论文浅尝 | HEAD-QA: 一个面向复杂推理的医疗保健数据集
论文笔记整理:谭亦鸣,东南大学博士生,研究方向为知识库问答。

来源:ACL2019
本文构建了一个面向复杂推理任务的多选问答数据集 HEAD-QA,该数据集中的问题来自一个西班牙的医疗保健专业测试,对于具备该方向专业知识的人也具有一定的挑战性。在原始数据的基础上,作者还考虑了“单语-即西班牙语”,“跨语言-西班牙语到英语”两种问答场景,分别使用信息检索和神经网络技术进行实验对比,并得到结论:1.HEAD-QA数据集对于当前的方法来说是具有相当难度的问答数据集;2.该数据集上的实验结果还远远低于人类回答者的水平,这表明其能够作为未来工作的benchmark。
表1是该数据集的一个示例:

动机
作者发现,对于现有的问答数据集如:bAbI,SQuAD 等,如今的问答系统已经能够取得接近于人类级别的答题性能,且这些问题往往都能够被“Surface-Level”的知识直接解答。因此,多选和推理类型的问题被提出用于自动问答的研究,早期问题集一般来自于学校,如小学的自然科学等学科,以及后来的中学或高中知识。但是这些数据集并没有涉足例如医药等复杂领域,因此,作者考虑构建这样一个数据集用于问答领域的研究工作。
贡献
作者认为本文的贡献如下:
构建了HEAD-QA,一个涵盖医疗保健多个子领域知识的高难度多选问答数据集,且包含西班牙语和英语两种版本;
在上述数据集的基础上,测试了当前面向开放域和多选的问答模型,体现出该数据集的复杂性以及其对于QA研究的实用性。
开源数据和模型链接:http://aghie.github.io/head-qa/
方法
数据集构建
Ministerio de Sanidad, Consumo y Bienestar Social(西班牙政府机构)每年举行的一个面向公众医疗保健领域的考试,作者收集了自2013年起至今的所有试题作为HEAD-QA的原始数据源,其中包含了以下子领域:医学,药理,心理学,护理,生物学和化学。其中2013-14年的多选题包含五个选项,其他年份均为四个选项,其问题内容主要面向技术,同时也包含一定的社会问题,其中约14%的问题含有图片作为问题的附加信息,由以下形式呈现:
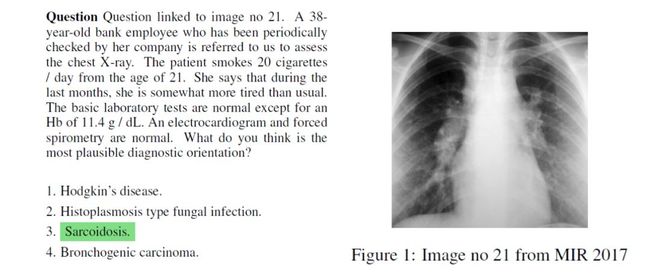
作者将数据整理为JSON结构并添加说明于文章的附录A中,每个问题的构成包含以下几点:
问题的ID和内容
问题对应的图片路径(如果有)
候选答案列表(包含答案序号和答案文本)
问题对应的正确答案ID
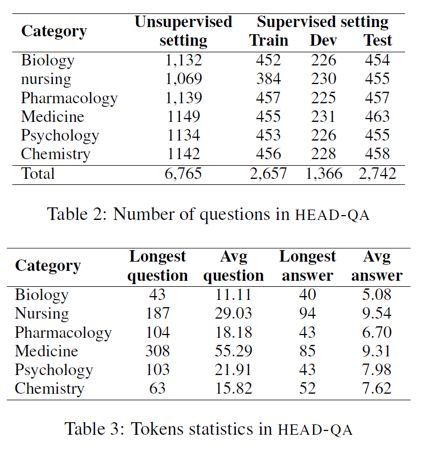
作者指出,虽然本文测试使用的模型均采用无监督或远程监督,但他们依然提供了训练集验证集和测试集供其他相关方法的研究使用。对于有监督方法,将2013-14数据作为训练集,2015作为验证集,其他年份数据作为测试集。相关统计信息如表2和表3所示:
