多个优秀的OCR算法解读
算法1:ICCV2019 End-to-End Text Spotting
端到端任意形状的场景文字识别解读
这篇文章是谷歌发表再2019ICCV上面的一篇文章,主要解决了自然场景下任意形状的文字识别问题,而且是一种端到端的方法。
端到端文本识别(End-to-End Text Spotting)是将文本阅读问题看成一个整体来解决,其基本思想是设计一个同时具有检测单元和识别单元的模型,共享其中两者的CNN特征,并联合训练。在推断阶段,此端到端模型可以在一个前向传播中预测场景图像中的文本位置和内容信息。
一.原理简介
首先整体框架图如下图所示。
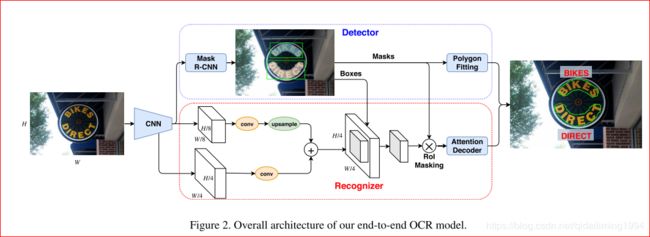
总体上,模型由3个单元和RoI Masking组成,3个单元分别是Backbone(CNN特征提取单元),Detector(检测单元),Recognizer(识别单元),其中RoI Masking是本文提出的Detector与Recognizer的一种交互模式。
1.在backbone模块中引入Atrous Convolutions使其有效的Output Stride为8,作用是提供Dense Feature的同时可以维持较大的Receptive Field,便于捕获自然场景中尺寸上有巨大变化的文本信息。这个Backbone产生的特征会共享给Detector和Recognizer作为其输入。
2.在检测单元这一部分中,作者采用了mask rcnn,作为了检测器,和mask rcnn不同的主要有两点:(1)在第二阶段的cls head是有无文本二分类,(2)与cls head相应,mask prediction head输出通道数是2,分别是background还是text分割的binary。
3.关于Recognizer,由于前述的RoI Masking并没有对特征进行矫正,故CTC-based方法并不适用,据此,作者借鉴了Bahdanau-style的Attention思路来识别文本,如Fig2所示。Recognizer的主要思想是由一个LSTM-Decoder来依次预测各个字符,直到预测类别为End-of-Sequence(EOS)才停止。其中,LSTM每个Step的输入是由上一个隐含层状态.Context Vector就是Attention机制的输出表征,其实质是Flattened Image Feature h的加权和
4.关于多尺度特征融合和RoI Masking,作者指出Stride 8的特征对于Text Detection是足够的,但对于Text Recognition这个较细粒度的任务则需要更密集的特征,因此,作者引入了多尺度特征融合的方法来加强输入到Recognizer的特征。具体来说,作者将Backbone中的Stride 8和Stride 4的特征按照Feature Pyramid Network[5]的思路进行了两个尺度的融合,可参考Fig1红色虚线框的前半部。另外,本文指出目前End-to-End识别方法存在的一个问题是Detector和Recognizer的交互模式,例如[6]和[8]中是分别使用了RoI Transforms和RoI Rotate去对Rotated Rectangles或Quadrilaterals的文本实例特征进行矫正,这样的交互模式对于直线文本情况是适用的,但往往会失效于曲线文本。因此,作者提出了新的交互模式RoI Masking,具体流程是先由Detector产生的Axis-aligned Bounding Box用来截取特征,然后将这些Cropped Out Feature和Instance Segmentation Mask(Inference阶段由Mask Branch预测得)相乘,最后经过Resize后再送到Attention Decoder中。此举目的是过滤相邻文本和背景信息,并免去对文本特征的矫正操作。本文指出RoI Masking可显著提高Recognizer的性能。
关于联合训练和损失函数,作者还观察到了目前End-to-End方法存在的另一个问题,也就是Recognizer在训练过程中往往需要远比Detector更多的数据和迭代次数,因此会出现的情况是,现有公开数据集想用来联合训练并得到一个高性能的Attention Decoder是显得不够大的,进一步说,即使通过训练足够长的时间来使Recognizer收敛,但Detector会存在过拟合的高风险。因此,作者通过增加一个部分标注的数据集(通过一个OCR引擎[2]来自动标注)来解决这问题,具体来说,训练过程中当样本是Fully Labeled时,Detector和Recognizer的权值都会更新,当样本是Partially Labeled时,则只有Recognizer被更新.
