浏览器原理学习--如何保证页面文件能被完整地送达浏览器
在前后端交互过程中,前端页面所需要的一些页面信息是通过浏览器和后台服务器之间建立的TCP连接传输的。TCP连接就好比实实在在的运输通道,好比基础的交通设施,好比道路和桥梁,网络数据就在这些道路上运输,到达指定的目的地。
数据的运输之前,双方必须达成协议,就好比买卖双方必须提前沟通好信息:价格是多少,要几斤几两,要哪种成色的货物等。双方都达成共识了之后,交流才会是无障碍的。
如果传输数据太大,数据会被拆成一个个小的数据包分别发送,每个数据包会被标上描述顺序的标识,等到接收方拿到后,可以按照顺序重新组装成完成的数据。
数据发送之前,首先需要知道数据要发给谁,这就需要网际协议(Internet Protocol,简称 IP)来识标,互联网上每一台设备都有唯一的IP地址,就和我们的居住地址和门牌一样,必须唯一才能精确定位。
数据在传输前需要经过一层层的处理才能发送,首先需要把目标IP添加到数据包上,还需要把自己的IP也添加上去,这样目标处理好数据后才知道该把处理好的数据返回给谁。服务器拿到数据后会反向操作数据,即先拆开数据拿到IP相关信息,然后才拿到最里面的数据包。

浏览器上一般会运行多个程序,而区分这些程序的一个标准就是端口号,请求回来的数据应该给到哪个程序去消费,这就需要UDP来分配了,用户数据包协议(User Datagram Protocol)的作用就是把数据包送达应用程序。
UDP中包含当前程序运行的端口号,发送请求前,网络进程已经把端口号或页签标识放到数据头里了,取回数据后相关信息包括端口号一并带回来,让浏览器知道取回来的数据是从哪个程序发出的,位于哪个端口或页签上,并把数据给到对应的程序消费。
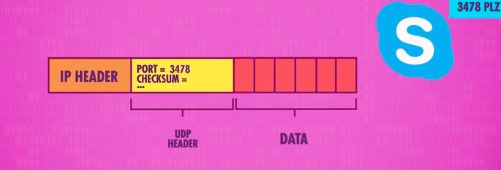
IP和端口号组合在一起共同起到了程序定位的作用,数据就有了明确的传输目的了。
IP负责把数据包送到正确的计算机,UDP负责把数据包送到正确的程序
UDP中还含有名为“校验和”的字段,用于校验数据是否正确