作者表示,之所以没有使用随机抽取等常规构建训练集的方法有两个原因:
每年的问答数据均由专家人工构建,且主观上已经避免了考试内容可能存在的明显偏向性;
随机抽取可能破坏这种人工获得的优质问题分布
关于英文版本:虽然上述数据集仅有西班牙语官方版本,但作者使用Google翻译API将其译制为英文版本,从而用于跨语言问答实验。论文随机抽取了60个翻译样本(问答对)进行评估,发现翻译保留了原始问题绝大部分的题意。
测试方法
本文的测试基于信息检索(IR)模型,主要参照 Chen 等人(2017),作者以Wikipedia作为信息数据源,用于所有baseline中。输入问题仅为原始问题文本(移除了相关的ID,JSON结构信息)
西班牙语IR(单语问答)
IR方法上,沿用 DrQA’s Document Retriver(Chen et al., 2017),该方法能够对query和文本向量之间的关系进行打分。
跨语言方法
a) Multi-choice DrQA:
DrQA对于输入的问题,首先返回五个最相关的文本,接下来的任务是从中找出包含正确答案的文本范围(exact span),这一步利用一个神经网络模型(Attentive Reader,Hermann et al., 2015)来实现,该模型由SQuAD数据集训练得到。
b) Multi-choice BiDAF:
该方法与上述DrQA类似,但是用BiDAF方法作为文本阅读器,只是它的训练方式有所不同,除了使用SQuAD训练外,之后再利用science question进行继续训练,该方法可能选择到不止一个的正确答案,当出现这种情况时,作者会选择文本长度最长的那个作为最终选项。
c) Multi-choiceDGEM and Decompatt(Clark et al., 2018):
该方法采用DGEM和Decompatt用于IR,主要考虑将hypthesis hik=qi+aik,每个hi用作query从而检索到相关的文本句子,接着entailment分数用于衡量每个h与句子之间的相关性。
实验
论文采用准确度作为问答的评价指标,同时构建一种得分累计机制参与系统性能评价:即,答对加3分,答错扣1分。
以下是实验结果:
1. 非监督设定下的实验结果
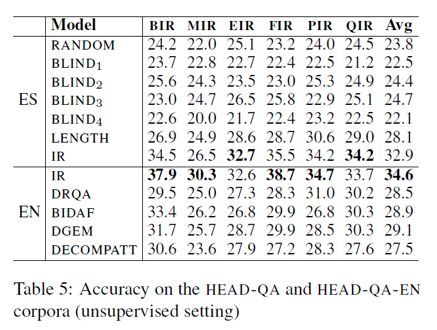
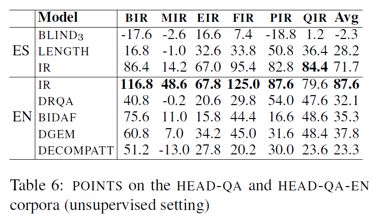
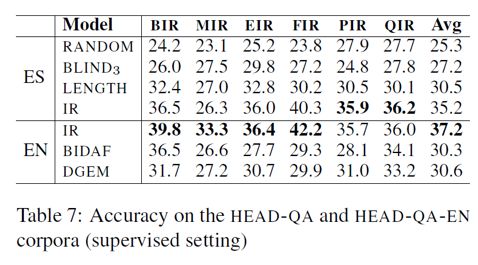
2. 监督设定下的实验结果
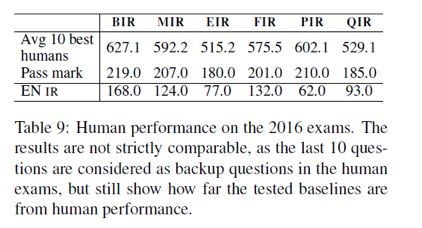
对比人工回答的实验结果如下:
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。