《华为机试在线训练》之数据分类处理
题目描述
信息社会,有海量的数据需要分析处理,比如公安局分析身份证号码、 QQ 用户、手机号码、银行帐号等信息及活动记录。
采集输入大数据和分类规则,通过大数据分类处理程序,将大数据分类输出。
输入描述:
一组输入整数序列I和一组规则整数序列R,I和R序列的第一个整数为序列的个数(个数不包含第一个整数);整数范围为0~0xFFFFFFFF,序列个数不限
输出描述:
从R依次中取出R<i>,对I进行处理,找到满足条件的I
I
按R<i>从小到大的顺序:
(1)先输出R<i>;
(2)再输出满足条件的I
(3)然后输出满足条件的I
(4)最后再输出I
附加条件:
(1)R<i>需要从小到大排序。相同的R<i>只需要输出索引小的以及满足条件的I
(2)如果没有满足条件的I
(3)最后需要在输出序列的第一个整数位置记录后续整数序列的个数(不包含“个数”本身)
序列I:15,123,456,786,453,46,7,5,3,665,453456,745,456,786,453,123(第一个15表明后续有15个整数)
序列R:5,6,3,6,3,0(第一个5表明后续有5个整数)
输出:30, 3,6,0,123,3,453,7,3,9,453456,13,453,14,123,6,7,1,456,2,786,4,46,8,665,9,453456,11,456,12,786
说明:
30----后续有30个整数
3----从小到大排序,第一个R为0,但没有满足条件的I
6--- 存在6个包含3的I
0--- 123所在的原序号为0
123--- 123包含3,满足条件
输入
15 123 456 786 453 46 7 5 3 665 453456 745 456 786 453 123
5 6 3 6 3 0
输出
30 3 6 0 123 3 453 7 3 9 453456 13 453 14 123 6 7 1 456 2 786 4 46 8 665 9 453456 11 456 12 786
一,输入数据
题目中要求输入一组输入整数序列I和一组规则整数序列R,I和R序列的第一个整数位序列的个数,个数不包含第一个整数,整数范围为0~0xFFFFFFFF,序列个数不限制。
这个时候是不是可以考虑使用vector容器,输入代码如下
vectorA;
vectorB;
for(int i=0;i>temp;
A.push_back(temp);
}
cin>>n;
for(int i=0;i>temp;
B.push_back(temp);
} 将要输入的数据压入容器中,每次都排在最后。
二,排序和去重处理
这里排序就使用sort()进行处理,去重就使用unqiue()和erase()函数。代码如下:
sort(B.begin(),B.end()); //排序
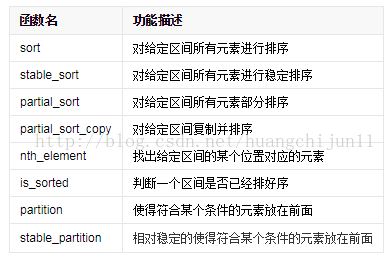
B.erase(unique(B.begin(),B.end()),B.end()); //删除重复的元素 在这里将一下sort()函数的用法,用于C++中,对给定区间所有元素进行排序。头文件是#include
#include
#include
using namespace std;
int main()
{
int a[10]={9,6,3,8,5,2,7,4,1,0};
for(int i=0;i<10;i++)
cout< unique是STL中很实用的函数之一,需要#include
int ans=unique(num,num+10)-num;
这时,返回的ans是5,而num中前5项就是1,2,3,4,5,一般使用前需要对容器进行排序,这样才能实现对整个数组去重。
另:如果要对结构体进行这一操作,需要重载运算符"==",具体要根据自己需要重载。
erase()函数的用法,erase()函数用于在顺序型容器中删除容器的一个元素,有两种函数原型,c.erase(p),c.erase(b,e);第一个删除迭代器p所指向的元素,第二个删除迭代器b,e所标记的范围内的元素,c为容器对象,返回值都是一个迭代器,该迭代器指向被删除元素后面的元素(这个是重点),具体的详细用法请参考其他资料。
三,匹配和处理
这里写了一个匹配处理的子函数,用来匹配R序列中与I序列中相同的地方,代码如下:
bool or_match(int m,int n)
{
string str1=to_string(m);
string str2=to_string(n);
int pos = str2.find(str1);
if(pos!=-1)
return true;
else
return false;
}
vector index;
vector value;
vector cnt;
vector index1;
for(unsigned int i=0;i 四,结果输出
int j=0;
cout<<2*index.size()+index1.size()+cnt.size()<<' ';
for(int i=0;i0)
{
cout< #include
#include
#include
#include
using namespace std;
bool or_match(int m,int n)
{
string str1=to_string(m);
string str2=to_string(n);
int pos = str2.find(str1);
if(pos!=-1)
return true;
else
return false;
}
int main()
{
int m,n;
while(cin>>m)
{
vectorA;
vectorB;
for(int i=0;i>temp;
A.push_back(temp);
}
cin>>n;
for(int i=0;i>temp;
B.push_back(temp);
}
sort(B.begin(),B.end()); //排序
B.erase(unique(B.begin(),B.end()),B.end()); //删除重复的元素
vector index;
vector value;
vector cnt;
vector index1;
for(unsigned int i=0;i0)
{
cout< https://www.nowcoder.com/questionTerminal/9a763ed59c7243bd8ab706b2da52b7fd