比如上面的例子,数据里是一些数字,算出校验和364,校验和会以二进制16位长度的形式存储,超过16位能表示的最大值就会丢弃高位,保留低位。接收方拿到数据后会重复这个步骤,计算校验和,如果不等于UDP中的值,则说明数据丢失了。
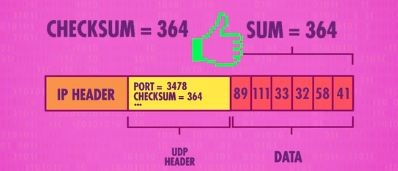
数据完好无损
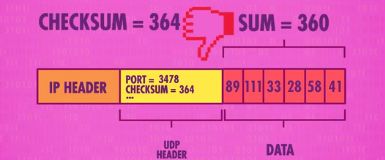
数据损坏或丢失
UDP传输数据的一个缺点就是容易丢包,且不提供数据修复和重传机制;并且UDP无法得知数据包是否送达。但是对于不在意一些数据丢失的程序来说,丢失一点数据是能接受的,因为UDP简洁快速。
比如视频通话,偶尔有点卡卡的,是因为部分数据丢失在了你的电脑上,但不影响正常通话。但对于一些对于数据完整性要求很高的程序,UDP的数据丢失就无法接受了,比如邮件和文件传输等,需求是所有数据必须送达。
TCP(Transmission Control Protocol,传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议
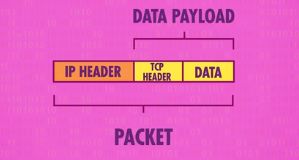
TCP信息依然放在数据头上,和UDP一样依然有端口信息
相较于UDP传输,TCP的有点有:
- 对于数据包丢失的情况,TCP 提供重传机制;
- TCP可以同时发多个包
- 根据拥堵情况动态调整传输率
- TCP 引入了数据包排序机制,用来保证把乱序的数据包组合成一个完整的文件。
TCP传输的主要流程和UDP差不多,除此之外还提供了用于排序的序列号,以便接收端通过序号来重排数据包,这样就保证了大数据包的完整传输。
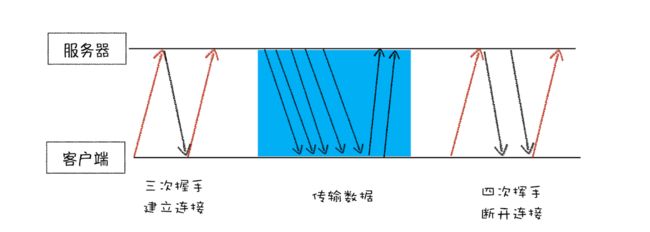
经典的三次握手四次挥手
为什么是3次握手呢?我理解的是,3次沟通是确定双方都有发送和接收信息的最少次数。第一次:a到b,能确保a有发送能力 ;第二次:b到a,能确保b有接收和发送能力;第三次:a到b,能确保a有接收能力。这样就能确保双方都有发送和接收能力,可以建立完整的连接了。
4次挥手依然是为了确保双方达成断开连接的共识的最少次数。a:我要断开连接了。b:好的,你断开吧。a(断开操作):我已经断开了。b:好的,我知道了(不在传输数据)。
TCP的数据重发和排序:
在传输数据阶段,接收端需要对每个数据包进行确认操作,也就是接收端在接收到数据包之后,需要发送确认码给发送端。所以当发送端发送了一个数据包之后,在规定时间内没有接收到接收端反馈的确认消息,则判断为数据包丢失,并触发发送端的重发机制。同样,一个大的文件在传输过程中会被拆分成很多小的数据包,这些数据包到达接收端后,接收端会按照 TCP 头中的序号为其排序,从而保证组成完整的数据。
但是如果是由于网络延迟等其它问题导致接受方没收到数据,但数据其实没有丢失,发送方触发了重发机制,这样接受方最后拿到的数据会有重复,由于有排序机制,就能把序号重复的数据剔除掉
一般情况下,通过确认码的成功率和返回时间可以推测网络的拥堵程度,TCP可以根据拥堵情况动态调整传输率
两点之间TCP数据包传输
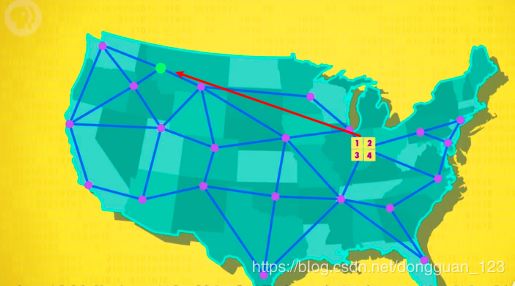

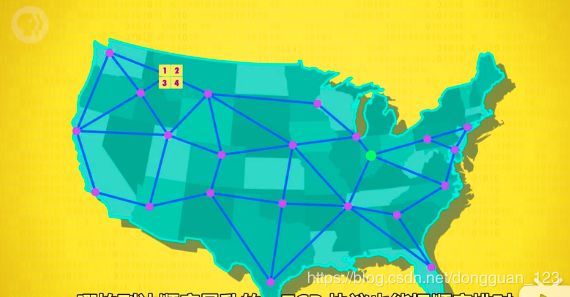
TCP有这么多有点,当然也优缺点
TCP中相同数量的确认码把传输数据包翻了一倍,但并没有传输更多的数据,对于有些程序而言,这样的代价是不划算的,比如在线射击游戏,卡顿是无法容忍的。所以实际应用当中会综合场景使用UDP和TCP。