爬虫:用Python爬取招聘职位信息&职位需求分析
用Python爬取智联招聘网站“数据分析”相关岗位信息
# _*_ coding: utf-8 _*_
from bs4 import BeautifulSoup
import requests
import csv
import json
import pandas as pd
import numpy as np
#定义函数:请求下载页面源代码
def download(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0'}
req=requests.get(url,headers=headers)
return req.text#定义函数:解析网页内容,抓取职位信息
def get_content(html):
soup=BeautifulSoup(html,'lxml')
body=soup.body
data_main=body.find('div',{'class':'newlist_list_content'})#找div标签的特定属性
tables=data_main.find_all('table')
zw_list=[]
for i,table in enumerate(tables):
if i==0:
continue
temp=[]
tbs=table.find('tr').find_all('td')#find_all形成的是list
zwmc=tbs[0].find('a').get_text()
gsmc=tbs[2].find('a').get_text()
zwyx=tbs[3].get_text()
gzdd=tbs[4].get_text()
bt_brief=table.find('tr',{'class':'newlist_tr_detail'})
brief=bt_brief.find('li',{'class':'newlist_deatil_two'}).get_text()
temp.append(zwmc)
temp.append(gsmc)
temp.append(zwyx)
temp.append(gzdd)
temp.append(xl)
zw_list.append(temp)
return zw_list#根据智联招聘URL的特性,使用上述函数循环抓取前10页面
basic_url='http://sou.zhaopin.com/jobs/searchresult.ashx?jl=北京&kw=数据分析&isadv=2&p='#地址一定要写对好不啦
dataji=[]
for i in range(10):
num=i+1
url=basic_url+str(num)
html=download(url)
print html
data=get_content(html)
dataji.extend(data)#将一个list全部元素添加到另一个list中
#转换打印格式
datajson=json.dumps(dataji,ensure_ascii=False)#python中包含在列表或字典中的汉字自动以unicode形式输出,所以需要转换,type也变了
print datajson
#更改数组的栏目名称
datas=pd.DataFrame(dataji,columns=['positionName','companyShortName','salary','city','education'])#将list转为数据框格式
#生成excel文件到本地
