【论文解读 WSDM 2018 | SHINE】Signed HIN Embedding for Sentiment Link Prediction

论文链接:https://arxiv.org/abs/1712.00732
代码链接:https://github.com/boom85423/hello_SHINE
会议:WSDM 2018
这位大佬介绍得很清楚明了:https://boom85423.github.io/hello_SHINE/SHINE.slides.html
目录
1 摘要
2 介绍
2.1 动机
2.2 挑战
2.3 已有的方法
2.4 作者提出
3 数据集的建立
3.1 数据采集
3.2 情感抽取
4 方法
4.1 问题定义
4.2 SHINE
4.2.1 整体框架
4.2.2 Sentiment Network Embedding
4.2.3 Social Network Embedding
4.2.4 Profile Network Embedding
4.2.5 表示的聚合和情感预测
4.2.6 优化
4.2.7 分析
5 实验
6 总结
1 摘要
在社交网络中人们经常表达对彼此的看法,用户之间也就产生了大量的情感连接(sentiment links)。情感连接的预测在许多领域都是一项基本任务,例如个人广告以及公共舆论分析。先前的许多工作主要关注于基于文本的情感分类,忽略了用户的社会关系以及用户画像中包含的大量信息。为了解决这一问题,本文提出了如何在异质信息中,预测可能存在的情感连接。
首先,由于主流的社交网络缺少明确的情感连接信息,作者使用实体级别的情感抽取方法,建立了一个带标注的异质情感数据集,包含有用户的情感关联、社交关联以及用户画像知识。然后提出了端到端的模型SHINE,从异质网中抽取出用户的隐层表示,并用于情感连接的预测。SHINE使用了多个深度自编码器,在保留网络结构的同时,将每个用户节点映射到低维的特征空间。
作者在两个真实存在的数据集上,进行了链接预测和节点推荐任务,效果均优于state-of-the-art。同时实验结果还表明了SHINE在冷启动场景的功效。
2 介绍
社交网络中的情感连接和用户发表内容的语义信息有关,积极的情感连接例如“信任”或“支持”,消极的例如“讨厌”或“反对”。对于一个给定的情感连接,如何判断它是积极的还是消极的?这要根据从连接的发出者到接受者,相关的内容表达出了积极的还是消极的态度。像这样的情感连接组成的网络拓扑,被称作情感网络(sentiment network)。
2.1 动机
以往的工作主要是基于用户发表的具体内容进行情感分类,这种方法不能在没有先验的内容信息的情况下,发现情感连接,这会导致大量的可能存在的情感连接不能被发现。
如果没有先验的内容信息,该怎么预测情感连接?这类问题可以应用于个人广告、新朋友发现、舆论分析、民意调查等方面。
2.2 挑战
(1)情感标签的缺乏使得预测连接很难;
(2)情感生成的复杂性以及情感连接的稀疏性,使得算法很难实现较好的效果。
2.3 已有的方法
(1)过度依赖于人为设计特征,不能用于真实世界的数据中。
(2)一些network embedding的方法:IsoMap、拉普拉斯特征映射、DeepWalk、LINE、Node2vec、SDNE,可自动学习到用户的特征,但是只能用于有正加权的网络(unsigned),或者同质网络(边类型单一)。不适用于情感连接预测任务。
