图像学习-验证码识别

阅读全文
正文共7318个字,11张图,预计阅读时间19分钟。
这是去年博主心血来潮实现的一个小模型,现在把它总结一下。由于楼主比较懒,网上许多方法都需要切割图片,但是楼主思索了一下感觉让模型有多个输出就可以了呀,没必要一定要切割的吧?切不好还需要损失信息啊!本文比较简单,只基于传统的验证码。
part 0、模型概览
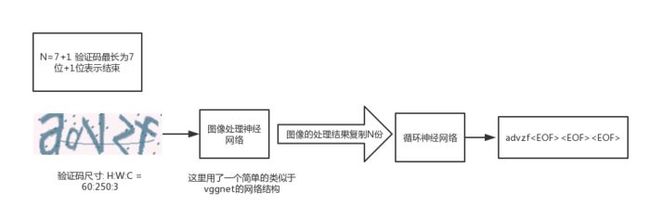
captcha_overview.png
从图片到序列实际上就是Image2text也就是seq2seq的一种。encoder是Image, decoder是验证码序列。由于keras不支持(现在已经支持了)传统的在decoder部分每个cell输出需要作为下一个rnn的cell的输入(见下图),所以我们这里把decoder部分的输入用encoder(image)的最后一层复制N份作为decoder部分的每个cell的输入。
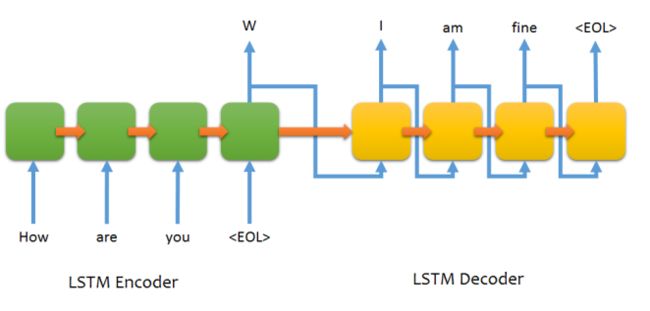
典型的seq2seq
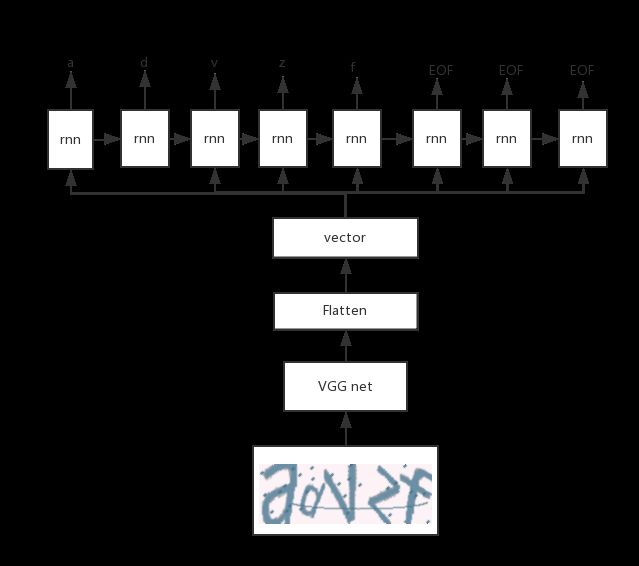
keras可以直接实现的image2text
当然利用recurrentshop和seq2seq,我们也可以实现标准的seq2seq的网络结构(后文会写)。
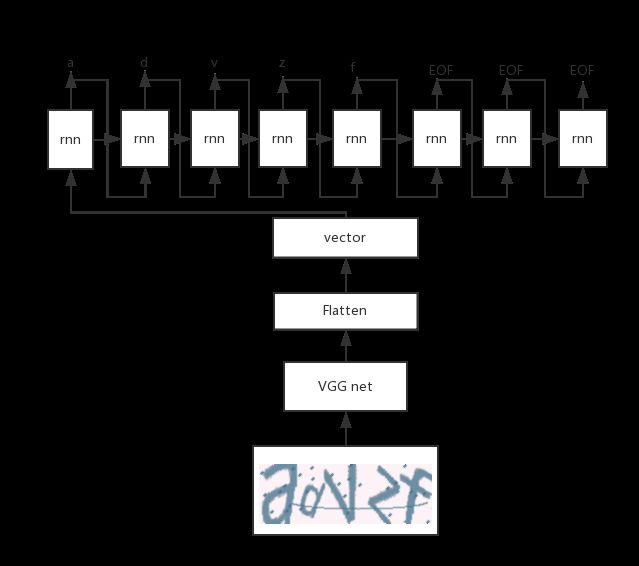
用seq2seq可以实现的模型结构
part1、收集数据
网上还是有一些数据集可以用的,包括dataCastle也举办过验证码识别的比赛,都有现成的标注好了的数据集。(然而难点是各种花式验证码啊,填字的,滑动的,还有那个基于语义的reCaptcha~)。
因为我想弄出各种长度的验证码,所以我还是在github上下载了一个[生成验证码](http
s://github.com/lepture/captcha)的python包。
下载后,按照例子生成验证码(包含26个小写英文字母):
#!/usr/bin/env python# -*- coding: utf-8from captcha.image import ImageCaptchafrom random import sampleimage = ImageCaptcha() #fonts=[ "font/Xenotron.ttf"]characters = list("abcdefghijklmnopqrstuvwxyz")def generate_data(digits_num, output, total): num = 0 while(num
产生的验证码

abdt.png

abvst.png
adkogvw.png
(目测了一下生成验证码的包的代码,发现主要是在x,y轴上做一些变换,加入一些噪音)
part2、预处理
由于生成的图片不是相同尺寸的,为了方便训练我们需要转换成相同尺寸的。另外由于验证码长度不同,我们需要在label上多加一个符号来表示这个序列的结束。
处理之后的结果就是图像size全部为Height=60, Width=250, Channel=3。label全部用字符id表示,并且末尾加上表示
由于我们用的是categorical_crossentropy来判断每个输出的结果,所以对label我们还需要把其变成one-hot的形式,那么用Keras现成的工具to_categorical函数对上面的label做一下处理就可以了。比如abdf的label进一步转换成:
[[1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1]]
不借助外部包可以实现的模型
def create_simpleCnnRnn(image_shape, max_caption_len,vocab_size): image_model = Sequential() # image_shape : C,W,H # input: 100x100 images with 3 channels -> (3, 100, 100) tensors. # this applies 32 convolution filters of size 3x3 each. image_model.add(Convolution2D(32, 3, 3, border_mode='valid', input_shape=image_shape)) image_model.add(BatchNormalization()) image_model.add(Activation('relu')) image_model.add(Convolution2D(32, 3, 3)) image_model.add(BatchNormalization()) image_model.add(Activation('relu')) image_model.add(MaxPooling2D(pool_size=(2, 2))) image_model.add(Dropout(0.25)) image_model.add(Convolution2D(64, 3, 