data=datas.to_excel('D://shujv1.xls')#借助dataframe的方法导出excel文件生成的excel数据中的“education”字段信息过多,不止学历,需要从中摘取学历的部分,学历虽有空值,但都是2个字,所以学历在excel中可以用以下方法提取:=MID(单元格编号,FIND(“学历”,单元格编号)+3,2)
数据分析岗位分析&可视化:
df=pd.read_csv('D://DataAnalyst.csv',encoding='gb2312')
#定义工资上限、工资下限
def cutword(word,method):
position=word.find('-')
lenth=len(word)
if position!= -1:
bottomsalary=word[:position-1]#切片右边的不是闭合的,所以不包含右边
topsalary=word[position+1:lenth-1]
else:
bottomsalary=word[:word.upper().find('K')]
topsalary=bottomsalary
if method=='bottom': #无论是'bottom'或‘top’都是自己设定的第二个参数,在调用函数的时候选择其一就好
return bottomsalary
else:
return topsalary
#计算工资上限、工资下限
df_duplicates['topsalary']=df_duplicates.salary.apply(cutword,method='top')
df_duplicates['bottomsalary']=df_duplicates.salary.apply(cutword,method='bottom')
df_duplicates.topsalary=df_duplicates.topsalary.astype('int')
df_duplicates.bottomsalary=df_duplicates.bottomsalary.astype('int')
#计算平均工资
df_duplicates['avgsalary']=df_duplicates.apply(lambda x:(x.bottomsalary+x.topsalary)/2,axis=1) #axis=1表示将函数用在行
df_clean=df_duplicates[['city','companyShortName','companySize','education','positionName','positionLables','avgsalary','workYear']]#都是方括号
df_clean.head()#查看前五条数据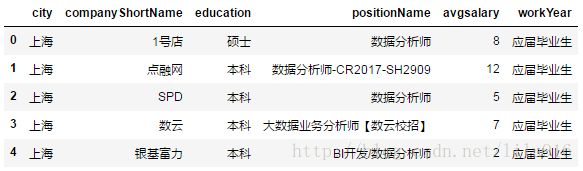
df_clean.city.value_counts()
#value_counts是计数,统计所有非零元素的个数,以降序的方式输出Series count是所有非零或零都统计
数据分析方面招聘最多的是北京、上海、深圳、杭州、广州等一线城市地区。
df_clean.avgsalary.describe()
全国数据分析职位的平均工资为16.898231k,波动在上下9k,差异较大,最高为75k,最低为1k。
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')#R语言中的ggplot2配色作为绘图风格,纯粹为了好看
df_clean.avgsalary.hist()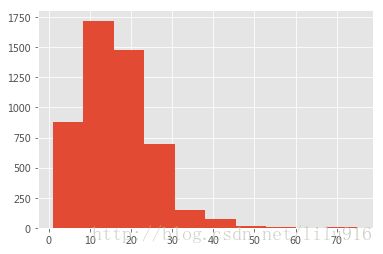
全国数据分析职位的平均工资主要集中在10-20k左右,10k一下也较多。
df_clean.avgsalary.hist(bins=20)#pandas封装过的方法作图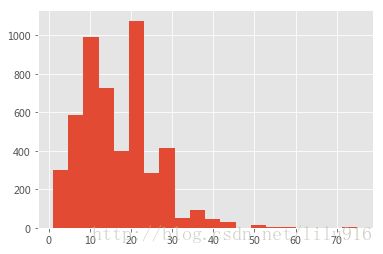