(3)还有一些针对异质网络的表示学习方法,属性网的表示学习、符号网(signed network)的表示学习(如SNE)。这些方法只能针对特定类型的网络,不能用于解决现实世界中异质网的情感预测问题。
2.4 作者提出
本文的工作旨在解决,在没有和情感有关的文本内容的条件下,预测社交网络中的情感连接。分为两步:
(1)由于缺少相关的标注数据,所以作者使用state-of-the-art的实体级别的情感抽取方法,从微博发帖中抽取出情感,以构建有标注的情感数据集。
为了解决稀疏性的问题,作者还收集了两种附加信息:用户之间的社会关系、用户画像的知识。
(2)提出端到端的SHINE模型(Signed Heterogeneous Information Network Embedding),可以学习到用户节点的表示,还能预测异质网络中的情感连接。SHINE使用了多个深度自编码器,分别从情感网络、社交网络、画像网络中抽取用户高度非线性的表示信息。然后通过聚合函数融合这三种表示,用于情感预测。
SHINE还方便附加信息模块(如社会关系、用户画像)的添加或删除。
3 数据集的建立
3.1 数据采集
(1)获取微博的帖子数据,使用Jieba分词标记推文中每个词的词性,选择含有标记为person name的单词所属的推文。根据作者建立的名人数据集,在分词时判断单词是否应被标记为person name。获得这些推文后,对每个推文计算其对所提到的名人的情感值(-1~+1),选择出打分的绝对值高的推文。最终的数据集由三元组(a, b, s)组成,a为发表推文的用户,b为推文中提到的名人,![]() 为用户a对名人b的情感值。如何计算情感值在后面介绍。
为用户a对名人b的情感值。如何计算情感值在后面介绍。
(2)社交关系数据集由二元组(a, b)组成,表示a关注了b。
(3)普通用户画像:抽取了性别和位置两个属性,表示成one-hot向量。
(4)名人用户画像:使用微软Satori3知识库并结合在微博中出现的频次,来提取名人的信息。抽取了9个属性(离散值):出生地、出生日期、种族、国籍、专业、性别、身高、体重和星座。用one-hot向量表示。
3.2 情感抽取
为了抽取出推文中用户对名人的情感信息,首先建立一个情感词典。词典由单词和其对应的情感(sentiment orientation: SO)分数组成。
为了建立词典,首先作者人为构建了“表情符号-情感”映射文件。推文中出现的表情符号,就可以映射成积极的或消极的情感。
但是表情符号不能直接看成情感,因为有大量不匹配的例子,例如:“Miss you Taylor Swift [cry][cry]”。根据文献[2]采用的方法,情感分数计算如下:
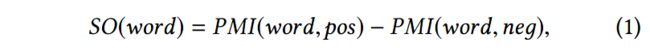
其中![]() ,pos和neg分别代表推文中的正类(积极)和负类(消极)。SO值随后会被归一化到[-1, 1]。
,pos和neg分别代表推文中的正类(积极)和负类(消极)。SO值随后会被归一化到[-1, 1]。
得到词典后,使用SentiCircle进行情感计算。给定一个提及名人的推文,将名人上下文的语义信息表示在极坐标空间中,代表名人的点位于原点,推文中的其他项表示为散点,分布在其周围。对于名人项c,项 的坐标为
的坐标为![]() 。其中