二.总结
本文模型中的Detector在MaskR-CNN]的基础上把其中的Classification Head从多分类改为Text/non-text的二分类,Mask Prediction Branch的输出也相应地调整2通道,分别为Text Mask和Non-text Mask,Masks经过Polygon的拟合得到最终的检测结果。也即,作者将mask rcnn修改为了一个简单、有效的纯检测器。然后,基于Detector产生的RoIs和Masks,作者提出了RoI Masking方法来为Recognizer提供准确的文本特征信息。而Recognizer则是基于Bahdanau-style[1]的Attention思路去构建的一个LSTM-Decoder,能依次选择相关的字符特征进行解码,直到预测的字符类别为EOS。
值得学习的一点是,本文模型是目前为止第一个可以在端到端训练策略中从部分标注的样本(借助现有OCR Engine)中收获性能增益的方法。
RoI Masking是本文方法的一个亮点。
关于和Mask TextSpotter的比较,本文和Mask TextSpotter相似的地方是两者模型都和Mask R-CNN关系很大,但不同的地方也很明显。可以概括为,Mask TextSpotter比较完整地继承了Mask R-CNN的思想,它将Mask Prediction Head用于字符分割,Global Word分割和Background分割,值得注意的是,既然Mask Head用于字符分割,即Mask Prediction Head也完成了Recognizer的功能,因为每个Character Mask的通道索引就代表着字符类别;而明显不同的是,本文模型只将Mask R-CNN修改为一个单纯的文本检测器(Detector),其Mask Prediction Head只负责分割出文本和非文本区域,而Recognizer则由独立于Mask R-CNN的Attention-decoder来担任,Detector输出的RoIs和Masks则用于为Recognizer提供准确的Text Instance Feature。另外,两个模型的Mask R-CNN模块中的Classification Head和Regression Head是一致的设计。
算法2:端到端文本检测与识别——FOTS
常见的深度学习OCR过程中,会把文本检测与文本识别拆分成两个部分,通过先检测后识别的方法对图片中的文本进行OCR识别。在商汤的paper中,一种新的端到端快速检测识别模型给了我们一个很大的惊喜。
1.整体的框架图
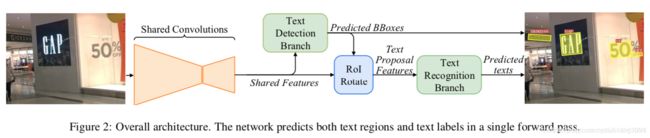
FOTS的整体结构由四部分组成。分别是:卷积共享特征(shared convolutions),文本检测分支(the text detection branch), RoIRotate操作(RoIRotate operation),文本识别分支(the text recognition branch)。
2.论文的主要贡献:
(1)提出了端到端的快速的文本检测+识别一体化的方案。
(2)提出了RoIRotate ,类似于roi pooling 和roi align,该操作主要池化带方向的文本区域,通过该操作可以实现将文本检测和文本识别端到端的连接起来。