3, border_mode='valid')) image_model.add(BatchNormalization()) image_model.add(Activation('relu')) image_model.add(Convolution2D(64, 3, 3)) image_model.add(BatchNormalization()) image_model.add(Activation('relu')) image_model.add(MaxPooling2D(pool_size=(2, 2))) image_model.add(Dropout(0.25)) image_model.add(Flatten()) # Note: Keras does automatic shape inference. image_model.add(Dense(128)) image_model.add(RepeatVector(max_caption_len)) # 复制8份 image_model.add(Bidirectional(GRU(output_dim=128, return_sequences=True))) image_model.add(TimeDistributed(Dense(vocab_size))) image_model.add(Activation('softmax')) sgd = SGD(lr=0.002, decay=1e-6, momentum=0.9, nesterov=True) image_model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy']) return image_model
借助recurrentshop和seq2seq可以实现的结构
def create_imgText(image_shape, max_caption_len,vocab_size): image_model = Sequential() # image_shape : C,W,H # input: 100x100 images with 3 channels -> (3, 100, 100) tensors. # this applies 32 convolution filters of size 3x3 each. image_model.add(Convolution2D(32, 3, 3, border_mode='valid', input_shape=image_shape)) image_model.add(BatchNormalization()) image_model.add(Activation('relu')) image_model.add(Convolution2D(32, 3, 3)) image_model.add(BatchNormalization()) image_model.add(Activation('relu')) image_model.add(MaxPooling2D(pool_size=(2, 2))) image_model.add(Dropout(0.25)) image_model.add(Convolution2D(64, 3, 3, border_mode='valid')) image_model.add(BatchNormalization()) image_model.add(Activation('relu')) image_model.add(Convolution2D(64, 3, 3)) image_model.add(BatchNormalization()) image_model.add(Activation('relu')) image_model.add(MaxPooling2D(pool_size=(2, 2))) image_model.add(Dropout(0.25)) image_model.add(Flatten()) # Note: Keras does automatic shape inference. image_model.add(Dense(128)) image_model.add(RepeatVector(1)) # 为了兼容seq2seq,要多包一个[] #model = AttentionSeq2Seq(input_dim=128, input_length=1, hidden_dim=128, output_length=max_caption_len, output_dim=128, depth=2) model = Seq2Seq(input_dim=128, input_length=1, hidden_dim=128, output_length=max_caption_len, output_dim=128, peek=True) image_model.add(model) image_model.add(TimeDistributed(Dense(vocab_size))) image_model.add(Activation('softmax')) image_model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return image_model