。其中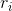 是使用LTP计算c和在句法依存树上的距离的倒数。
是使用LTP计算c和在句法依存树上的距离的倒数。![]() 。
。
推文表达的对于名人c的情感,可以用所有项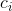 的几何中心表示。将几何中心映射到y轴上,相应的值作为对改名人的最终情感值。
的几何中心表示。将几何中心映射到y轴上,相应的值作为对改名人的最终情感值。
4 方法
4.1 问题定义
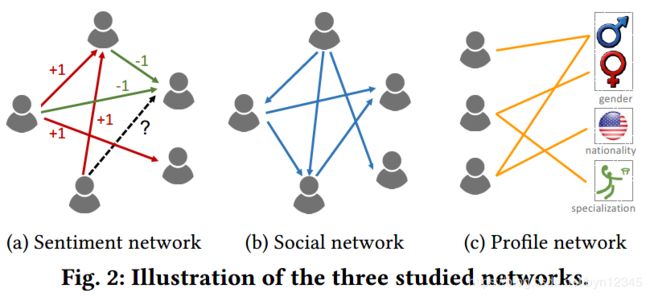
作者将问题形式化为在异质信息网络中预测情感连接,并将原始的异质网络分成如下三种单类型(只有一种类型的边)的网络:
(1)Sentiment network:![]() ,其中
,其中![]() 表示用户集合,
表示用户集合,![]() 表示用户之间的情感连接。
表示用户之间的情感连接。![]() 可取值为+1、-1或0,分别表示用户i对用户j的情感是正向的、负向的、中立的。
可取值为+1、-1或0,分别表示用户i对用户j的情感是正向的、负向的、中立的。
(2)Social network:![]() ,其中
,其中![]() 表示用户间的社交关系,
表示用户间的社交关系, 取值为1或0,代表用户i是否关注了用户j。
取值为1或0,代表用户i是否关注了用户j。
(3)Profile network:![]() 表示用户属性的集合,
表示用户属性的集合,![]() 表示属性
表示属性![]() 的第l个可能的取值。将属性的所有可能值组合起来,可表示成
的第l个可能的取值。将属性的所有可能值组合起来,可表示成![]() 。则无向的bitpartite profile network可以定义成
。则无向的bitpartite profile network可以定义成![]() ,其中
,其中![]() 表示用户节点和属性值的连接,
表示用户节点和属性值的连接,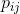 取值为1或0,表示有无连接。
取值为1或0,表示有无连接。
最终任务形式化为给定![]() 三个网络,在
三个网络,在![]() 中进行情感连接预测。
中进行情感连接预测。
三个网络如下图所示:
4.2 SHINE
4.2.1 整体框架
SHINE整体框架如下图所示:
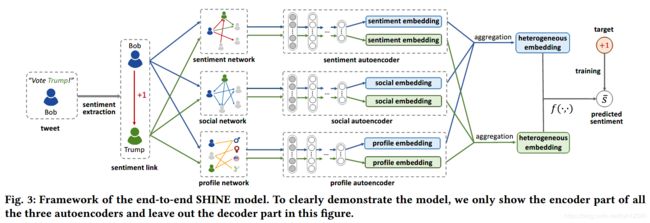
模型由三部分组成:(1)情感的抽取以及异质网的构建;(2)用户表示的抽取:(3)表示的聚合以及情感预测。
对于每个提及某一名人的推文,首先计算与之相关联的情感,并通过使用来自三个网络的用户和名人的邻居信息,来表示这条情感连接中的用户和名人(即使用节点的邻域信息来表示节点)。接着设计三个不同的自编码器,分别从稀疏的基于邻域的表示中,抽取短小稠密的节点表示。然后聚合这三种类型的表示,形成最终的异质网络节点表示。对两个节点嵌入,使用特定的相似度衡量函数(如:内积、logistic regression)就可以实现情感连接预测。基于预测结果和预测目标(情感抽取时获得的ground truth),就可以进行整个模型的训练。
4.2.2 Sentiment Network Embedding
给定情感网络![]() ,用户i的情感邻接向量定义为