(3)FOTS在公开数据集ICDAR 2015, ICDAR 2017 MLT,ICDAR 2013 上取得了state of the art的效果
算法3:TextBoxes++算法解析
- 从名字就可以看出,该文章是上面TextBoxes的一个扩展,扩展在TextBoxes只可以检测水平文本,而TextBoxes++可以检测多角度的文本,但该方法也是基于SSD结构且是针对词来检测的(word-based)。
- 不同于TextBoxes,为了更好的对多角度文本进行检测,文章做了三个改动,一是改了default box的宽高比,使用1、2、3、5、1/2、1/3、1/5;二是将15的卷积核改为35用来生成text box layers,三是网络的输出不同(这点会在ground truth中介绍)。框架与TextBoxes是一样的,如下图所示。
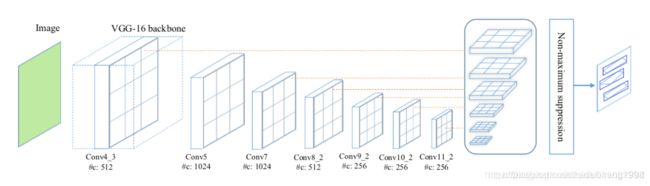
- 总结:
textboxes两种方法都是在SSD的基础上做修改,所以要理解SSD的相关思路相对SSD修改了default boxes的长宽比网络中最后一层采用1×5的conv,(考虑到文字比较长)default box在ssd的基础上加了垂直偏移,所以default box会是ssd的两倍textboxes++还是采用同样的default box生成策略修改了default box的宽高比预测输出的最后一层conv的卷积核改为了3×5网络的输出有两种形式,输出4个点,8个值的要好理解一些
算法4:PSENet文本检测算法
源码pytorch
代码TensorFlow版本
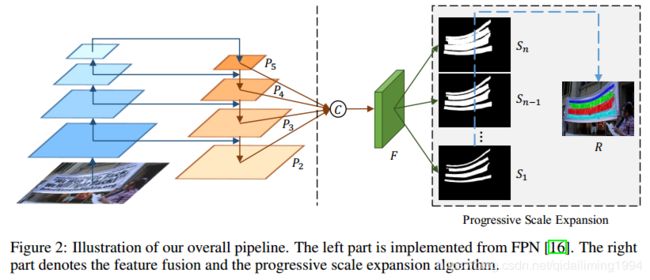
复现的论文神经网络部分使用的是tensorflow,广度优先搜索部分使用C++实现。
- 先从train.py开始看,103行定义了损失函数,在tower_loss函数中,构建了模型。模型的输出seg_maps是一个6通道的tensor,对应了论文中segmentation result。在train.py中没有引用到pse,pse在训练的过程中没有用到。
预测的过程在eval.py中。
# eval.py,第76行
def detect(seg_maps, timer, image_w, image_h, min_area_thresh=10, seg_map_thresh=0.9, ratio = 1)
-
其中,min_area_thresh是一个连通分量中至少有10个像素,seg_map_thresh是在返回的seg_map中,0.9以下的被变成0,以上的变为1,以此将seg_map变成二值图。在论文中出现的kernel就是图中变成1的部分。在detect函数中,调用了pse,这部分是使用C++实现的。python中调用C++使用了pybind11。
-
pse文件夹中包含了pse的实现。其中include目录是pybind11的开源代码。广度优先的过程都在pse.cpp中。
在pse/init,py中队pse.cpp进行了编译。 -
pybind11中,规定PYBIND!!_MODULE作为一个接口,写在C++文件中,编译的时候会将函数与python中的函数绑定。
-
