分类问题的本质是确定样本 x x 属于类别 ci c i 的概率 p(Ci|x) p ( C i | x ) 。在上周整理的分类问题中,我们采用生成式方法,借助贝叶斯公式和极大似然估计,首先计算出 p(x|Ci) p ( x | C i ) 和 p(x,Ci) p ( x , C i ) ,然后再计算出 p(Ci|x) p ( C i | x ) 。以二分类为例:
p(C1|x)=p(C1,x)p(x)=p(x|C1)p(C1)p(x)=p(x|C1)p(C1)p(x|C1)p(C1)+p(x|C2)p(C2)(1) (1) p ( C 1 | x ) = p ( C 1 , x ) p ( x ) = p ( x | C 1 ) p ( C 1 ) p ( x ) = p ( x | C 1 ) p ( C 1 ) p ( x | C 1 ) p ( C 1 ) + p ( x | C 2 ) p ( C 2 )
如果 p(C1|x)>0.5 p ( C 1 | x ) > 0.5 ,则将 x x 归入类别 C1 C 1 ;如果 p(C1|x)<0.5 p ( C 1 | x ) < 0.5 ,则将 x x 归入类别 C2 C 2 。一般情况下,我们将 p(x|C1) p ( x | C 1 ) 和 p(x|C2) p ( x | C 2 ) 假设成服从不同 μ1 μ 1 , μ2 μ 2 但是相同 Σ Σ 的高斯分布。因为高斯分布是自然界中最常见的一种分布,两个分布同用一个协方差矩阵 Σ Σ 有助于减少参数数目,防止过拟合。
Logistic回归推导
现在我们尝试对上述后验概率(1)进行变形
p(C1|x)====p(x|C1)p(C1)p(x|C1)p(C1)+p(x|C2)p(C2)11+p(x|C2)p(C2)p(x|C1)p(C1)11+exp(−z)σ(z) p ( C 1 | x ) = p ( x | C 1 ) p ( C 1 ) p ( x | C 1 ) p ( C 1 ) + p ( x | C 2 ) p ( C 2 ) = 1 1 + p ( x | C 2 ) p ( C 2 ) p ( x | C 1 ) p ( C 1 ) = 1 1 + e x p ( − z ) = σ ( z )
其中 z=lnp(x|C1)p(C1)p(x|C2)p(C2) z = l n p ( x | C 1 ) p ( C 1 ) p ( x | C 2 ) p ( C 2 ) 。上面 σ(z)=11+exp(−z) σ ( z ) = 1 1 + e x p ( − z ) 正是Sigmoid函数,该函数具有良好的性质,能够将 z z 值转化为一个(0,1)区间内的值,并且 z=0 z = 0 时, σ(z)=0.5 σ ( z ) = 0.5 。同时该函数是单调连续可微的。Sigmoid函数的图像如下图所示:

现在还需要确定的是 z z 是什么,我们继续对 z z 进行推导
z=====lnp(x|C1)p(C1)p(x|C2)p(C2)lnp(x|C1)p(x|C2)+lnp(C1)p(C2)ln1(2π)D/21|Σ1|1/2exp{−12(x−μ1)T(Σ1)−1(x−μ1)}1(2π)D/21|Σ2|1/2exp{−12(x−μ2)T(Σ2)−1(x−μ2)}+lnN1N1+N2N2N1+N2ln|Σ2|1/2|Σ1|1/2−12[(x−μ1)T(Σ1)−1(x−μ1)−(x−μ2)T(Σ2)−1(x−μ2)]+lnN1N2(μ1−μ2)TΣ−1x−12(μ1)TΣ−1μ1+12(μ2)TΣ−1μ2+lnN1N2(2.4)(2.5) z = l n p ( x | C 1 ) p ( C 1 ) p ( x | C 2 ) p ( C 2 ) = l n p ( x | C 1 ) p ( x | C 2 ) + l n p ( C 1 ) p ( C 2 ) = l n 1 ( 2 π ) D / 2 1 | Σ 1 | 1 / 2 e x p { − 1 2 ( x − μ 1 ) T ( Σ 1 ) − 1 ( x − μ 1 ) } 1 ( 2 π ) D / 2 1 | Σ 2 | 1 / 2 e x p { − 1 2 ( x − μ 2 ) T ( Σ 2 ) − 1 ( x − μ 2 ) } + l n N 1 N 1 + N 2 N 2 N 1 + N 2 (2.4) = l n | Σ 2 | 1 / 2 | Σ 1 | 1 / 2 − 1 2 [ ( x − μ 1 ) T ( Σ 1 ) − 1 ( x − μ 1 ) − ( x − μ 2 ) T ( Σ 2 ) − 1 ( x − μ 2 ) ] + l n N 1 N 2 (2.5) = ( μ 1 − μ 2 ) T Σ − 1 x − 1 2 ( μ 1 ) T Σ − 1 μ 1 + 1 2 ( μ 2 ) T Σ − 1 μ 2 + l n N 1 N 2
其中从(2.4)到(2.5)是因为 Σ1=Σ2=Σ Σ 1 = Σ 2 = Σ 。再进一步观察式(2.5), (μ1−μ2)TΣ−1 ( μ 1 − μ 2 ) T Σ − 1 的结果是一个向量,而 x x 后面一串是一个数字,因此 z z 可以写成 z=wTx+b z = w T x + b 的形式,所以
p(C1|x)=σ(wTx+b)=11+e−(wTx+b)(3) (3) p ( C 1 | x ) = σ ( w T x + b ) = 1 1 + e − ( w T x + b )
上式(3)就称为Logistic 回归。在生成模型中,我们先求出 μ1 μ 1 , μ2 μ 2 , Σ Σ ,然后求出 w w 和 b b 。这样做难免显得太过复杂,我们希望直接找出 w w 和 b b 。结合机器学习的三个步骤,第一步确定一个模型 f(x) f ( x ) ,这一步已经完成 f(x)=p(C1|x) f ( x ) = p ( C 1 | x ) 。如果 p(C1|x)>0.5 p ( C 1 | x ) > 0.5 ,则输出 C1 C 1 ,否则输出 C2 C 2 。接下来需要做的是选择一个恰当的损失函数用以度量找出来的 w w 和 b b 的好坏。
Logistic回归损失函数
根据以往回归模型的经验,损失函数的选取第一反应是均方误差函数,因此我们首先尝试使用均方误差。为了使目标标签 C1 C 1 , C2 C 2 能够参与运算,我们需要将其数字化,规定:样本类别为 C1 C 1 , y^=1 y ^ = 1 ;样本类别为 C2 C 2 , y^=0 y ^ = 0 。因此损失函数可以写作:
L(f)=12∑i=1m(f(x(i))−y^(i))2 L ( f ) = 1 2 ∑ i = 1 m ( f ( x ( i ) ) − y ^ ( i ) ) 2
对其进行求导
∂(f(x)−y^)2∂wi=2(f(x)−y^)f(x)(1−f(x))xi ∂ ( f ( x ) − y ^ ) 2 ∂ w i = 2 ( f ( x ) − y ^ ) f ( x ) ( 1 − f ( x ) ) x i
具体分析,当 y^(i)=1 y ^ ( i ) = 1 , f(x(i))=0 f ( x ( i ) ) = 0 ,说明模型误差还很大,距离目标很远,但上式导数 ∂L(f(x(i)))/∂wi=0 ∂ L ( f ( x ( i ) ) ) / ∂ w i = 0 ;另一种情况,当 y^(i)=0 y ^ ( i ) = 0 , f(x(i))=1 f ( x ( i ) ) = 1 ,同样说明模型误差还很大,距离目标很远,但上式导数 ∂L(f(x(i)))/∂wi=0 ∂ L ( f ( x ( i ) ) ) / ∂ w i = 0 。而所有样本或者大多数样本的导数等于零时, ∂L/∂wi≈0 ∂ L / ∂ w i ≈ 0 ,参数将不再更新,但此时我们明显没有找到最佳参数,所以均方误差函数不是一个恰当的损失度量函数。
