python数据分析与挖掘实战---基于水色图像的水质评价(混淆矩阵和学习曲线)
1. 数据
下载地址: https://download.csdn.net/download/qq_26645205/10432463
2. 模型构建
抽取80%作为训练样本,剩下20%作为测试样本
此案例是《python数据分析与数据挖掘》的第九章,在p200我们可以看到特征的取值范围都在0~1之间,换句话说,如果我们直接输入SVM模型的话,彼此之间的区分度会比较小,因此我们需要做一个放大处理,当然放大系数K不能过大或者过小,经反复试验,我们发现30时,效果比较好。
代码如下:
import pandas as pd
inputfile ='chapter9/demo/data/moment.csv'
data =pd.read_csv(inputfile,encoding='gbk') #读取数据,指定编码
data=data.as_matrix()
from random import shuffle #引入随机函数
## shuffle(data) #随机打乱数据 **这样直接写有问题**
#用下面的方式
num_example=data.shape[0]
print (num_example)
arr=np.arange(num_example)
np.random.shuffle(arr)
data=data[arr]
data_train= data[:int(0.8*len(data)),:] #选取前80%为训练数据
data_test=data[int(0.8*len(data)):,:] #选取前20%为测试数据
#导入模型相关的函数,建立并且训练模型
from sklearn import svm
model= svm.SVC()
model.fit(x_train,y_train)
import pickle
pickle.dump(model,open('chapter9/demo/tmp/model','wb'))
#根据模型进行评分
model.score(x_test, y_test)
#保存结果 混淆矩阵
pd.DataFrame(cm_train, index = range(1, 6), columns = range(1, 6)).to_csv(outputfile1)
pd.DataFrame(cm_test, index = range(1, 6), columns = range(1, 6)).to_csv(outputfile2)3. 混淆矩阵
在机器学习领域,混淆矩阵(confusion matrix),又称为可能性表格或是错误矩阵。它是一种特定的矩阵用来呈现算法性能的可视化效果,通常是监督学习(非监督学习,通常用匹配矩阵:matching matrix)。其每一列代表预测值,每一行代表的是实际的类别。这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class)。
Example
假设有一个用来对猫(cats)、狗(dogs)、兔子(rabbits)进行分类的系统,混淆矩阵就是为了进一步分析性能而对该算法测试结果做出的总结。假设总共有 27 只动物:8只猫, 6条狗, 13只兔子。结果的混淆矩阵如下图:
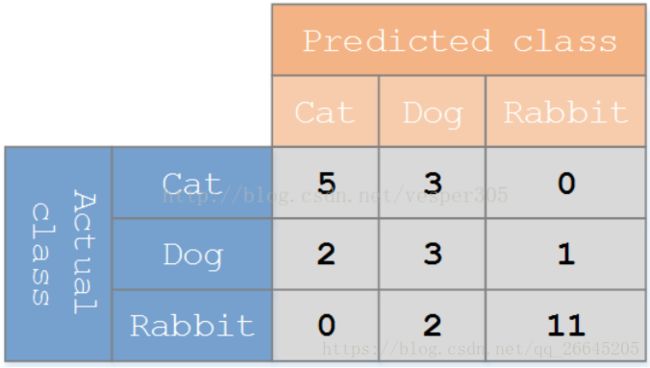
在这个混淆矩阵中,实际有 8只猫,但是系统将其中3只预测成了狗;对于 6条狗,其中有 1条被预测成了兔子,2条被预测成了猫。从混淆矩阵中我们可以看出系统对于区分猫和狗存在一些问题,但是区分兔子和其他动物的效果还是不错的。所有正确的预测结果都在对角线上,所以从混淆矩阵中可以很方便直观的看出哪里有错误,因为他们呈现在对角线外面。
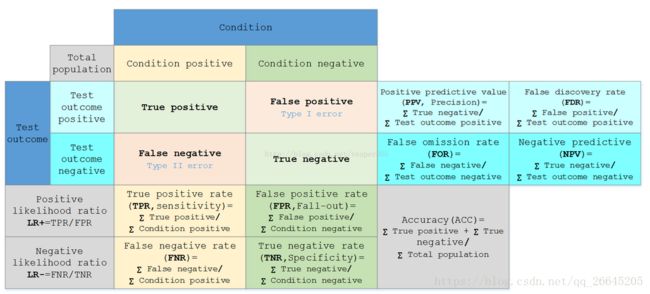
在预测分析中,混淆表格(有时候也称为混淆矩阵),是由false positives,falsenegatives,true positives和true negatives组成的两行两列的表格。它允许我们做出更多的分析,而不仅仅是局限在正确率。准确率对于分类器的性能分析来说,并不是一个很好地衡量指标,因为如果数据集不平衡(每一类的数据样本数量相差太大),很可能会出现误导性的结果。例如,如果在一个数据集中有95只猫,但是只有5条狗,那么某些分类器很可能偏向于将所有的样本预测成猫。整体准确率为95%,但是实际上该分类器对猫的识别率是100%,而对狗的识别率是0%。
对于上面的混淆矩阵,其对应的对猫这个类别的混淆表格如下:

假定一个实验有 P个positive实例,在某些条件下有 N 个negative实例。那么上面这四个输出可以用下面的偶然性表格(或混淆矩阵)来表示
利用数据得到训练数据和测试数据的混淆矩阵为:
训练数据:

测试数据:
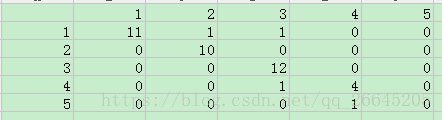
总类别:

可以看出列为预测值,行为实际值。
对角线的值为预测准确的个数,
训练样本进行回判,得到混淆矩阵,分类准确率为37+34+66+17+3=157/162=96.91%
测试样本,进行回判,得到混淆矩阵,分类准确率为11+10+12+4=37/41=90.24%
画混淆矩阵图
import matplotlib.pyplot as plt #导入作图库
get_ipython().magic(u'matplotlib inline')
plt.matshow(cm_test, cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。
plt.colorbar() #颜色标签
for x in range(len(cm_test)): #数据标签
for y in range(len(cm_test)):
plt.annotate(cm_test[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label') #坐标轴标签
plt.xlabel('Predicted label') #坐标轴标签
plt.show()4. 学习曲线
import numpy as np
import matplotlib.pyplot as plt
from sklearn.learning_curve import learning_curve
import sys
reload(sys)
sys.setdefaultencoding('utf8')
plt.rcParams['font.sans-serif'] =['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
# 用sklearn的learning_curve得到training_score和cv_score,使用matplotlib画出learning curve
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1,
train_sizes=np.linspace(.05, 1., 20), verbose=0, plot=True):
"""
画出data在某模型上的learning curve.
参数解释
----------
estimator : 你用的分类器。
title : 表格的标题。
X : 输入的feature,numpy类型
y : 输入的target vector
ylim : tuple格式的(ymin, ymax), 设定图像中纵坐标的最低点和最高点
cv : 做cross-validation的时候,数据分成的份数,其中一份作为cv集,其余n-1份作为training(默认为3份)
n_jobs : 并行的的任务数(默认1)
"""
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, verbose=verbose)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
if plot:
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel(u"训练样本数")
plt.ylabel(u"得分")
plt.gca().invert_yaxis()
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std,
alpha=0.1, color="b")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std,
alpha=0.1, color="r")
plt.plot(train_sizes, train_scores_mean, 'o-', color="b", label=u"训练集上得分")
plt.plot(train_sizes, test_scores_mean, 'o-', color="r", label=u"交叉验证集上得分")
plt.legend(loc="best")
plt.draw()
plt.gca().invert_yaxis()
plt.show()
midpoint = ((train_scores_mean[-1] + train_scores_std[-1]) + (test_scores_mean[-1] - test_scores_std[-1])) / 2
diff = (train_scores_mean[-1] + train_scores_std[-1]) - (test_scores_mean[-1] - test_scores_std[-1])
return midpoint, diff
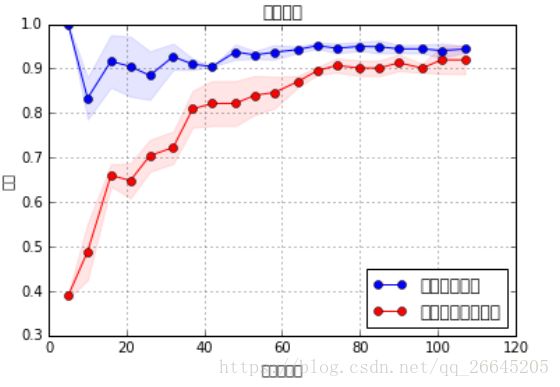
plot_learning_curve(model, u"学习曲线", x_train, y_train)不知道为什么中文显示不出来
参考:
1.https://blog.csdn.net/vesper305/article/details/44927047 (混淆矩阵)