第一个pse_cpp是python中绑定的函数名,第二个&pse::pse是在C++文件中待绑定的函数py::arg声明了参数以及默认值。在pse::pse中实现了一个广度优先搜索。init.py中,对pse进行了一次封装。
cv2.connectedComponents对模型求出来的最后一个kernel求了一次连通分量。label_num是图中连通分量的个数,label是带有标签的图,如果在连通分量里面,那个像素的值就是对应的连通分量编号,否则就是0。
接下来的for循环将小于10个像素的连通分量删除。 -
读取标注的函数是data_provider.py中的load_annotation,在第280行调用了这个函数,这个函数就是读取标记用的,如果要兼容别的数据集需要修改这个函数。返回值text_polys是一个三维数组
-
在generage_seg函数中,调用了函数shrink_poly这个函数用来将ground_truth进行不同比例的缩小
-
其中endpoints是resnet中几个特征图。然后讲feature_pyramid进行concat,由于每一层的feature_pyramid的大小不一定一样,所以需要先进行缩放(unpool函数)然后经过两个卷积层,得到seg_S_pred
算法5:云从科技的Pixel-Anchor论文解读
目前基于深度学习的文本检测框架可以分为两类,一类是基于像素级别的图像语义分割,另一类是来源于通用的物体检测框架,譬如基于锚 (anchor) 的检测和回归。
基于像素分割的文本检测框架首先通过图像语义分割获得可能的文本像素,之后通过像素点直接回归或者对文本像素的聚合得到最终的文本定位;而基于锚检测回归的文本检测框架是在通用物体检测的基础之上,通过设置更多不同长宽比的锚来适应文本变长的特性,以达到文本定位的效果。
基于像素分割的文本检测往往具有更好的精确度,但是对于小尺度的文本,因为适用的文本像素过于稀疏,检出率通常不高,除非以牺牲检测效率为代价对输入图像进行大尺度的放大;基于锚检测回归的文本检测对文本尺度本身不敏感,对小文本的检出率高,但是对于大角度的密集文本块,锚匹配的方式会不可避免的陷入无法适从的矛盾之中,此外,由于这种方法是基于文本整体的粗粒度特征,而并不是基于像素级别的精细特征,它的检测精度往往不如基于像素分割的文本检测。对于中文这样文本长度跨度很大的语言,目前的这两种方法在长文本上的效果都不尽人意。
这是一种端到端的深度学习文本检测框架Pixel-Anchor,通过特征共享的方式高效的把像素级别的图像语义分割和锚检测回归放入一个网络之中,把像素分割结果转换为锚检测回归过程中的一种注意力机制,使得锚检测回归的方法在获得高检出率的同时,也获得高精确度。此外,对于如中文这样文本长度跨度很大的语言,在Pixel-Anchor中,提出了一个自适应的预测层,针对不同层级的特征所对应的感受野范围,设计不同的锚以及锚的空间位置分布,以更高的效率更好的适应变化的文本长度。
一. pixel-anchor针对east部分的改进-pixel
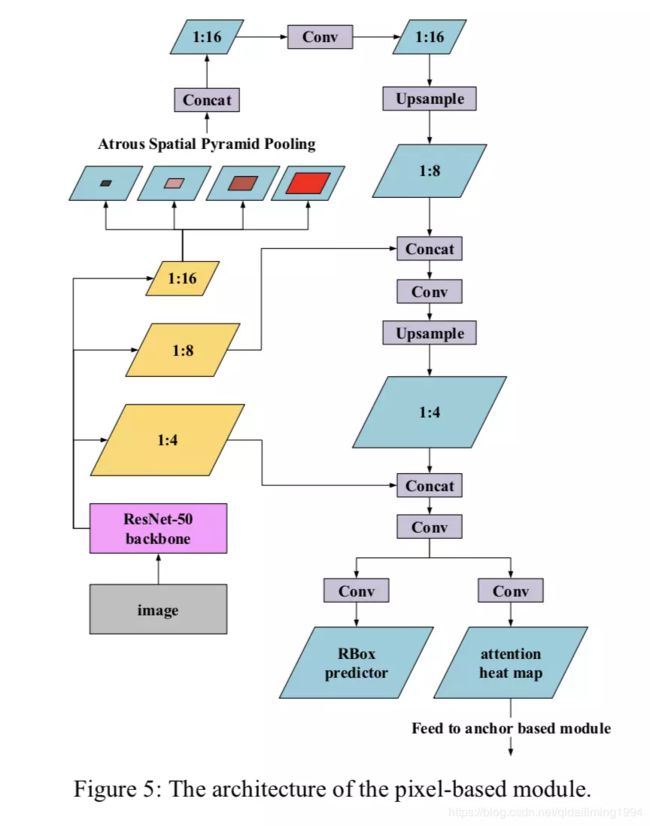
针对EAST的改进,文章延续FOTS对EAST的改进,
以下插件:ASPP OHEM:对分类和回归。
ASPP来自deeplab中,其主要作用是在不降低feature map分辨率的情况下,提升网络的感受野,即可以提升模型获取上下文信息的能力。它会带来什么效果呢?