之前写过固定长度的验证码的序列准确率可以达到99%,项目可以参考这里。
另外,我们在用Keras训练的时候会有一个acc,这个acc是指的一个字符的准确率,并不是这一串序列的准确率。也就是说在可以预期的情况下,如果你的一个字符的准确率达到了99%,那么如果你的序列长度是5的时候,理论上你的序列准确率是0.99^5 = 0.95, 如果像我们一样序列长度是7,则为0.99^8=0.923。
所以当你要看到实际的验证集上的准确率的时候,应该自己写一个callback的类来评测,只有当序列中所有的字符都和label一样才可以算正确。
class ValidateAcc(Callback): def __init__(self, image_model, val_data, val_label, model_output): self.image_model = image_model self.val = val_data self.val_label = val_label self.model_output = model_output def on_epoch_end(self, epoch, logs={}): # 每个epoch结束后会调用该方法 print '\n———————————--------' self.image_model.load_weights(self.model_output+'weights.%02d.hdf5' % epoch) r = self.image_model.predict(val, verbose=0) y_predict = np.asarray([np.argmax(i, axis=1) for i in r]) val_true = np.asarray([np.argmax(i, axis = 1) for i in self.val_label]) length = len(y_predict) * 1.0 correct = 0 for (true,predict) in zip(val_true,y_predict): print true,predict if list(true) == list(predict): correct += 1 print "Validation set acc is: ", correct/length print '\n———————————--------'val_acc_check_pointer = ValidateAcc(image_model,val,val_label,model_output)
记录每个epoch的模型结果
check_pointer = ModelCheckpoint(filepath=model_output + "weights.{epoch:02d}.hdf5")
训练
image_model.fit(train, train_label, shuffle=True, batch_size=16, nb_epoch=20, validation_split=0.2, callbacks=[check_pointer, val_acc_check_pointer])
在39866张生成的验证码上,27906张作为训练,11960张作为验证集。
第一种模型:
序列训练了大约80轮,在验证集上最高的准确率为0.9264, 但是很容易变化比如多跑一轮就可能变成0.7,主要原因还是因为预测的时候考虑的是整个序列而不是单个字符,只要有一个字符没有预测准确整个序列就是错误的。
第二种模型:
第二个模型也就是上面的create_imgText,验证集上的最高准确率差不多是0.9655(当然我没有很仔细的去调参,感觉调的好的话两个模型应该是差不多的,验证集达到0.96之后相对稳定)。
part 6 、其它
看起来还是觉得keras实现简单的模型会比较容易,稍微变形一点的模型就很纠结了,比较好的是基础的模型用上其他包都可以实现。keras 2.0.x开始的版本跟1.0.x还是有些差异的,而且recurrentshop现在也是支持2.0版本的。如果在建模型的时候想更flexible一点的话,还是用tensorflow会比较好,可以调整的东西也比较多,那下一篇可以写一下img2txt的tensorflow版本。
part 7、代码
代码戳这里(https://github.com/Slyne/CaptchaVariLength)
part 8、后续
现在的这两个模型还是需要指定最大的长度,后面有时间会在训练集最多只有8个字符的情况下,利用rnn的最后一层进一步对于有9个以及以上字符的验证码效果,看看是不是可以再进一步的扩展到任意长度。(又立了一个flag~)
原文链接:https://www.jianshu.com/p/bce3b2850406
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看

LSTM模型在问答系统中的应用
基于TensorFlow的神经网络解决用户流失概览问题
最全常见算法工程师面试题目整理(一)
最全常见算法工程师面试题目整理(二)
TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络
装饰器 | Python高级编程
今天不如来复习下Python基础
