ShaInit(ShaMess * sha, uint32 file_length)
{
sha->length[1] = 0;
//length[0]要左移3位,所以高三位保存到length[1]中低三位
sha->length[1] = file_length >> 29;
sha->length[0] = file_length << 3;
sha->buffer[0] = 0X67452301;//A
sha->buffer[1] = 0XEFCDAB89;//B
sha->buffer[2] = 0X98BADCFE;//C
sha->buffer[3] = 0X10325476;//D
sha->buffer[4] = 0XC3D2E1F0;//E
}
void ShaPadding(ShaMess * sha, unsigned char * plaintext, int len)
{
printf("size = %d\n",len);
if(len < 56){//index < 55
printf("at padding if\n");
plaintext[len] |= 0X80;//补1,0不需要补,每次读取文件时已经初始化为0
//length信息进行大小端转换后放入plaintext的后64bit
//即长度信息的高位放在数组低字节地址
put_uint32(&(sha->length[0]), plaintext, 60);
put_uint32(&(sha->length[1]), plaintext, 56);
//可打印补位后的内存值的变化情况
ShaCalcHashValue(sha, plaintext);
}
else{
printf("at padding else\n");
//长度超过56Byte(56~64Byte),则需要补位(64-len + 56)B,还有8B存放长度信息(总共128B)
unsigned char * newPlaintext = (unsigned char *)malloc(128);
memset(newPlaintext, 0, 128);
memcpy(newPlaintext, plaintext, 64);
newPlaintext[len] |= 0X80;
put_uint32(&(sha->length[0]), newPlaintext, 124);
put_uint32(&(sha->length[1]), newPlaintext, 120);
ShaCalcHashValue(sha, newPlaintext);
ShaCalcHashValue(sha, newPlaintext + 64);
free(newPlaintext);
}
}
void ShaCalcHashValue(ShaMess * sha, unsigned char * plaintext)
{
uint32 w[80] = {0};
ShaCalcW(w,plaintext);//生成W0~W79
uint32 ki,tmp;
//初始化循环输入ABCDE
uint32 A = sha->buffer[0];
uint32 B = sha->buffer[1];
uint32 C = sha->buffer[2];
uint32 D = sha->buffer[3];
uint32 E = sha->buffer[4];
for(int i = 0; i < 80; i++){
tmp = E;
//判断选择Ki
if(i < 20)
ki = 0X5A827999;
else if(i<40)
ki = 0X6ED9EBA1;
else if(i<60)
ki = 0x8F1BBCDC;
else
ki = 0xCA62C1D6;
//判断选择对应的Hash Function
if(i < 20)
tmp += ((B & C) | ((~B) & D));
else if(i < 40 || i >= 60)
tmp += (B ^ C ^ D);
else
tmp += ((B & C) | (C & D) | (D & B));
tmp += LoopLeftMove(A, 5) + w[i] +ki;
//更新本次循环输出,即下次循环输入
E = D;
D = C;
C = LoopLeftMove(B,30);
B = A;
A = tmp;
}
//更新结果:最终将80次循环的结果+到原有结果的基础上
sha->buffer[0] += A;
sha->buffer[1] += B;
sha->buffer[2] += C;
sha->buffer[3] += D;
sha->buffer[4] += E;
}
void ShaCalcW(uint32 * w, unsigned char * plaintext)
{
/***************************************************************
*计算W0~W79:
*先将512bit的信息,分为32*16的16组即为W0~W15的16组
*其他的组由公式计算:
*Wt = {W(t-16) ^ W(t-14) ^ W(t-8) ^ W(t-3)}结果循环左移一位
***************************************************************/
for(int i = 0; i < 16; i++){
get_uint32(&(w[i]), plaintext, i*4);
}
//计算W16~W79
for(int i = 16; i < 80; i++){
w[i] = LoopLeftMove((w[i-16] ^ w[i-14] ^ w[i-8] ^ w[i-3]),1);
}
}
//4个8bit的信息转1个32bit的信息
void get_uint32(uint32 * n, void *b, int i){
(*n) = (((uint32)((uint8 *)b)[(i)+3]))
| (((uint32)((uint8 *)b)[(i)+2]) << 8)
| (((uint32)((uint8 *)b)[(i)+1]) << 16)
| (((uint32)((uint8 *)b)[(i)+0]) << 24);
}
//1个32bit的信息,合并为4个8bit的信息
void put_uint32(uint32 * n, void *b, int i)
{
((uint8 *)b)[(i)+3] = (uint8)(((*n)) & 0XFF);
((uint8 *)b)[(i)+2] = (uint8)(((*n) >> 8) & 0XFF);
((uint8 *)b)[(i)+1] = (uint8)(((*n) >> 16) & 0XFF);
((uint8 *)b)[(i)+0] = (uint8)(((*n) >> 24) & 0XFF);
}
//循环左移n位
uint32 LoopLeftMove(uint32 x, int n)
{
x = (x << n) | ((x & 0XFFFFFFFF) >> (32-n));
return x;
}
测试结果(用需要增加分组的字符串进行的测试):

测试代码下载:安全散列算法SHA-1
4、参考资料:
(1)、《应用密码学–协议算法与C源程序》[美]Bruce Schneier著 ,机械工业出版社。
(2)、《图解密码技术》[日]结城浩著,人民邮电出版社