首先,是分割效果更为精准。分割一个物体,网络往往借助的是该物体周围的信息,比如,分割前景,我们需要找到背景信息;当感受野变大时,对于较长的文本或者较大的文本,可以很好的找到其边界,进而分割出较高质量的文本区域;其次,感受野的提升,会使得回归距离变长。即geo_map中的值表示,当前像素到四条边的距离。而网络建立起当前像素与边界之间的距离关系。当上下文信息充足时,可以准确的建立起距离关系,进而边界预测足够精准。因此文章加入ASPP的作用主要是以上两点,分割精准+边界定位精准。
OHEM常用来进行困难样本挖掘。对于文字区域的分割,存在样本的不平衡,文字区域往往占比比较小,背景占比比较大。同时,对于一张图中的多个文本,小的文本区域的损失往往被大文本区域损失覆盖;而且还有一种情况,背景中存在难以区分的样本,这些背景容易导致模型将类似的文本区域分为背景。因此加入OHEM,可以对这部分背景信息进行挖掘,同时在训练过程中正负样本进行均衡,避免了类别不均衡的问题。以上就是该文章对EAST部分的改进。其实OHEM来自FOTS对EAST的改进,ASPP在此之前已经尝试过,确实会带来边界预测的提升。对于这部分EAST,除了预测以往的文本区域的score_map和geo_map, 同时预测一张attention map用于对anchor-based分支的信息的辅助。
二.pixel-anchor针对SSD部分的改进-anchor
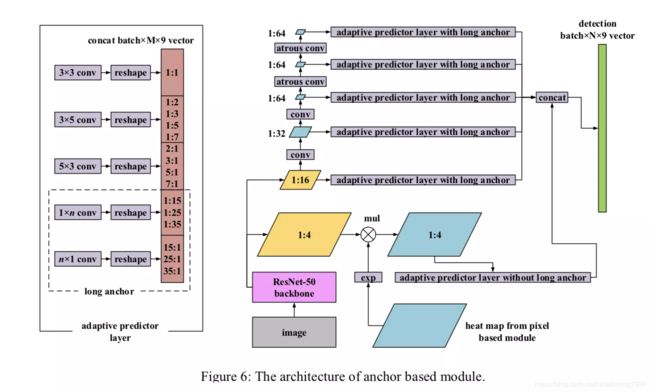
文章在EAST的基础上,加入了anchor-based检测分支,主要针对文字尺度以及宽高比较大的变化,文章对SSD进行了定制。如上面右图所示。文章主要利用来自ResNet50中的1/4和1/16的feature map:对于1/4的map,由于其处于底层,因此具有一定的分辨率,对于检测较小的文字具有一定优势。同时由于此处的特征语义信息较弱,文章将east分支得到的attention map用在此处,主要为了对该层加入一定的语义信息。具体操作为,对来自east的attention map输出进行exp激活,然后与1/4 feature map进行对应位置的加权。这么做的好处是,对1/4feature map上的信息,属于文本的像素进行加强,对于不属于文本的像素进行抑制,突出文本信息。文章说,这么做可以很大程度的减少错误检测。这里需要解释下为什么anchor-based的方法检测小目标会出现较高的fp.原因在于,在较高分辨率的feature map上生成proposals时,由于像素点比较多,目标较小,因此整张图中网格都处于负样本区域,极少数网格落在正样本区域。这样在预测是,负样本较正样本多,而且负样本的方差较大,因此容易导致分类的错误,因此容易出现fp.对于1/16的map,文章进一步的进行特征提取,一是为了获得更大的感受野,二是为了获得多尺度的信息。分别为1/32. 1/64, 1/64, 1/64。但是为了避免出现很小的feature map,文章在后面的feature map保持在1/64。但为了继续提升感受野,文章在后面两个尺度的的生成时,加入了空洞卷积,在分辨率不减小的情况下,获得较大感受野。对于每一层的feature map,文章在其后加入APL层,层中内容如上图右图中的左半部分所示,分别为不同的卷积核搭配不同的宽高比,实现对不同尺度,不同角度的文本的cover.如3x3为方框,3x5主要为了检测水平倾斜的文字,5x3为了检测垂直倾斜的文字。1xn,nx1主要为了检测水平和竖排长行的文字。可以看到有夸张的1:35,35:1的宽高比,这在中文场景是很常见的。在经过以上APL层之后,将得到的proposal进行拼接,预测最终搞得四边形区域。