上面的柱状图的间隔太大(分为10个区间),不能凸显平均工资的分布细节,改进之后,分为20个取值区间,可以看出除了5-15k左右有工资高峰之外,在20k也有取值高峰,大于30k的工资就很少了。
df_clean.boxplot(column='avgsalary',by='city',figsize=(9,7))#matplotlib 中文字体显示为白框的时候 可以通过设置配置文件里的字体,改成微软雅黑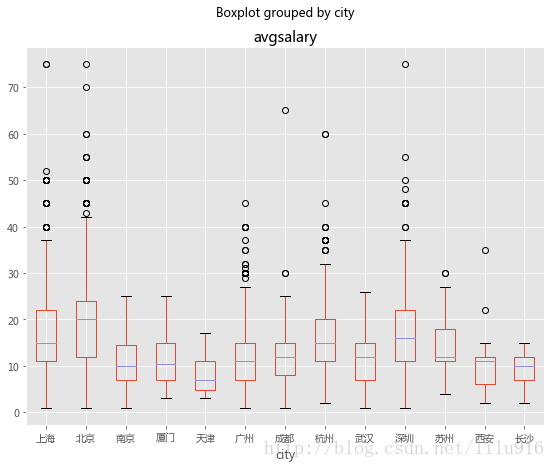
不同地区工资的箱线图可以看出,北京的工资全国领先,其次是上海、深圳和杭州,这四个地区的前1/4工资有达到20k,并且上限很高,当地的工资的差异也很大。
df_clean.boxplot(column='avgsalary',by='education',figsize=(9,9))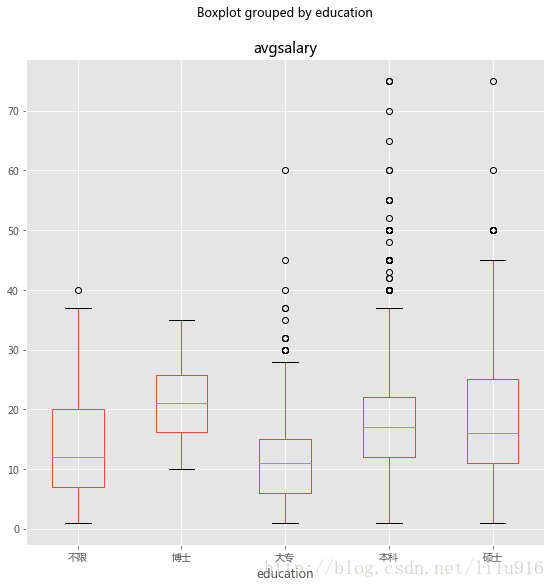
博士学历的平均工资高于其它学历,且最低工资相对其它学历来说也较高,硕士和本科的学历工资水平高于大专的学历。
df_clean.sort_values("workYear")
df_clean.boxplot(column='avgsalary',by='workYear',figsize=(9,7))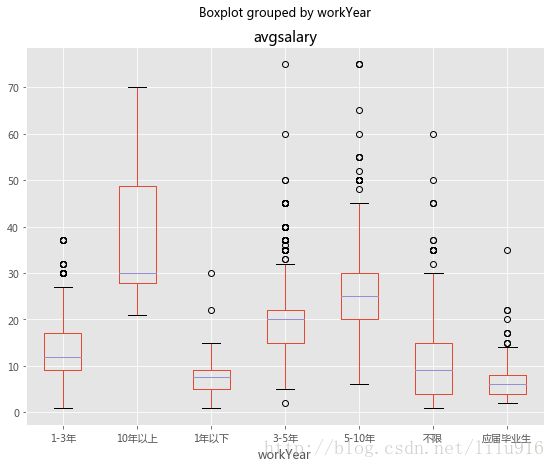
数据分析职位很看重工作经验,随着工作年限增长,工资水平逐渐提高,10年以上的数据分析师平均工资达30k左右,而应届生出来,工资一般为小于10k,也有少数大于10k。
df_bj_sh=df_clean[df_clean['city'].isin([u'上海',u'北京'])] #输入中文运行错误,因为是py2.7版本,不是py3.所以需要将中文表示成u"中文"
df_bj_sh.boxplot(column='avgsalary',by=['education','city'],figsize=(9,7))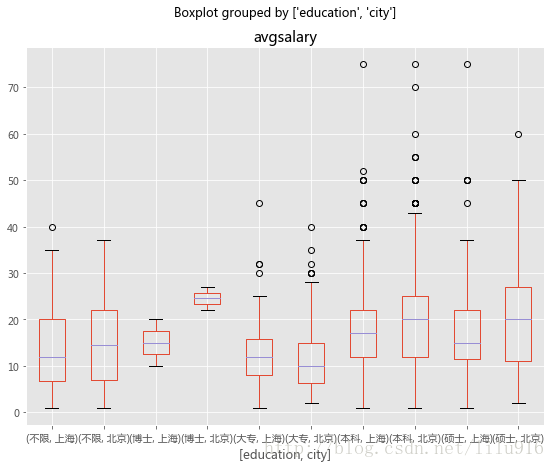
工资水平最高的上海和北京数据分析师工资对比,发现,无论什么学历,北京的待遇还是总体要高于上海,尤其是博士学位,北京的最低工资要高于上海的虽高工资,说明帝都人才十分重视,尤其是高学历的博士。
df_clean.groupby('companyShortName').avgsalary.agg(['count','mean']).sort_values(by='count',ascending=False)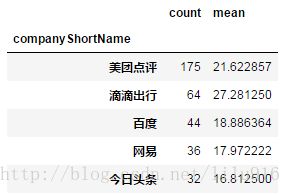
对该岗位需求最高的企业前5名是美团、滴滴、百度、网易和今日头条,都是互联网大公司,说明企业规模越大,对于数据分析的需求越高。
def topN(df,n=5):#先计数,后排序
df_con=df.value_counts()
return df_con.sort_values(ascending=False)[:5]
df_clean.groupby('city').companyShortName.apply(topN)
这里展示了每个城市招聘数据分析师最多的公司前5名。
df_clean.groupby('city').positionName.apply(topN)
数据分析有不同的侧重岗位,这里展示了每个城市具体需要数据分析哪些岗位的排名。高级数据分析师排名都比较靠后,说明目前我国各地区对数据分析师的需求还处于比较基础的前期发展阶段。
以上为较简单的页面抓取代码,之后可以尝试以下不同的情况:
- 比较不同招聘网页的爬取特征,拉勾、智联、等;
- 并发抓取;