,用户i的情感邻接向量定义为![]() 。不能用
。不能用 直接作为用户i的情感表示,因为这个邻接向量非常稀疏而且维度很大。已有的工作表明,深度自编码器可以捕获高度非线性的网络结构,生成低维的节点向量表示。自编码器由编码器和解码器两部分组成,编码器是将输入数据映射到表示空间,解码器从表示中重构出原始输入。SHINE就是使用自编码器,高效地进行用户节点的表示学习。为情感网络的嵌入学习设计的自编码器如下图所示:
直接作为用户i的情感表示,因为这个邻接向量非常稀疏而且维度很大。已有的工作表明,深度自编码器可以捕获高度非线性的网络结构,生成低维的节点向量表示。自编码器由编码器和解码器两部分组成,编码器是将输入数据映射到表示空间,解码器从表示中重构出原始输入。SHINE就是使用自编码器,高效地进行用户节点的表示学习。为情感网络的嵌入学习设计的自编码器如下图所示:
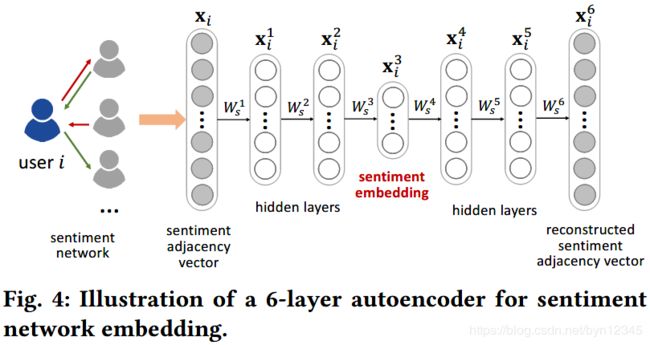
给定输入,每层的隐层表示计算如下:
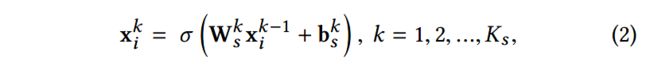
其中![]() 和
和![]() 是第k层的权重和偏移参数,
是第k层的权重和偏移参数,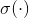 是非线性激活函数,
是非线性激活函数,![]() 是自编码器的层数,
是自编码器的层数,![]() ,定义
,定义![]()
![]() 为的重构。用户i的情感嵌入表示在第
为的重构。用户i的情感嵌入表示在第![]() 层获得。
层获得。
自编码器的目标就是最小化输入和输出的重构损失,损失函数定义如下:
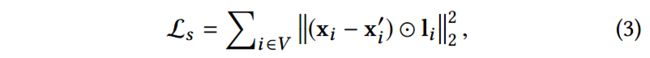
其中 表示哈达马乘积,
表示哈达马乘积,![]() 是重构的情感权重向量:
是重构的情感权重向量:
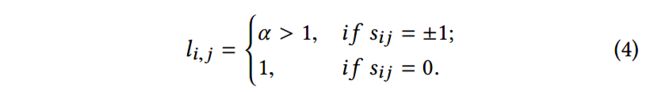
也就是说,为非零元素施加更多的惩罚,因为非零元素和零元素相比,含有更确切的情感信息。
4.2.3 Social Network Embedding
和情感网络嵌入相似,给定社交网络![]() ,用户i的情感邻接向量定义为
,用户i的情感邻接向量定义为![]() 。使用自编码器从社交网络中抽取出节点表示。每层的隐层表示计算如下:
。使用自编码器从社交网络中抽取出节点表示。每层的隐层表示计算如下:
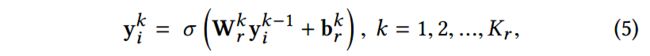
重构损失函数如下:

4.2.4 Profile Network Embedding
用户画像网络![]() 是一个无向bitpartite graph,由两个不相交的集合,用户集合和属性值集合组成。对于用户i,其profile adjacency vector定义为
是一个无向bitpartite graph,由两个不相交的集合,用户集合和属性值集合组成。对于用户i,其profile adjacency vector定义为![]() 。用户i在每层的隐层表示计算如下:
。用户i在每层的隐层表示计算如下:

重构损失函数如下:
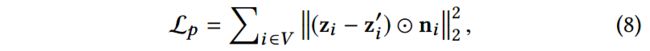
4.2.5 表示的聚合和情感预测
使用聚合函数![]() 将
将![]() 三个表示聚合为
三个表示聚合为![]() 。一些可用的聚合函数列举如下:
。一些可用的聚合函数列举如下:
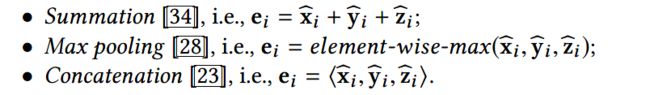
给定用户i和j的表示![]() ,使用
,使用![]() 进行相似度计算,从而进行情感预测。可用的相似度计算函数举例如下:
进行相似度计算,从而进行情感预测。可用的相似度计算函数举例如下:

4.2.6 优化
SHINE模型最终的目标函数如下所示:

第4项是有监督的损失项,根据预测结果和实际值计算而得。最后一项是正则项,以避免过拟合,计算如下:
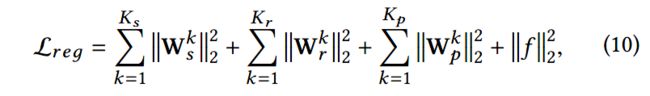
4.2.7 分析
(1)不对称性
SHINE可用于有向图,即边(i, j)和(j, i)的值不对称。选择合适的相似度计算函数f可以解决这个问题,即![]() ,例如logistic regression。若选择了对称的相似度计算函数(如内积或欧氏距离),仍然可以将原始的SHINE模型扩展成非对称感知的版本。具体方法是,设置两组不同的自编码器分别提取源节点和目标节点的表示。
,例如logistic regression。若选择了对称的相似度计算函数(如内积或欧氏距离),仍然可以将原始的SHINE模型扩展成非对称感知的版本。具体方法是,设置两组不同的自编码器分别提取源节点和目标节点的表示。
可以看出,在基本的SHINE模型中,为了缓解过拟合的问题,源节点和目标节点的自编码器参数是共享的。由于不对称的原因,可以明确地区分开两个自编码器。
(2)冷启动问题
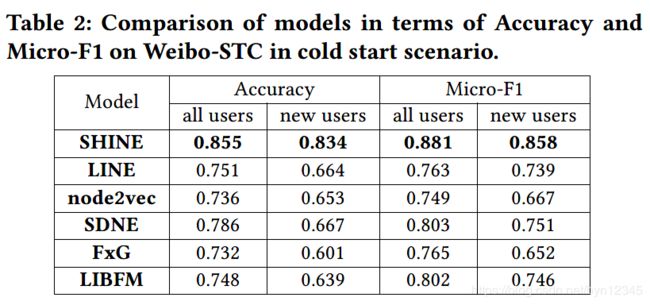
大多数方法不能解决冷启动问题,是因为它们仅仅使用了目标网络中的信息(如:本文的情感网络),而新来的节点在目标网络中几乎没有交互信息。SHINE可以解决这一问题,因为它充分利用了副信息,且自然地结合了目标网络,以学习到用户节点表示。【在实验中进一步说明了效果】
(3)灵活性
SHINE有高度的灵活性,对于新的用户的副信息(如:用户浏览历史),可以设计一个并行的组件,并将其插入到原始的SHINE框架中,以更好地进行表示学习。相反,若没有副信息,也可以从SHINE框架中撤出社交自编码器或者画像自编码器。
另外聚合函数和相似度计算函数,也可以灵活选择。
5 实验
数据集:Weibo-STC(作者创建)、Wiki-RfA。
实验任务:链接预测、节点推荐任务。
对比方法:
(1)LINE、Node2vec、SDNE:不适用于异质网,分别用于三个网络的节点表示学习;
(2)FxG:a signed link prediction approach,不能处理微博数据集中的副信息;
(3)LIBFM:分类模型。
实验结果:
(1)链接预测实验结果
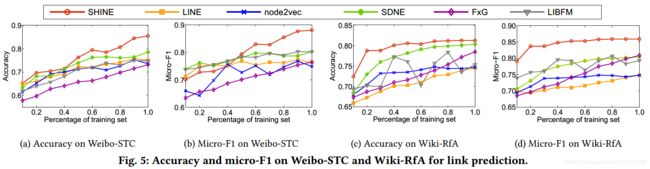
(2)节点推荐实验结果
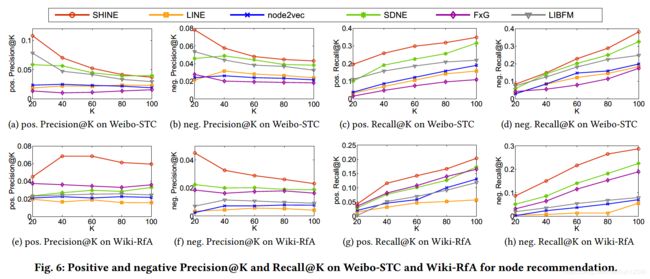
(3)冷启动问题实验结果
6 总结
本文提出SHINE模型,解决了在未知社交网络中情感相关内容的前提下,进行情感连接的预测问题。使用深度自编码器,在保留网络结构的同时,抽取出了用户节点高度非线性的表示。
在实验中和多个表现强劲的baseline比较,体现出了SHINE模型的竞争力。还阐释了使用社交关系信息和用户画像信息的有效性,尤其是在冷启动问题上表现出了较好的效果。