换一个角度思考,既然Logistic回归计算出了 p(C1|x) p ( C 1 | x ) ,那么对于那些属于 C2 C 2 类别的样本其概率为 p(C2|x)=1−p(C1|x) p ( C 2 | x ) = 1 − p ( C 1 | x ) 。我们同样可以采用极大似然法来估计 w w 和 b b ,即希望每个样本属于其真实标记的概率越大越好。
L(w,b)==ln∏i=1mp(y^(i)|x(i))∑i=1mlnp(y^(i)|x(i))(4) (4) L ( w , b ) = l n ∏ i = 1 m p ( y ^ ( i ) | x ( i ) ) = ∑ i = 1 m l n p ( y ^ ( i ) | x ( i ) )
又因为
p(y^(i)|x(i))=y^(i)f(x(i))+(1−y^(i))(1−f(x(i)))(5) (5) p ( y ^ ( i ) | x ( i ) ) = y ^ ( i ) f ( x ( i ) ) + ( 1 − y ^ ( i ) ) ( 1 − f ( x ( i ) ) )
将式(5)带入(4),同时将最大化变成最小化,可得
L(w,b)=−∑i=1m[y^(i)lnf(x(i))+(1−y^(i))ln(1−f(x(i)))](6) (6) L ( w , b ) = − ∑ i = 1 m [ y ^ ( i ) l n f ( x ( i ) ) + ( 1 − y ^ ( i ) ) l n ( 1 − f ( x ( i ) ) ) ]
上式(6)称为交叉熵(cross entropy)损失函数,同样采用梯度下降法求得最优解
w∗,b∗=argminw,bL(w,b) w ∗ , b ∗ = a r g min w , b L ( w , b )
寻找最佳参数
交叉熵损失函数虽然看起来形式复杂,但是求导并不复杂
∂L(w,b)∂wj=−∑i=1m(y^(i)−f(x(i)))x(i)j∂L(w,b)∂b=−∑i=1m(y^(i)−f(x(i))) ∂ L ( w , b ) ∂ w j = − ∑ i = 1 m ( y ^ ( i ) − f ( x ( i ) ) ) x j ( i ) ∂ L ( w , b ) ∂ b = − ∑ i = 1 m ( y ^ ( i ) − f ( x ( i ) ) )
求导结果与线性回归均方误差的导数一模一样。采用梯度下降算法更新参数
wi=wi−η∑i=1m−(y^(i)−f(x(i)))x(i)jb=b−η∑i=1m−(y^(i)−f(x(i))) w i = w i − η ∑ i = 1 m − ( y ^ ( i ) − f ( x ( i ) ) ) x j ( i ) b = b − η ∑ i = 1 m − ( y ^ ( i ) − f ( x ( i ) ) )
关于交叉熵损失函数与均方误差损失函数的对比可以参考下图
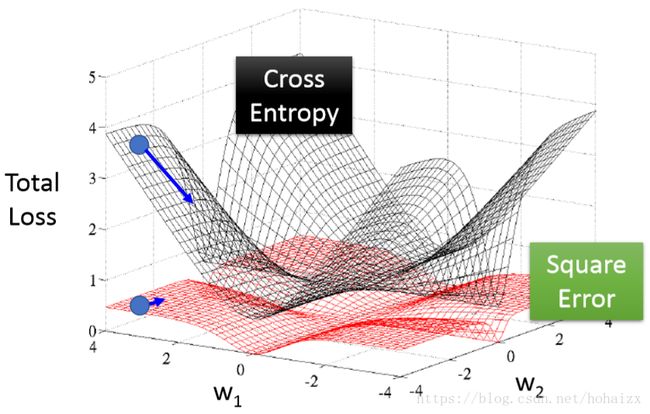
可以看出均方误差损失函数的曲面近乎是平坦的,因此梯度下降很容易停下来,而交叉熵损失函数则不会出现这个问题。
总结
Logistic回归相较于生成式模型操作简单,并且准确率也比较的高,但这并不表明Logistic回归能够解决所有的二分类问题,因为Logistic回归的分界面是一个平面,因此对于线性不可分问题,Logistic回归将束手无策,需要借助更加复杂的分类器。
参考文献
李宏毅机器学习2017年秋